Subword Segmental Language Modelling for Nguni Languages
Abstract: Subwords have become the standard units of text in NLP, enabling efficient open-vocabulary models. With algorithms like byte-pair encoding (BPE), subword segmentation is viewed as a preprocessing step applied to the corpus before training. This can lead to sub-optimal segmentations for low-resource languages with complex morphologies. We propose a subword segmental LLM (SSLM) that learns how to segment words while being trained for autoregressive language modelling. By unifying subword segmentation and language modelling, our model learns subwords that optimise LM performance. We train our model on the 4 Nguni languages of South Africa. These are low-resource agglutinative languages, so subword information is critical. As an LM, SSLM outperforms existing approaches such as BPE-based models on average across the 4 languages. Furthermore, it outperforms standard subword segmenters on unsupervised morphological segmentation. We also train our model as a word-level sequence model, resulting in an unsupervised morphological segmenter that outperforms existing methods by a large margin for all 4 languages. Our results show that learning subword segmentation is an effective alternative to existing subword segmenters, enabling the model to discover morpheme-like subwords that improve its LM capabilities.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper shows a new way for computers to read and predict text in four South African languages (isiXhosa, isiZulu, isiNdebele, and Siswati). These languages build words by sticking small meaning-pieces together (like Lego), so figuring out where the pieces go inside a word really matters. The authors create a model that learns how to split words into useful pieces at the same time as it learns to predict the next part of a sentence. This makes the model better at both understanding and generating the languages.
What questions the paper tries to answer
- Can a LLM learn the best way to chop words into smaller pieces (subwords) by itself, instead of using a fixed, one-size-fits-all splitter?
- Does learning word pieces during training help the model predict text better in low-resource, complex languages?
- Will the pieces the model discovers match real linguistic pieces (morphemes) that carry meaning?
How the method works (explained with everyday ideas)
Many language tools first cut words into subwords using rules or statistics (like BPE or unigram models) before training. That’s like pre-cutting all your Lego bricks into shapes you hope are useful for every building you’ll make.
The new model—called a Subword Segmental LLM (SSLM)—doesn’t accept those pre-cuts. Instead, it learns where to cut while it learns to read. Think of it as:
- A “favorite pieces” box (a lexicon) of common chunks it has seen before.
- A careful speller that can build a chunk letter by letter when the favorite pieces don’t fit.
- A smart switch that decides, for each chunk, whether to grab a piece from the box or spell it out.
To handle all the ways a word could be split, the model uses a fast planning trick (dynamic programming) that efficiently adds up scores for all possible cuttings without checking them one by one.
The model is trained on real text from the four Nguni languages. It’s tested in two ways:
- As a LLM: how well it predicts text (using a score called bits-per-character; lower is better).
- As a segmenter: how well its chunks match true morphemes (the smallest meaning units), without any human-provided examples (“unsupervised”).
They also try a simpler “word-level” version of the model that looks at one word at a time (no sentence context) to focus purely on splitting words into morphemes.
What they found and why it matters
- Better text prediction: On average across all four languages, the SSLM predicted text better than models that relied on fixed subword methods (characters only, BPE, or unigram subwords), especially in low-data settings. This suggests that learning the cuts on the fly helps the model use pieces that actually improve prediction.
- More morpheme-like pieces: The SSLM’s word splits matched real morphemes better than standard subword tools (BPE and unigram). The “word-level” version did even better and beat well-known unsupervised tools (like Morfessor) by a large margin across all four languages.
- Consistency across languages: While older methods often needed per-language fine-tuning and gave mixed results, the SSLM worked more reliably across the four languages.
- Practical tips: A small “favorite pieces” box (lexicon) and reasonable maximum piece length helped performance. The model tended to over-split in some cases (predicting too many boundaries), which is common when training data is limited.
Why this matters: For languages with complex word structure and not much data, it’s crucial to handle rare or unseen words. Learning the best subwords directly during training helps the model generalize, understand meaning better, and use the pieces that actually help with prediction.
What this could change going forward
- Better tools for low-resource languages: This approach can make language tech (like text prediction or generation) more accurate for languages with rich morphology and limited data, supporting inclusion and better digital tools.
