- The paper introduces a novel FL algorithm that leverages server-side stepsize modulation and sampling without replacement to improve convergence in convex, strongly convex, and non-convex settings.
- It provides a rigorous complexity analysis, demonstrating a convergence rate improvement from O(ε⁻³) to O(ε⁻²) in strongly convex regimes through adaptive strategies.
- Experimental validations confirm that tuning server and client stepsizes reduces gradient variance and communication overhead, enhancing practical decentralized learning.
Server-Side Stepsizes and Sampling Without Replacement Provably Help in Federated Optimization
Introduction
This paper presents a theoretical study on enhancing federated learning through server-side optimization techniques, specifically focusing on stepsize management on the server and the strategic use of sampling without replacement. Federated Learning (FL) is a decentralized approach to training machine learning models across distributed and heterogeneous client data sources, as initially introduced by Konečný et al. and McMahan et al. in the mid-2010s. The main drivers for FL are privacy preservation and reduced communication overhead by performing training locally on client datasets.
The core problem is the optimization of a global objective function that is a sum of local loss functions distributed across numerous clients:
f(x)=M1m=1∑Mfm(x)
where M is the number of clients, and each fm represents the loss function over the local data of client m. Each local function fm is further decomposed into a finite sum structure:
fm(x)=n1i=1∑nfmi(x)
where the fmi are the losses over individual data points on the client. The paper addresses the diverse regimes of convex, strongly convex, and non-convex objectives in FL.
Contributions
The paper introduces several notable contributions aimed at improving FL's efficacy:
- Algorithm Design: A novel FL algorithm named
Nastya combines existing techniques like partial client participation, local client training, data reshuffling, and adaptive server stepsizes. Notably, the algorithm employs a server-side learning rate modulation while clients perform local training using Random Reshuffling (RR).
