- The paper introduces an innovative Transformer that replaces standard dot product attention with an equivariant MLP-based mechanism for 3D atomistic graphs.
- It leverages irreducible representations and tensor products to enforce SE(3)/E(3)-equivariance, enhancing the model's ability to capture 3D geometric features.
- Empirical results on datasets like QM9, MD17, and OC20 demonstrate state-of-the-art performance and scalability in predicting complex quantum properties.
Introduction and Motivation
Equiformer addresses the limitations of traditional Transformer networks when applied to 3D atomistic graphs such as molecules. In domains requiring prediction of quantum properties, existing neural architectures leverage inductive biases reflecting data symmetry, yet 3D atomistic graph datasets have proven challenging for vanilla Transformers. This research presents Equiformer, an innovative graph neural network integrating Transformer architecture with SE(3)/E(3)-equivariant features based on irreducible representations (irreps).
Architectural Innovations
The Equiformer architecture fundamentally transforms Transformers by substituting original operations with their equivariant counterparts and introduces tensor products to maintain and process equivariant information within irreps features. This design is realized with minimal adjustments to existing Transformer structures, achieving high empirical results without complicating graph structures.
Equivariant Graph Attention Mechanism
A novel element of Equiformer is the equivariant graph attention, which enhances standard Transformer attention mechanisms. This is done by replacing dot product attention with multi-layer perceptron (MLP) attention and incorporating non-linear message passing. These transformations enable the effective encoding of 3D-related inductive biases within Transformers, showing competitive results on various benchmarks like QM9, MD17, and OC20.
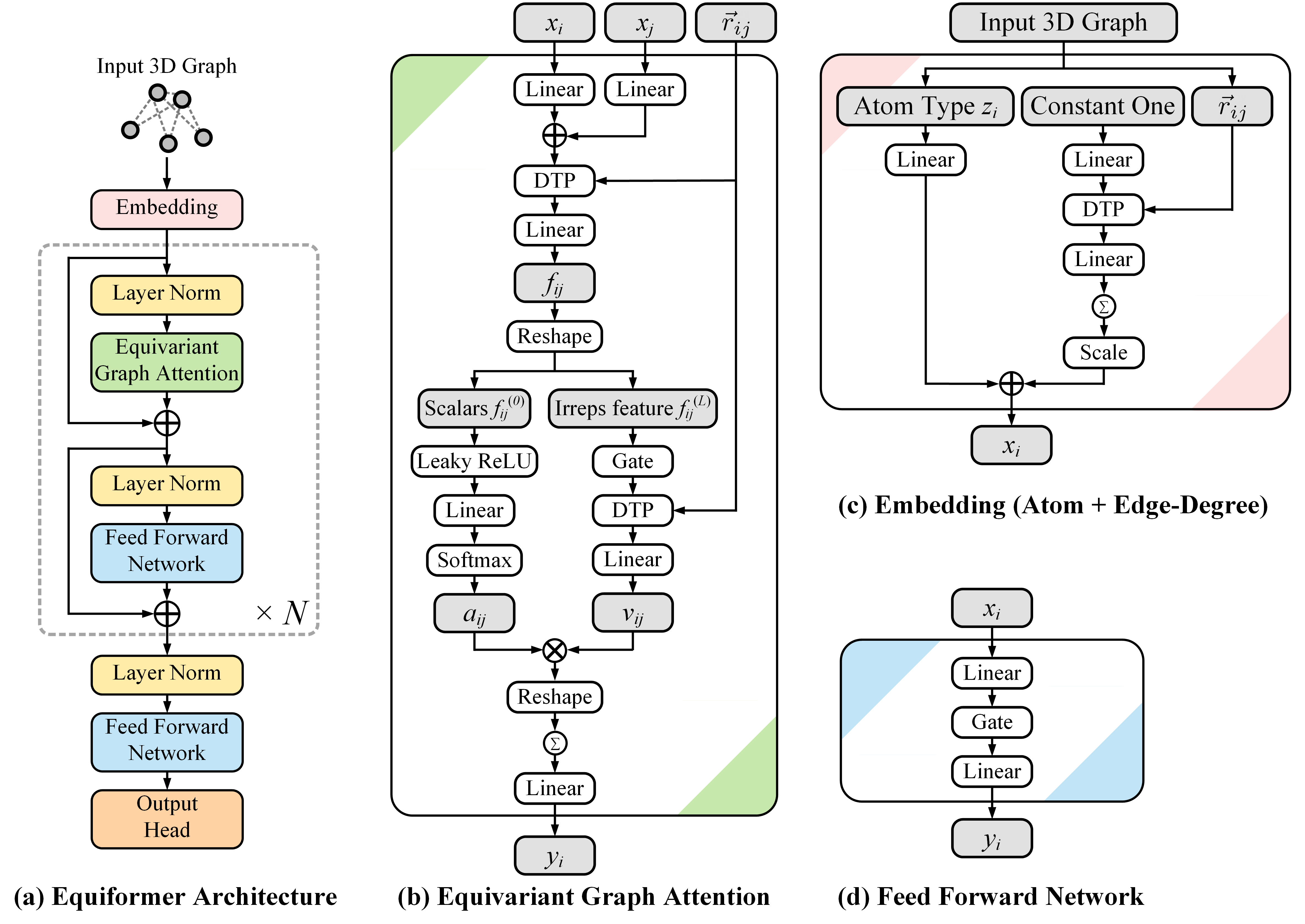
Figure 1: Architecture of Equiformer. We embed input 3D graphs with atom and edge-degree embeddings and process them with Transformer blocks, consisting of equivariant graph attention and feed-forward networks.
Empirical Evaluation
Datasets and Results
- QM9 and MD17 Datasets: For small molecules (<100 atoms), Equiformer achieved the best aggregate performance across multiple tasks, surpassing models like NequIP and TorchMD-NET. On QM9, Equiformer excels due to its superior handling of equivariant features and its unique attention mechanism.
- OC20 Dataset: For larger, more complex atomistic systems (~1 Å accuracy), Equiformer achieves state-of-the-art results especially when trained with IS2RE and IS2RS data, highlighting its scalability and robustness.
Ablation Studies
The research includes ablation studies illustrating the significance of the two proposed innovations: improved dot product attention and non-linear message passing. Results show that even with only dot product attention, Equiformer exhibits strong performance, while including all proposed features results in improved scores, particularly in complex datasets.
Theoretical and Practical Implications
Equiformer's equivariant graph attention transforms potentially extendable beyond 3D atomistic graphs to other domains like complex molecular dynamics and material science applications.
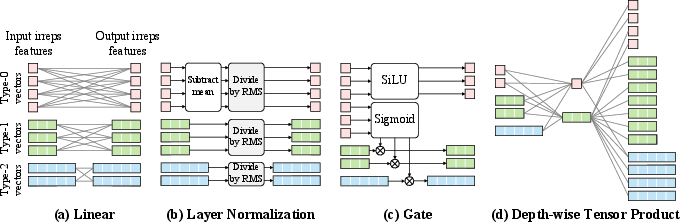
Figure 2: Equivariant operations used in Equiformer. Visualizing various interaction mechanisms like equivariant activations and tensor products provides further insight into its capabilities.
Conclusion
Equiformer showcases innovative integration of Transformers with equivariant graph neural networks, offering substantial performance gains in predicting intricate quantum properties of atomistic graphs. The research demonstrates that equipping architectures with inductive biases via equivariant operations can significantly enhance their applicability in domains where geometric transformations (e.g., rotation, translation) are critical. Future explorations could focus on further optimizing computational efficiency and extending the framework to other complex systems.