- Smarter subwords for other tasks: The idea of learning subwords during training could be added to other systems (like translation or speech recognition), potentially improving them too.
- Linguistically helpful models: Because the learned pieces resemble real morphemes, the method could aid linguistic analysis or help build other tools (like spellcheckers or analyzers) for under-resourced languages.
In short: Instead of forcing a model to use pre-chosen word pieces, letting it learn where to split words while it learns to read makes it better at both tasks—especially for languages where the shape of words carries a lot of meaning.
Knowledge Gaps
Below is a concise list of concrete knowledge gaps, limitations, and open questions that remain unresolved in the paper. These highlight where further research and evaluation are needed.
- Generalization beyond Nguni: Validate SSLM on languages with different morphological typologies (e.g., fusional, templatic, polysynthetic) and scripts (including languages without whitespace).
- Disjunctive orthographies: Assess how SSLM adapts to disjunctively written agglutinative languages (e.g., Sotho-Tswana), where morphemes are often separated as orthographic words.
- Downstream impact: Conduct extrinsic evaluations (e.g., MT, ASR, POS/morphological tagging, text generation) to determine whether SSLM’s LM gains and segmentation translate into task-level improvements.
- Tokenization-free baselines: Compare against byte/character-only tokenization-free models (e.g., CANINE, ByT5) on the same corpora to isolate the added value of learned segmentation.
- Supervised/weakly-supervised segmentation baselines: Include stronger or alternative baselines (e.g., Morfessor FlatCat, Bayesian models, neural semi-supervised segmenters, rule-augmented analyzers) to contextualize SSLM’s segmentation performance.
- Human evaluation: Complement MI/MBI with human judgments of linguistic plausibility and usefulness of segments in real tasks.
- Statistical significance: Report statistical tests for BPC and segmentation improvements to confirm that gains are robust rather than within noise.
- Domain robustness: Test SSLM under domain shift (e.g., news, social media) given that training data are largely government publications.
- Code-switching and noise: Quantify SSLM’s robustness to code-switching and multilingual contamination present in the web-sourced corpora.
- OOV and rare-word analysis: Evaluate segmentation and prediction on unseen/rare words and measure error patterns by frequency bins.
- Joint objective tuning: Explore multi-objective training or regularization that explicitly balances LM performance and segmentation quality to mitigate SSLM over-segmentation.
- Bi-directional context: Investigate bi-directional or masked segmental LMs for segmentation, given morphological boundaries may benefit from future context.
- Segment length bias control: Examine alternative priors (e.g., MDL, Pitman–Yor, length penalties) beyond the tested length regularization to reduce over-segmentation without harming LM quality.
- Lexicon learning: Replace frequency-selected, fixed lexicons with end-to-end learned or dynamically updated lexicons (e.g., neural memory, adaptive dictionary growth/shrinkage).
- Lexicon selection criteria: Compare frequency-based lexicon construction with information-theoretic criteria (mutual information, branching entropy) or morphology-aware heuristics.
- Gating behavior analysis: Analyze when the model prefers lexicon vs character generation (as a function of word frequency, affix/stem position, morpheme type), and whether gating calibration improves segmentation.
- Architecture breadth: Explore segmental Transformers or hybrid encoders compatible with DP, including streaming/memory mechanisms for rich context representations.
- Complexity and efficiency: Provide formal and empirical complexity analysis of training/inference with respect to lexicon size V, max segment length L, and sequence length; profile latency and memory vs baselines.
- Hyperparameter transfer: Automate lexicon size and max segment length selection across languages (e.g., via Bayesian optimization or meta-learning) to avoid per-language manual tuning.
- Cross-lingual training: Test multilingual or multi-task setups (shared parameters or lexicons) to leverage related languages and reduce data sparsity.
- Data scaling laws: Systematically study how SSLM’s LM and segmentation performance scale with data size and whether over-segmentation diminishes with more training data.
- Entropy fusion: Combine entropy-based boundary cues with SSLM (e.g., as additional features or auxiliary losses) to close the gap with strong entropy segmenters on F1.
