- The paper introduces an iterative prompting framework with a context-aware Prompter that elicits chains of thought for multi-step reasoning in PLMs.
- Results show over 15% F1 gains on 2WikiMultiHopQA and comparable accuracy to full fine-tuning while maintaining parameter efficiency.
- Attention visualizations confirm that dynamic prompts adapt to evolving context, reducing reliance on dataset artifacts.
Iterative Prompting for Chain-of-Thought Reasoning in Pre-trained LLMs
The paper "Iteratively Prompt Pre-trained LLMs for Chain of Thought" (2203.08383) addresses the limitations of contemporary PLMs in performing multi-step inference, despite their capacity to internalize vast world knowledge. Prior work demonstrates that PLMs can recall atomic facts with direct prompting or fine-tuning, but they are largely ineffective at compositional reasoning scenarios requiring the systematic recall of chains of facts. The authors formalize the challenge as eliciting a sequence of simple knowledge statements Cq=[c1,...,cnq] sufficient to answer a complex query q. Their goal is to prompt a large, fixed PLM M—without altering its parameters—to output this series of knowledge, enabling multi-step inference without excessive parameter tuning or risk of catastrophic forgetting.
Iterative Prompting Framework
Their approach introduces an iterative prompting scheme (Figure 1), contrasting it with standard probing. In standard probing, a question is directly fed into the PLM, yielding poor results for multi-hop or compositional queries. The iterative framework augments the PLM with a Prompter module that learns to generate prompts conditioned on the current context (query and previously recalled facts). At each step j, the prompt Tj is dynamically synthesized and drives the PLM to recall the next fact cj, continuing autoregressively until the inference steps are complete.
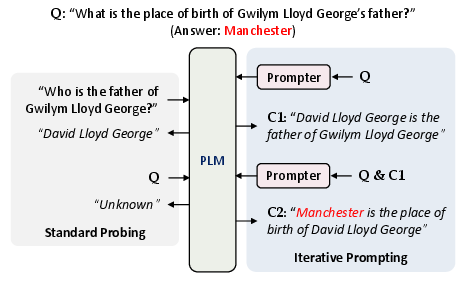
Figure 1: Iterative prompting elicits multi-step reasoning by conditioning each prompt on the evolving context, overcoming limitations of standard single-shot probing.
Context-Aware Prompter Design
The Prompter is instantiated as a transformer-based encoder (Figure 2), capable of contextualizing special prompt tokens with respect to the current reasoning state: (q,c1,...,cj−1). These continuous prompts are projected into the PLM's embedding space via a trainable matrix, enabling fine-grained and dynamic conditioning. Unlike static prompt tuning and prefix tuning—which treat the prompt as independent of step-wise context—the proposed method synthesizes step-sensitive prompts, scaling parameter count with the embedding dimension and prompt length, thereby maintaining efficiency as PLM sizes grow.
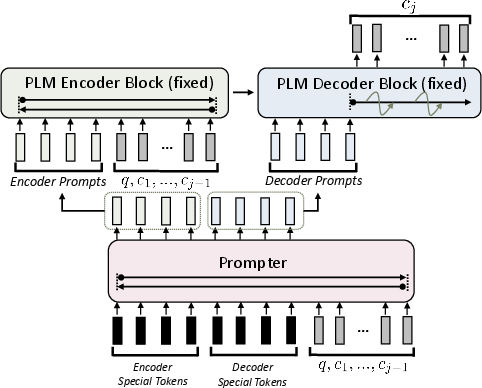
Figure 2: The context-aware Prompter generates prompts based on the evolving inference state, steering the PLM to recall contextually relevant knowledge.
The authors opt for continuous prompt representations due to superior expressivity and optimization properties compared to discrete token searches.
Experimental Evaluation
The methodology is validated on three multi-step reasoning datasets: 2WikiMultiHopQA, R4C, and Leap-of-Thought (LoT). Metrics assess both intrinsic recall (coverage of ground truth facts at each step) and extrinsic inference (final answer accuracy and F1). Comparisons are made against non-iterative prompt tuning, prefix tuning, PLM fine-tuning, and direct QA. Results demonstrate unequivocally that iterative prompting enhances intermediate recall rates and final answer accuracy, with the context-aware Prompter (iCAP) outperforming static prompting baselines.
