- The paper introduces TD-MPC, a novel hybrid approach that integrates a task-oriented latent dynamics model with a terminal value function through temporal difference learning.
- It demonstrates significant improvements in sample efficiency and asymptotic performance on continuous control tasks across benchmarks like DMControl and Meta-World.
- The methodology focuses on reward-centric latent model learning to mitigate error propagation and enable robust short-horizon trajectory optimization.
Temporal Difference Learning for Model Predictive Control
Introduction
The paper "Temporal Difference Learning for Model Predictive Control" (2203.04955) addresses the limitations and challenges of existing model-free and model-based reinforcement learning (RL) techniques by proposing a novel hybrid approach called Temporal Difference Learning for Model Predictive Control (TD-MPC). This approach leverages the strengths of both methods to enhance sample efficiency and performance in continuous control tasks.
Model-based RL methods offer the potential for improved sample efficiency through internal environmental model learning, but they face challenges such as high planning costs over extended horizons and model inaccuracies that can propagate. Conversely, model-free methods rely heavily on trial-and-error through policy learning and often require substantial amounts of interaction data to perform adequately.
TD-MPC proposes a framework that integrates model-free and model-based elements by combining a learned task-oriented latent dynamics model with a terminal value function, both trained using temporal difference (TD) learning. This framework allows for short-horizon trajectory optimization based on learned reward estimates, while employing a terminal value function for accurate long-term return estimates.
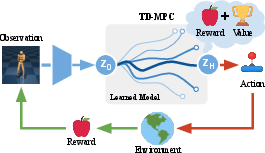
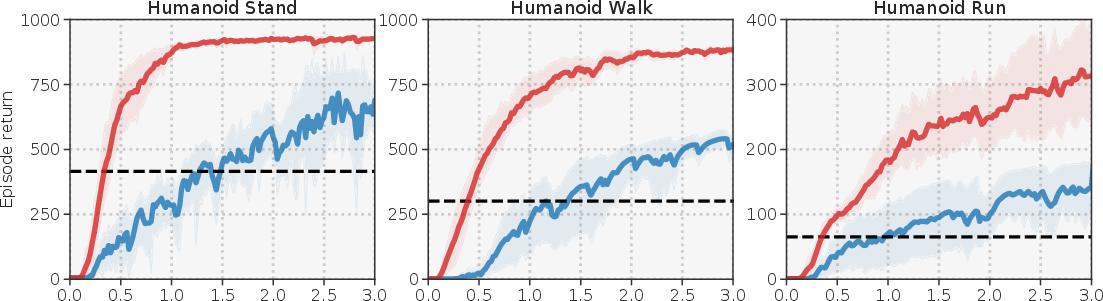
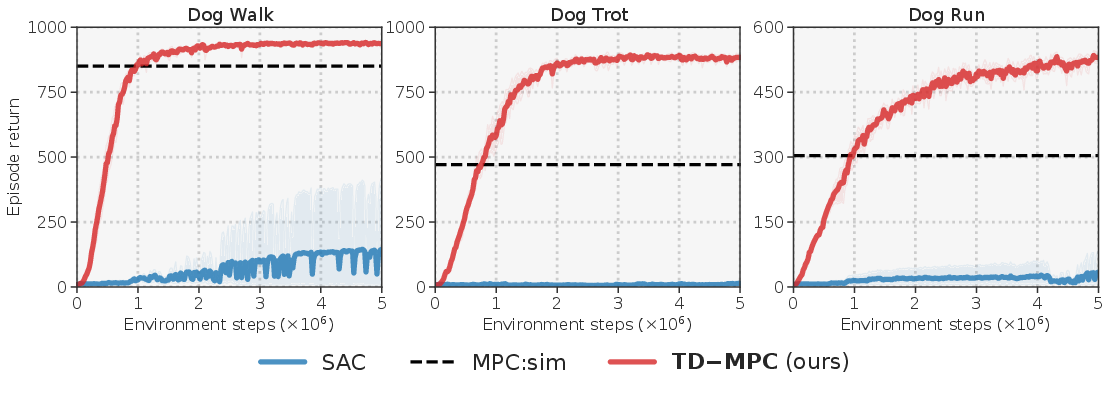
Figure 1: Overview of the TD-MPC framework utilizing a task-oriented latent dynamics model alongside a value function learned via temporal difference learning.
Methodology
Temporal Difference Learning for Model Predictive Control
TD-MPC is built upon Model Predictive Path Integral (MPPI) control for planning, using the latent dynamics model and terminal value function, Qθ, both learned in tandem by TD-learning. The main components include:
- Latent Dynamics Model: Rather than predicting the complete environment dynamics, the model focuses on task-relevant elements, improving sample efficiency and mitigating error compounding in rollouts.
- Terminal Value Function: A value function estimating long-term returns beyond local trajectory optimization horizons, learned jointly via TD-learning alongside the latent model.
This approach is distinct in how it learns and utilizes models, eschewing full environment prediction for reward-centric latent variable modeling, and applying TD-learning to both model and value function.