- Error typology: Conduct fine-grained segmentation error analysis (prefix/stem/suffix errors, 1-char morphemes, affix stacking) to guide targeted model refinements.
- Canonical-to-surface mapping noise: Quantify how heuristic mapping from canonical to surface segmentations affects evaluation and conclusions.
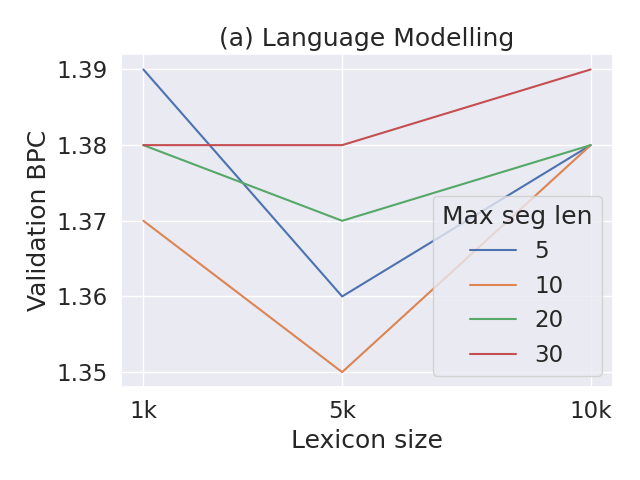
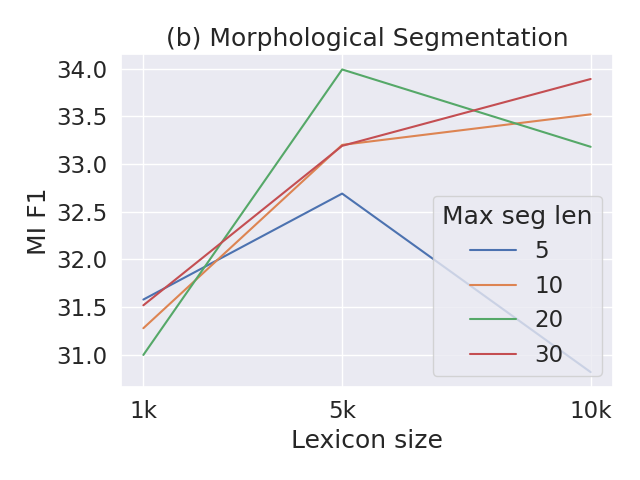
- Max segment length sensitivity: Extend the lexicon length/size ablation beyond isiNdebele to all languages and characterize stability/variance across settings.
- Morpheme category discovery: Investigate whether SSLM can induce morpheme categories/tags (prefix/stem/suffix) and paradigmatic structure, not only boundaries.
- Out-of-domain segmentation quality: Measure segmentation transfer from LM-trained domains to morphological test sets and explore domain adaptation techniques.
- Semi-supervised signals: Evaluate whether small amounts of labeled morphological boundaries or constraints improve SSLM without sacrificing LM quality.
- Cross-boundary segmentation: Explore learning of higher-level segmentation (e.g., clitics or multi-word expressions), currently excluded by the within-word segmentation assumption.
- Byte-level modeling: Assess whether byte-level SSLMs help with diacritics, Unicode normalization issues, and broader script coverage.
- Reproducibility and variance: Report multiple training seeds and variance in results, especially given small absolute BPC differences.
- Ablations of mixture components: Provide controlled ablations for character-only vs lexicon-only vs mixed models to quantify each component’s contribution across tasks.
Practical Applications
Practical Applications of “Subword Segmental Language Modelling for Nguni Languages”
This paper introduces a Subword Segmental LLM (SSLM) that jointly learns subword segmentation and autoregressive language modeling, yielding better intrinsic LM performance and stronger unsupervised morphological segmentation for four low-resource, agglutinative Nguni languages (isiXhosa, isiZulu, isiNdebele, Siswati). It also releases curated datasets and open-source code. Below are actionable, real-world applications derived from the findings, methods, and innovations.
Immediate Applications
These can be piloted or deployed now with existing models, code, and datasets.
