- The paper introduces MNA-GT, a novel Transformer architecture that utilizes adaptive multi-neighborhood attention to integrate diverse structural information in graphs.
- It overcomes traditional GNN limitations like over-smoothing by employing multiple attention kernels based on different neighborhood hops.
- Empirical results show that MNA-GT outperforms standard GNNs on graph classification tasks while maintaining comparable parameter efficiency.
The paper presents the Adaptive Multi-Neighborhood Attention based Transformer (MNA-GT), a novel architecture designed for graph representation learning by incorporating multiple-scale structural information into the Transformer framework. MNA-GT achieves this through the utilization of multi-neighborhood attention which allows it to adaptively integrate diverse structural information across various nodes in a graph.
Motivation and Context
Traditional GNNs suffer from inherent limitations like over-smoothing and over-squashing due to their reliance on message-passing mechanisms which sequentially propagate node features. These limitations restrict the expressive power of GNNs for capturing complex graph structures. Although recent efforts have integrated Transformer architectures into graph representation learning by defining structural biases and enriching inputs, these methods typically rely on fixed strategies that fail to adapt to diverse structures across different graphs.
In contrast, MNA-GT introduces a flexible, attention-based mechanism for graph structural learning. By adapting the self-attention mechanism of Transformers to consider multiple neighborhoods, it overcomes the limitations of encoding graph information via static rules.
Architecture Overview
The core innovation in MNA-GT is the multi-neighborhood attention mechanism, which constructs multiple attention kernels based on different hop neighborhoods.
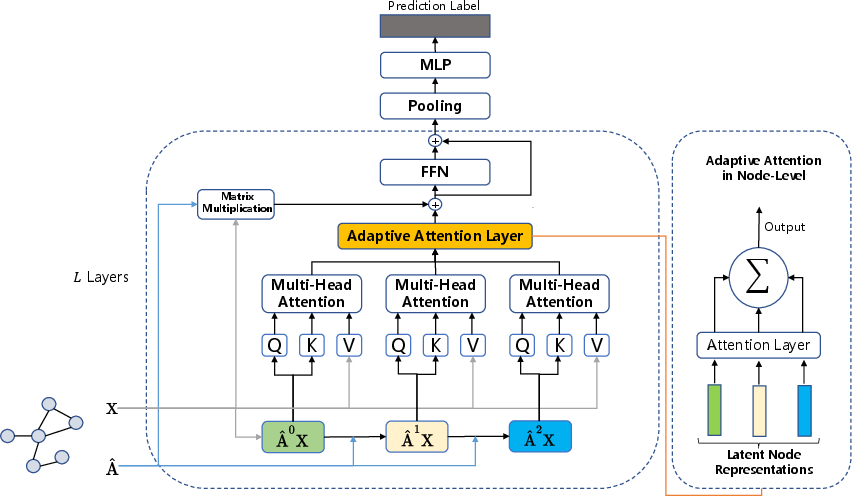
Figure 1: The architecture of MNA-GT with three attention kernels. MNA-GT first constructs three attention kernels based on the corresponding neighborhoods. With each attention kernel independently performing multi-head attention, MNA-GT can efficiently preserve different structural information encoded by different neighborhoods. MNA-GT further utilizes an attention layer to adaptively aggregate the hidden representations for various nodes. Finally, a pooling layer and a multi-layer perceptron are adopted for downstream graph classification tasks.
Key Components
- Attention Kernels: Each kernel is based on a different neighborhood hop, providing varied levels of structural granularity. The sets of propagation steps define the neighborhood scope, allowing each kernel to learn specific structural hierarchies.
- Adaptive Attention Module: By applying a secondary attention mechanism over the outputs from multiple kernels, MNA-GT adaptively weights the importance of various neighborhood scales for each node, generating flexible node embeddings.
- Integration with Transformers: By preserving both global and local neighborhood contexts, MNA-GT leverages the multi-head attention framework of Transformers to generate rich node representations before downstream pooling operations.
Implementation Considerations
Parameter Sensitivity
- Propagation Steps: Choosing the right number of neighborhood layers is crucial. Excess layers can introduce redundancy, while too few can under-represent complex structures. The experimental section shows that three kernels (k=3) usually strike a balance between performance and complexity.
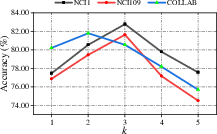
Figure 2: Parameter sensitivity on the propagation step.
- Multi-head Attention: While more heads theoretically improve the model's capacity to learn from diverse subspaces, increasing the number of heads beyond three offered marginal gains.
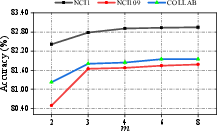
Figure 3: Parameter sensitivity on the number of heads.
- Network Depth: Deep MNA-GT models yield diminishing returns, with overfitting observed past certain depths, particularly evident with smaller datasets. The selection of layer count (L=3 or $4$) is generally optimal.
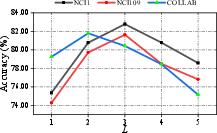
Figure 4: Parameter sensitivity on the number of network layers.
Empirical Results
Experiments demonstrate that MNA-GT generally outperforms both traditional GNNs and recent graph Transformers across several datasets, including TUDatasets and the Open Graph Benchmark suite. The ablation studies highlight the necessity of the adaptive attention module, showing enhancements over basic aggregation methods like sum or average pooling.
Additionally, MNA-GT's performance remains competitive with a parameter scale comparable to that of baseline models, benefiting from efficient multi-head and multi-scale constructions tailored to the graph's inherent structure variations.
Conclusion
By introducing adaptive multi-neighborhood attention, MNA-GT represents a significant advancement in Transformer-based graph representation learning, capable of dynamically capturing and integrating multi-scale structural information. Its flexible, kernel-based approach allows it to outperform existing methods, setting a new benchmark for accuracy and efficiency in diverse graph classification tasks. Future work might extend this framework by exploring more sophisticated or hierarchical neighborhood sampling strategies to further enhance performance and scalability.