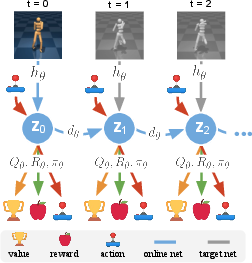
Figure 2: Training procedure for the Task-Oriented Latent Dynamics (TOLD) model illustrating sampling from a replay buffer for temporal difference-based predictions of rewards, values, and future latent states.
Implementation Details
The framework is evaluated on diverse continuous control tasks from DMControl and Meta-World, demonstrating superior sample efficiency and asymptotic performance compared to prior model-based and model-free methods. Tasks vary significantly in state/action space dimensions and reward structures.
TD-MPC employs MPPI for trajectory optimization, where parameters for distributions are iteratively updated using samples generated by the learned latent model. Exploration noise is controlled through parameter variance constraints, ensuring consistent exploration.
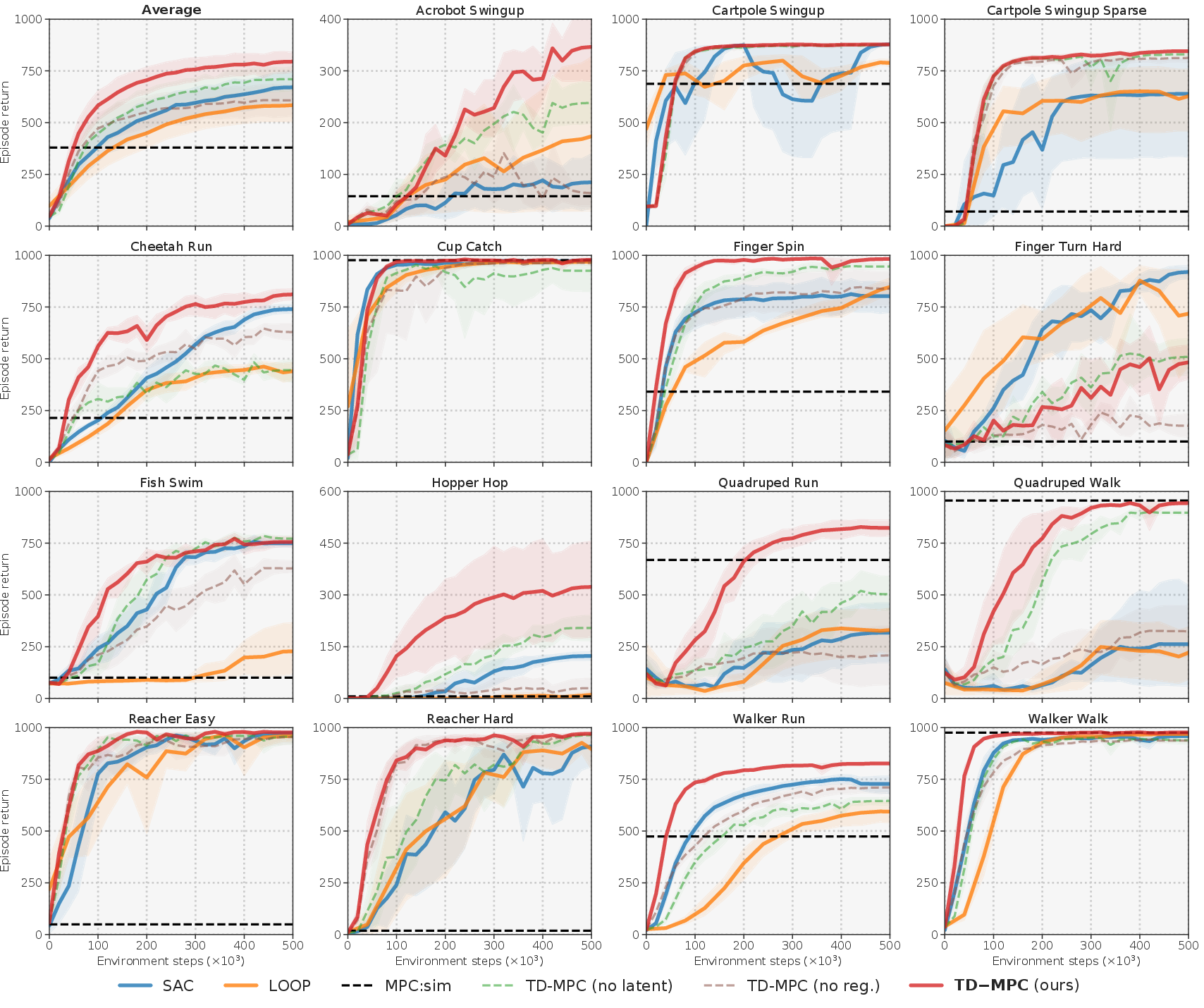
Figure 3: Performance comparisons across multiple state-based DMControl tasks demonstrating the significant gains of TD-MPC in sample efficiency and asymptotic performance.
Experimental Results
TD-MPC is tested across various benchmarks, showcasing significant improvements over existing algorithms in state-based and image-based environments. Notable results include sample efficiency in complex tasks such as Humanoid and Dog locomotion, achieving task solutions in substantially fewer environment steps.