- Morphology-aware tokenization/segmentation for NLP pipelines
- Sectors: software/NLP, academia
- Tools/workflows: use SSLM’s Viterbi segmentation to preprocess text for downstream tasks (NER, POS tagging, sentiment analysis, information retrieval), replacing off-the-shelf BPE/Unigram tokenizers that underperform on agglutinative languages.
- Assumptions/dependencies: requires the released SSLM checkpoints or training on in-domain data; hyperparameter tuning of lexicon size and max segment length per language; possible over-segmentation mitigated via thresholds or post-rules.
- Better LLMs for ASR/OCR post-processing and text generation in Nguni languages
- Sectors: speech tech, government digital services, media
- Tools/workflows: plug SSLM (character-level LSTM with dynamic programming) into decoding or rescoring for ASR; use for predictive text or generative text tasks where open-vocabulary handling is critical.
- Assumptions/dependencies: integration with existing decoders; compute-efficient deployment (distillation/quantization may be needed); model trained on government-heavy corpora may require domain adaptation.
- Unsupervised morphological segmentation for lexicography and corpus linguistics
- Sectors: academia, publishing, language documentation
- Tools/workflows: run the word-level segmental model to produce high-precision morpheme inventories, affix lists, and segmented corpora for dictionary building and linguistic analysis.
- Assumptions/dependencies: unsupervised outputs should be curated by linguists; segment quality depends on corpus coverage; over-segmentation can be controlled by tuning lexicon parameters.
- Improved tokenization for machine translation (MT) and multilingual NLP
- Sectors: software/NLP, localization
- Tools/workflows: substitute SSLM-derived subwords or segmentations in MT training data to reduce over-segmentation and improve source modeling for agglutinative languages.
- Assumptions/dependencies: training-time integration (e.g., swapping tokenizers) and empirical validation; bilingual data availability; may require pipeline adjustments for segmentation consistency.
- Spellchecking, lemmatization, and grammar checking
- Sectors: productivity software, education
- Tools/workflows: leverage morpheme boundaries to detect affixation patterns, normalize stems, and flag likely morphological errors; use in document editors and web forms.
- Assumptions/dependencies: rule-based or ML error detection layers must be built on top of segmentation; domain adaptation required for everyday language vs. formal texts.
- Search and indexing for agglutinative languages
- Sectors: search/IR, e-government
- Tools/workflows: index stems and affixes separately to improve recall/precision in search; enable morphology-aware query expansion.
- Assumptions/dependencies: requires IR pipeline changes; evaluation on user queries; quality of segmentation determines gains.
- Educational reading aids and literacy tools
- Sectors: education/EdTech
- Tools/workflows: on-the-fly morpheme highlighting and word “unpacking” in readers and learning apps; scaffolds vocabulary acquisition in agglutinative languages.
- Assumptions/dependencies: simple UI integration; configure conservative segmentation thresholds to avoid confusing learners.
- Public-sector and civic-tech chatbots in Nguni languages
- Sectors: public policy/government, customer support
- Tools/workflows: deploy SSLM-based tokenization/LM components to better handle rare/compound words; improves open-vocabulary understanding and response generation.
- Assumptions/dependencies: privacy and security constraints; fine-tuning on domain dialogue; compute and MLOps readiness.
- Reuse of released datasets and code for rapid prototyping
- Sectors: academia, startups, civic tech
- Tools/workflows: use the curated train/validation/test splits for benchmarking; build reproducible baselines; integrate the SSLM codebase into existing Python/NLP stacks.
- Assumptions/dependencies: dataset domain skew (government texts); licensing compliance; expectation of tuning per language/task.
Long-Term Applications
These require additional research, scaling, or engineering effort.
- Morphology-aware large-scale LLMs and pretraining
- Sectors: AI/foundation models, software/NLP
- Tools/workflows: integrate segmental modeling into Transformer pretraining (e.g., segmental decoders or hybrid tokenization-free models) to better serve morphologically rich languages at scale.
- Assumptions/dependencies: algorithmic adaptation of dynamic programming with Transformer architectures; significant compute; multilingual training strategies.
- End-to-end ASR/TTS enhancements via morphology-aware text modeling
- Sectors: speech tech, accessibility
- Tools/workflows: combine SSLM with acoustic models to improve recognition of complex word forms; use segmentation to enhance grapheme-to-phoneme conversion and prosody modeling in TTS.
