- The paper introduces behavior descriptions as concise, human-understandable statements summarizing AI performance on specific data subgroups to mitigate over- or under-reliance.
- It uses controlled experiments across tasks like fake review detection and bird species classification, showing statistically significant improvements in team accuracy.
- The findings reveal that refining mental models through BDs enhances strategic error correction, though the benefits vary by task and do not necessarily boost subjective trust.
Improving Human-AI Collaboration with Descriptions of AI Behavior
Introduction and Motivation
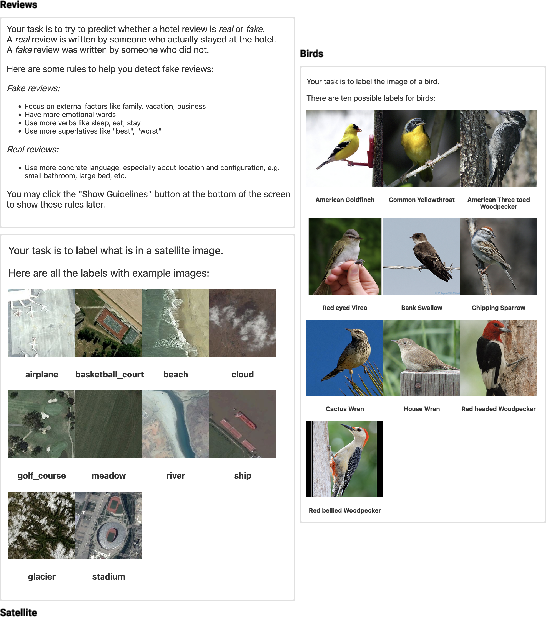
AI systems are increasingly deployed as decision aids in expert and non-expert domains, yet leveraging their outputs effectively remains a significant challenge. Human collaborators often under- or over-rely on model predictions, sometimes resulting in lower team performance than either the human or the AI alone. This issue is rooted in incomplete or inaccurate user mental models of system capabilities and failure modes. To address this, the paper introduces “behavior descriptions” (BDs): human-understandable statements about how AI systems perform on semantically meaningful subgroups of instances, such as “the classifier is only 20% accurate for reviews containing more than three exclamation marks.”
The underlying hypothesis is that exposing users to such BDs can refine or calibrate their mental models (see (Figure 1)), enabling more appropriate reliance on the AI—using it when it is most accurate, and overriding it when systematic errors are likely.

Figure 1: Don Norman's mental model framework. Developers derive BDs from testing and analysis, which are then communicated to end-users to help them work more effectively with opaque, learned AI models.
Experimental Design and Methodology
The efficacy of BDs was assessed through a controlled, between-subjects experiment involving 225 participants across three tasks: fake review detection (text, binary), satellite image classification (image, multiclass), and bird species classification (image, multiclass). Each task reflected varying data types and differences in AI-vs-human baseline accuracies.
Participants were randomly assigned to one of three conditions:
- No AI: Manual labeling only.
- AI: Shown model predictions with a stated 90% accuracy.
- AI + BD: AI predictions as above, plus explicit BDs for semantically defined subgroups (covering 10/30 instances per user).
Performance evaluation controlled exposure to AI errors by using a Wizard-of-Oz setup, standardizing the number of AI misclassifications per group and per participant (see (Figure 2)).

Figure 2: Experimental setup showing assignment to condition and systematic exposure to instance subgroups with controlled AI error rates.
The user interface presented output and, where appropriate, BDs in clearly demarcated panels tied to each instance group (see (Figure 3)).
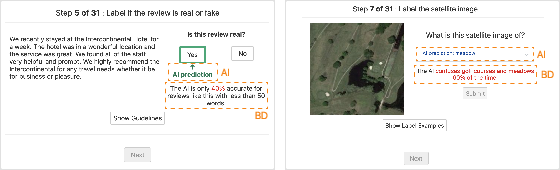
Figure 3: UI screenshots for fake review (left) and satellite image (right) tasks, highlighting how AI predictions and BDs were presented.
BDs took the form of concise, actionable statements about subgroup accuracy or confusion, designed to adhere to three principles: actionability, simplicity, and significance (i.e., focus on impactful or frequent failures).
Key Empirical Findings
The introduction of BDs improved human-AI team accuracy in two out of three tasks (fake reviews, birds), with statistical significance for improvements in reviews (p<0.001) and birds (p=0.023) (see (Figure 4)). Notably, in the birds task, BD-equipped teams achieved complementarity—accuracy exceeding both human- and AI-alone baselines. No significant benefit was observed in satellite classification, attributed to high baseline human proficiency.