The method scales well in dimensionality, outperforming baselines even in image-based benchmarks where existing methods require extensive tuning and larger parameter models. TD-MPC achieves competitive results with consistent hyperparameters across the board.
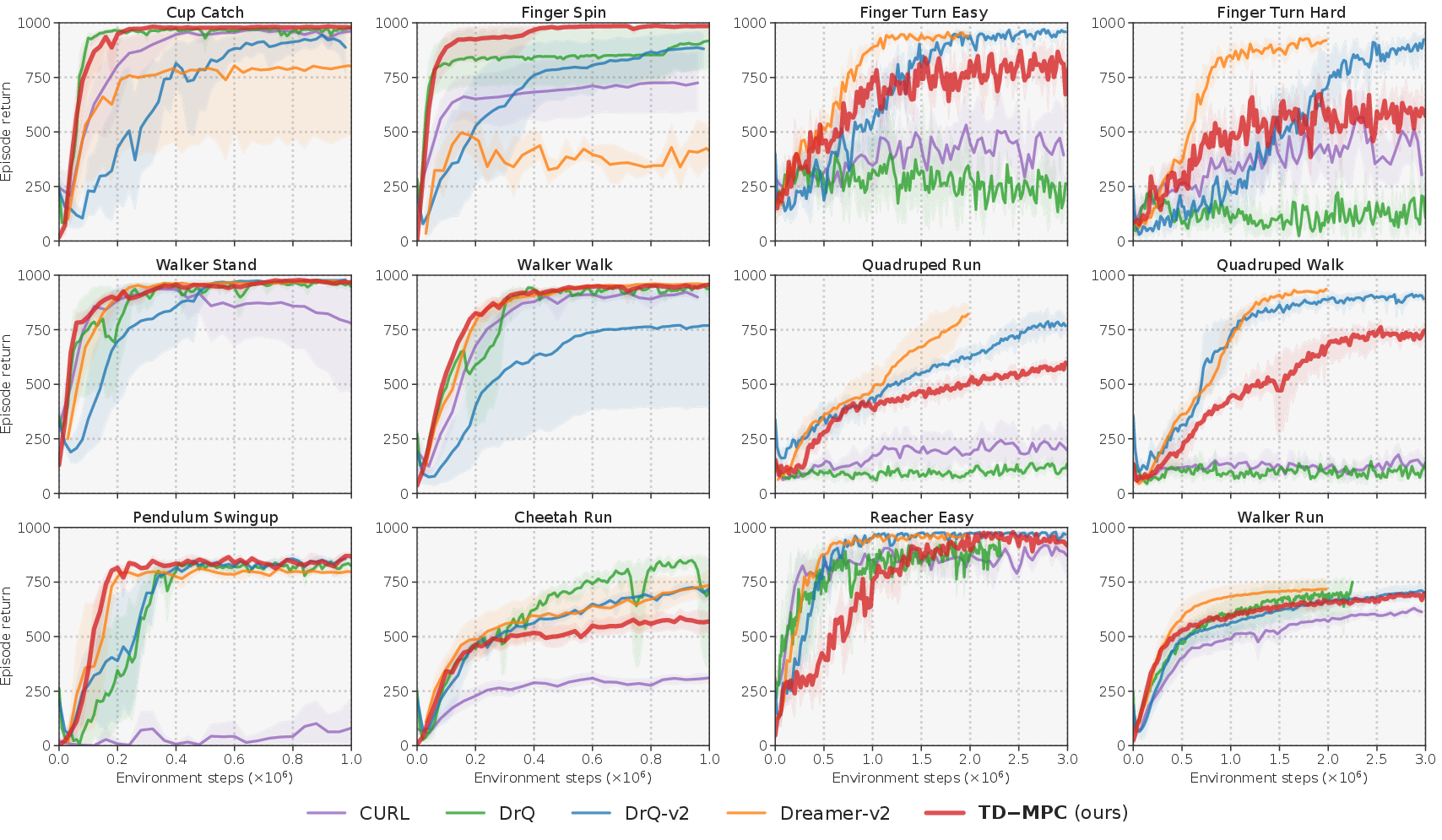
Figure 4: Results highlighting TD-MPC's comparative performance in image-based DMControl tasks against other state-of-the-art algorithms.
Implications and Future Directions
TD-MPC’s integration of model-free and model-based elements via TD-learning offers a promising avenue for efficient RL in complex control tasks. By focusing model learning on reward-predictive features rather than full environment reconstruction, TD-MPC achieves robustness and efficiency.
Future advancements may focus on multi-task and transfer learning applications, exploiting the task-centric nature of model learning. Further exploration of architectural innovations or improved exploration techniques could enhance performance, leading to broader applicability in real-time, high-dimensional control settings.
Conclusion
The paper on TD-MPC presents a method effectively blending model-based and model-free RL techniques through joint TD-learning for both model and value function. This results in superior performance and efficiency, particularly in high-dimensional or sparse-reward environments, without relying on task-specific tuning. TD-MPC holds potential for advancing RL strategies in complex operational domains due to its scalable and adaptable design.