- Assumptions/dependencies: need sizable speech corpora in Nguni languages; careful evaluation; latency/footprint constraints for on-device use.
- Joint segmentation–translation architectures for NMT
- Sectors: localization, global services
- Tools/workflows: design NMT models that learn segmentation jointly with translation, reducing tokenization artifacts for agglutinative sources.
- Assumptions/dependencies: architecture research; stable training with latent segmentations; adequate bilingual corpora.
- Personalized, on-device keyboards and IMEs that learn segmentation
- Sectors: mobile/consumer tech
- Tools/workflows: on-device SSLMs that adapt segmentation and prediction to user-specific morphology and style; privacy-preserving continual learning.
- Assumptions/dependencies: efficient inference/training on constrained hardware; federated learning; UX validation.
- Scalable, semi-automatic morphological analyzers for low-resource languages
- Sectors: language documentation, academia
- Tools/workflows: extend SSLM to other Bantu and morphologically rich languages; human-in-the-loop pipelines for building analyzers and lexicons from raw text.
- Assumptions/dependencies: small, clean corpora per language; language-specific hyperparameter tuning; varying effectiveness on fusional languages.
- Domain-robust, morphology-aware chatbots and agents in finance and healthcare
- Sectors: finance, healthcare
- Tools/workflows: deploy dialogue systems that handle complex inflection/derivation, improving intent recognition and slot filling in specialized domains; combine with ASR for call centers.
- Assumptions/dependencies: strict privacy/compliance (POPIA, HIPAA equivalents); domain adaptation; safety evaluation.
- Standards and policy for tokenization in public-sector NLP
- Sectors: public policy/government
- Tools/workflows: define government-wide tokenization/segmentation guidelines for agglutinative languages; fund compute/data infrastructure to support morphology-aware NLP.
- Assumptions/dependencies: multi-agency coordination; procurement and maintenance plans; inclusion of human evaluation to complement automatic metrics.
- Robotics and assistive interfaces in local languages
- Sectors: robotics, accessibility/assistive tech
- Tools/workflows: robust command parsing and dialogue in Nguni languages via morphology-aware SLU; enable inclusive voice interfaces.
- Assumptions/dependencies: end-to-end ASR+NLU availability; safety-critical evaluation; data collection for human–robot interactions.
- Curriculum tools for teaching morphology and linguistics
- Sectors: education/EdTech, academia
- Tools/workflows: interactive platforms that visualize segmentation and morphology; support for teacher dashboards and learner analytics.
- Assumptions/dependencies: collaboration with educators; adaptation to different orthographic conventions; mitigating model over-segmentation in teaching contexts.
Notes on feasibility across applications:
- Tuning sensitivity: Optimal lexicon size and max segment length vary by language and task; expect per-language tuning.
- Data domain: Released corpora skew toward government texts; domain adaptation or additional corpora will improve generalization.
- Over-segmentation: Long-range SSLMs may over-segment in low-resource settings; word-level models provide higher-precision segmentation when long-range context is not needed.
- Compute/resources: Training SSLMs can take days on GPUs; deployment may require model compression.
- Language coverage: Results validated on four Nguni languages; effectiveness may differ for fusional or polysynthetic languages without adaptation.
Glossary
- Agglutinative (languages): A linguistic typology where words are formed by concatenating multiple morphemes, each typically carrying a single grammatical meaning. "These are low-resource agglutinative languages"
- Autoregressive language modelling: A modeling approach that predicts the next token based on previously generated tokens in sequence. "training as an autoregressive LM."