- Complexity Analysis: It provides rigorous complexity bounds for the proposed method across different convexity regimes, demonstrating substantial improvements in convergence rates. In strongly convex settings, a large server stepsize allows a leap from O(ε−3) to O(ε−2) in convergence.
- Theoretical Insights: The paper presents formal justification for empirical observations in FL, particularly showing how server-side stepsize adjustment and sampling strategy mitigate communication bottlenecks and improve learning rates.
- Experimental Validation: Through numerical simulations, it validates theoretical predictions and showcases how adaptive strategies bolster FL performance in practical scenarios compared to existing benchmarks.
Experimental Observations
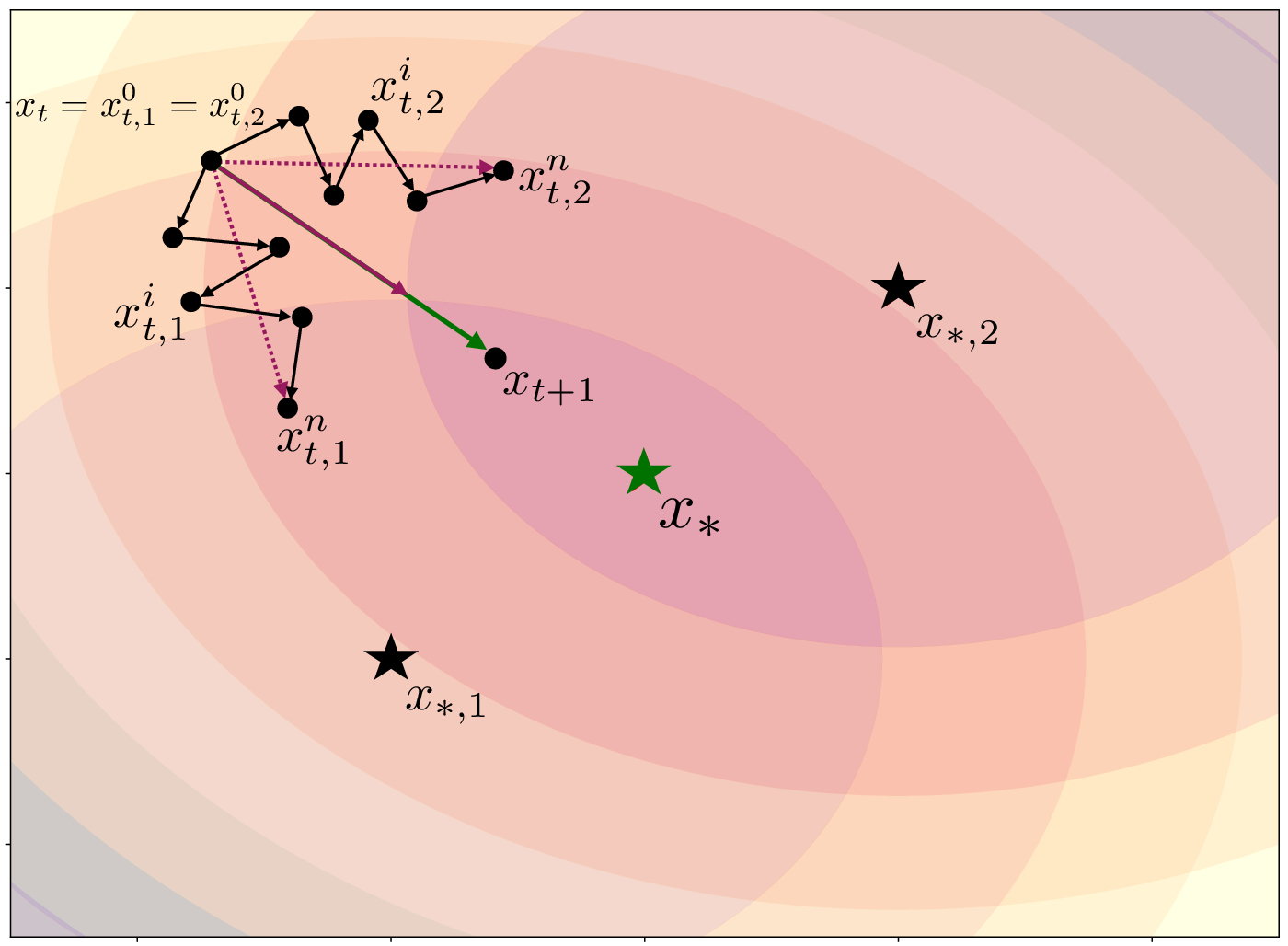
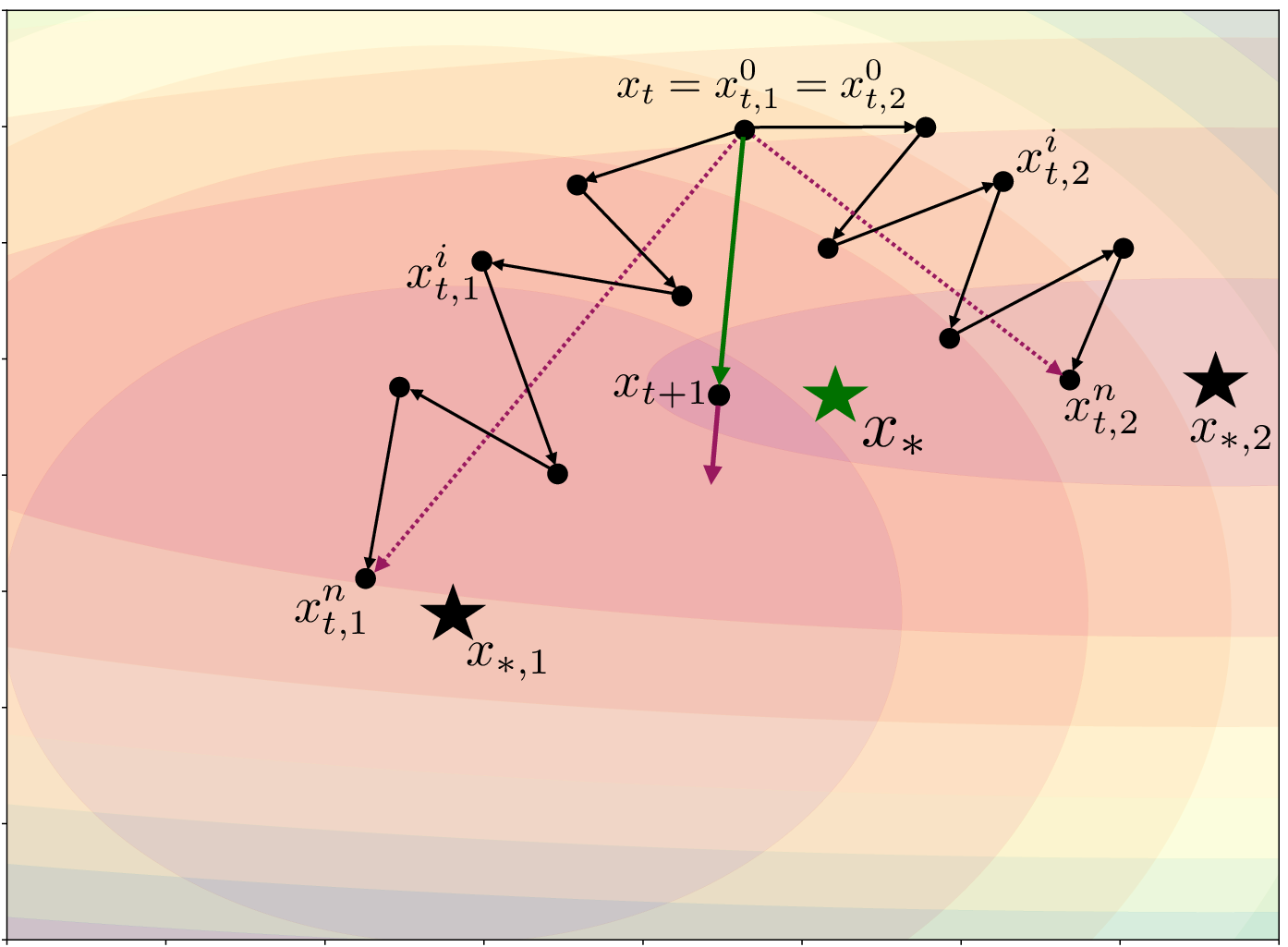
Figure 1: Illustration of the dependence between server and client stepsizes on a simple example with M=2 clients.
The experiments demonstrate that correctly tuning server-side stepsizes in conjunction with small client stepsizes can significantly reduce gradient variance, supporting faster and more reliable convergence in FL tasks. By comparing RR, adaptive gradient descent, and the proposed combined approach, the validations confirm that the integration of server-side stepsizes achieves better optimization and communication efficiency.
Implications and Theoretical Insights
This paper's implications highlight the critical interplay between server and client-side optimizations in federated systems and the enduring need to adapt these techniques for robust decentralized learning. By establishing theoretical bounds and practical improvements, the findings advocate for wider adoption of adaptive stepsize strategies in FL frameworks to leverage local computation with minimal server-client overhead.
Conclusion
The research advances the theoretical understanding and practical application of federated learning, specifically through the adaptation of server-side stepsizes and sampling strategies. By incorporating techniques like Random Reshuffling and adaptive learning rates, FL can achieve improved convergence rates and reduced communication complexity, opening avenues for further investigation into adaptive federated systems and deployment strategies across heterogeneous environments.