Strong numerical results:
- On 2Wiki, iCAP achieves over 15% absolute gains in answer F1 compared to Prompt-Tuning.
- Iterative schemes (even with basic prompt or prefix tuning) always yield substantial improvements over non-iterative baselines.
- iCAP approaches the performance of full PLM fine-tuning but does so in a parameter-efficient manner.
Faithfulness Analysis and Attention Visualization
To address concerns regarding spurious dataset regularities or test-train overlap, the authors conduct random control experiments and overlap statistics, demonstrating minimal exploitation of dataset artifacts. They visualize prompter attention maps (Figures 3–7) across different reasoning types, confirming that the prompter focuses attention appropriately on relevant context parts during each step, supporting the claim that the learned prompting mechanism genuinely enables step-wise knowledge recall rather than simply memorizing dataset patterns.
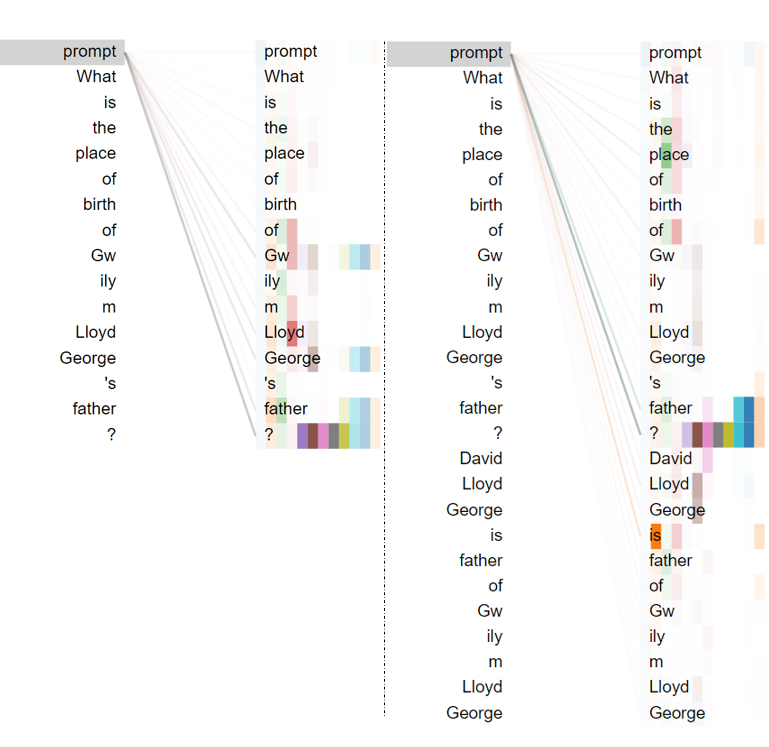
Figure 3: Visualization of prompter attention shows layer-wise focus shifting to different context elements as reasoning progresses.
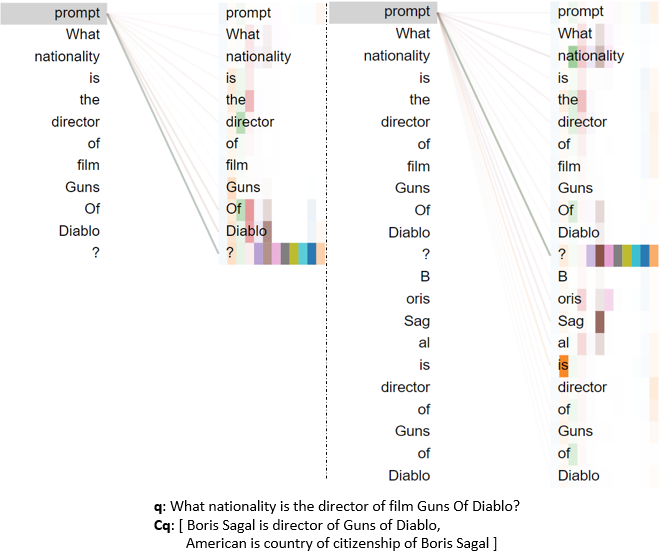
Figure 4: Prompter attention during compositional reasoning highlights dynamic contextual focus.