- Bits-per-character (BPC): A cross-entropy-based metric that measures how well a LLM predicts text, normalized by character count. "We evaluate our models using bits-per-character (BPC) - an intrinsic evaluation metric"
- Byte-pair encoding (BPE): A data-driven subword segmentation algorithm that merges frequent symbol pairs to create a subword vocabulary. "With algorithms like byte-pair encoding (BPE), subword segmen- tation is viewed as a preprocessing step"
- Canonical segmentation: Morphological segmentation into standardized morphemes that may not correspond to surface substrings. "Words are segmented into their canonical segmentations i.e. standardised morphemes"
- Conditional entropy: The expected uncertainty of the next character given the previous context, used here to locate morpheme boundaries. "The conditional entropy of xi in a sequence x is defined as"
- Conditional semi-Markov assumption: An assumption that segment probabilities depend only on the unsegmented history, enabling efficient inference. "by introducing a conditional semi-Markov assumption,"
- Conjunctively written: An orthographic convention where morphemes are joined without spaces, producing long word forms. "because they are agglutinative languages that are written conjunctively."
- Dynamic programming: An algorithmic technique used to efficiently sum over all possible segmentations and to find the most likely segmentation. "Both of these models use dynamic programming to efficiently compute marginal likelihood"
- Entropy-based segmenter: A segmentation method that predicts boundaries at points of high model uncertainty (entropy). "We also imple- mented a character-level entropy-based segmenter,"
- Expected length regularisation: A training bias that encourages shorter segments to prevent overfitting on small datasets. "expected length regularisation."
- Latent variable: An unobserved variable—in this context, the unknown segmentation—over which the model marginalizes. "treating sequence segmentation as a latent variable to be marginalised over."
- Levenshtein distance: A string edit distance used here to map canonical to surface segmentations via minimal edits. "based on the Levenshtein distance minimal edit operations"
- Lexical memory: An external memory of frequent segments that the model can consult during generation. "equipping the model with a lexical memory"
- Lexicon model: A component that generates entire segments by selecting from a learned subword lexicon. "a lexicon model generates the segment"
- Lexicon size: A hyperparameter specifying how many subwords are included in the model’s lexicon. "The lexicon size V is also prespecified."
- Marginal likelihood: The probability of observed data obtained by summing over all possible segmentations. "compute marginal likelihood during training"
- Maximum segment length: A hyperparameter that sets the upper bound on subword length considered by the model. "lexicon- related hyperparameters: lexicon size and maxi- mum segment length."
- Minimum description length: A principle favoring models that compress data well; used as the objective in Morfessor. "based on minimum de- scription length."
- Mixture coefficient: A scalar weight that balances between character-level generation and lexicon-based generation. "The mixture coefficient gk is also computed"
- Mixture model: A probabilistic combination of two generators (character-level and lexicon-based) for emitting segments. "a mixture model (equation 6) that interpolates between a separate character-level LSTM decoder and a lexicon model"
- Morpheme: The smallest meaningful unit in a language used to build words. "Morphemes are the primary linguistic units."
- Morpheme boundary identification (MBI): The task of predicting whether a boundary between two characters is a morpheme boundary. "Morpheme boundary identification (MBI) metrics"
- Morpheme identification (MI): The task of detecting morphemes present in the segmented output of words. "Morpheme identification (MI) metrics"
- Open-vocabulary model: A model that can handle previously unseen words by composing them from subword units. "as an open-vocabulary model."
- Segmental LLM (SLM): A LLM that jointly learns segmentation and modeling of sequences. "coined the term 'seg- mental LLM' (SLM)"
- Segmental sequence models: Models that treat segmentation as latent and marginalize over possible segmentations during learning. "segmental sequence models"
- Subword lexicon: A curated set of frequent subwords that the model uses to generate multi-character segments. "the importance of a subword lexicon to our model"
- Subword segmentation: The process of splitting text into subword units to balance vocabulary size and coverage. "Subword segmentation has become a standard prac- tice in NLP."
- Unigram LM (ULM): A probabilistic segmentation model that assumes subwords are generated independently under a unigram LLM. "stochastic algorithms like unigram LM (ULM) (Kudo, 2018) have also been proposed."
- Unsupervised morphological segmentation (UMS): Segmenting words into morphemes without annotated supervision. "We evaluate our SSLM on unsupervised morpho- logical segmentation (UMS)"
- Viterbi algorithm: A dynamic programming method for finding the most probable segmentation sequence. "using the Viterbi algorithm."
- Word-level sequence model: A model trained on individual words in isolation rather than full sentences. "We also train our model as a word-level sequence model,"
Collections
Sign up for free to add this paper to one or more collections.