Figure 4: Average participant accuracy by task and condition, with blue region indicating complementarity and orange bar showing AI baseline accuracy.
Further analysis disclosed two mechanisms for BD-driven improvement:
- Direct error correction: Users overrode model predictions in the explicitly described (low accuracy) subgroups.
- Generalized increased reliance: Users more frequently deferred to the AI outside described weak spots, based on a refined understanding of error locality.
However, BD impact on explicit subgroup corrections was variable across tasks/subgroups (see (Figure 5)). In some cases, accurate mental models were necessary, but not always sufficient: users also needed actionable alternative strategies when informed of model errors.
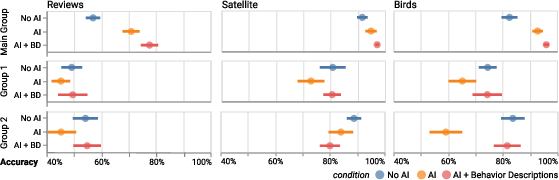
Figure 5: Accuracy stratified by task, condition, and subgroup, highlighting the nuanced impact of BDs on both direct error correction and overall reliance patterns.
Learning Effects and User Perceptions
Learning curve analyses (see (Figure 6)) showed that where BDs had a significant impact, they also accelerated user adaptation over repeated rounds; participants in BD conditions optimized their strategies more rapidly than those with AI-only assistance.

Figure 6: Learning curves by task and condition. Statistically significant learning effects appear in tasks where BDs substantially improve performance.
Surprisingly, there were no significant differences between AI and AI+BD groups in self-reported trust, helpfulness, or intent-to-use metrics (see (Figure 7)), suggesting that BD-driven improvements are not subjectively salient to users, or at least not reflected in standard post-task survey instruments.
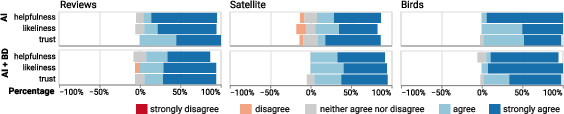
Figure 7: Likert-scale responses, showing no significant impact of BD exposure on self-reported trust or perceived helpfulness of the AI.
Practical Insights and Limitations
Design and Authoring of Behavior Descriptions
BDs are actionable interventions for mitigating the performance risk of unfixable or slow-to-fix AI misbehavior, especially in domains where labeled data deficits or model update constraints are substantial. Existing model analysis toolkits (e.g., FairVis, Slice Finder) can assist in surfacing candidate BDs, but purpose-built, user-facing tools could further optimize BD selection and presentation to maximize actionability and minimize cognitive load.
The creation of BDs is inherently iterative and sociotechnical, potentially involving not only developers but also QA teams and even end-users (crowdsourced failure reporting and BD authoring). As models evolve, curating up-to-date, significant, and easily internalized BDs is essential to maintaining alignment between system behavior and user mental models—crucial for ML deployment in safety-critical or regulated domains.
Boundary Cases and Theoretical Implications
Several important boundaries emerged:
Implications and Future Directions
Behavior Descriptions address one of the central challenges of Human-AI collaboration: communicating the boundary between system competence and failure in operationally meaningful terms. Unlike post-hoc explainability methods (e.g., LIME, SHAP), which seek to explain specific decisions, BDs directly address aggregate or systematic failure regimes—effectively shifting the focus from "why?" to "when and where?".
Future research should explore:
- BD design for more complex tasks (structured prediction, language generation, etc.)
- Automated, data-driven BD discovery, surfacing both failure and “high confidence” regions
- User-adaptive BD presentation incorporating learning, cognitive load, and alert fatigue
- Integration of BD reporting and user-driven feedback loops for AI system lifecycle management
Conclusion
This work provides systematic empirical evidence that BDs—simple, significant, and actionable summaries of AI weaknesses—can be an effective, low-overhead tool for improving decision quality in human-AI teams across multiple domains and modalities. The paper demonstrates that refining users’ mental models using transparent, subgroup-targeted behavior communications supports both direct error correction and more appropriate reliance, sometimes yielding true human-AI complementarity. It establishes BDs as a promising complement to explainability methods, incentive structures, and continuous model improvement in the design and deployment of trustworthy AI systems.