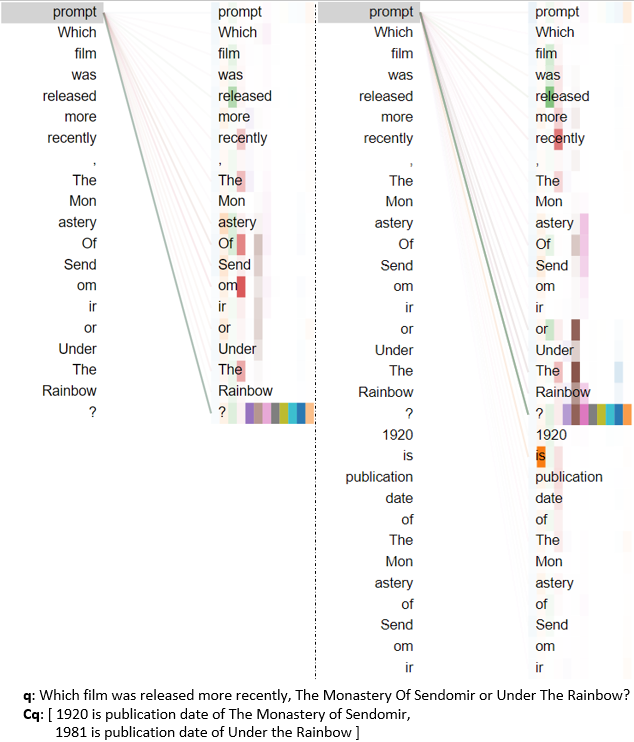
Figure 5: Attention visualization for comparison reasoning steps showcases reallocation of prompt focus.
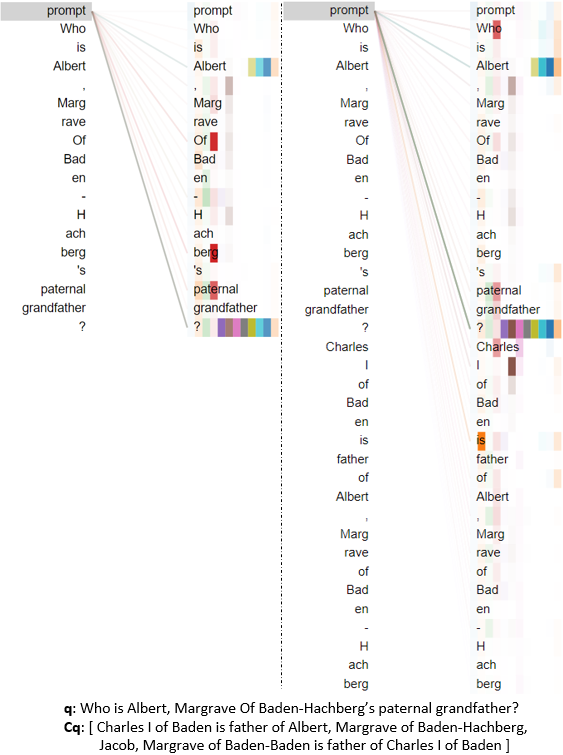
Figure 6: Inference-type reasoning prompts elicit targeted recall across layers.

Figure 7: Bridge-comparison reasoning involves prompt focus bridging between multiple entities.
Implications, Limitations, and Future Directions
The results empirically validate iterative prompting as a robust protocol for multi-step reasoning with PLMs, demonstrating that step-wise context conditioning is essential for reliable chain-of-thought recall. Parameter efficiency and faithfulness checks via randomization experiments further support the validity of the approach. Practical implications include enhanced explainability for reasoning tasks, modularity for interactive human-in-the-loop correction, and improved performance on complex QA tasks without compromising the PLM's fixed knowledge base.
There remain significant gaps to Oracle performance, indicating that further architectural advances or scale increases are needed. Extension to noisy datasets, adaptation of prompter design, and experimentation with larger-scale PLMs are proposed as future research directions.
Conclusion
This paper introduces an iterative prompting framework with a context-aware Prompter that enables PLMs to recall chains of knowledge for multi-step reasoning. The proposed technique achieves notable improvements in both intermediate evidence recall and QA performance compared with static prompting approaches, and brings parameter-efficient adaptation within reach for large PLMs. Attention visualization and faithfulness checks reinforce the methodology's integrity, and the approach opens avenues for transparent, interactive, and modular reasoning systems in NLP.