- The paper introduces CLIPSeg, a model that unifies zero-shot, one-shot, and referring expression segmentation using a frozen CLIP backbone and a transformer-based decoder.
- The methodology leverages FiLM conditioning and U-Net-inspired skip connections to integrate text and image prompts for effective dense prediction.
- Experimental results demonstrate competitive performance on benchmarks such as PhraseCut, Pascal-5i, and COCO-20i, highlighting its adaptability to various segmentation tasks.
Image Segmentation Using Text and Image Prompts
Introduction to CLIPSeg
The paper "Image Segmentation Using Text and Image Prompts" presents a novel approach that leverages the CLIP model to create a flexible segmentation system called CLIPSeg. This system is designed to address multiple segmentation tasks, such as zero-shot, one-shot, and referring expression segmentation, all within a unified framework. The core idea is to utilize CLIP as the backbone model and to incorporate a transformer-based decoder that facilitates dense prediction.
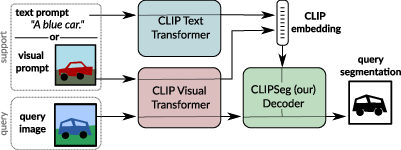
Figure 1: Our key idea is to use CLIP to build a flexible zero/one-shot segmentation system that addresses multiple tasks at once.
System Architecture
The CLIPSeg architecture extends the CLIP model by adding a lightweight transformer-based decoder. The CLIP model itself remains frozen during this process, and the decoder is trained specifically for segmentation tasks. Essential to the architecture is the use of U-Net-inspired skip connections, which allow for a compact decoder that maintains the predictive performance of the CLIP backbone.
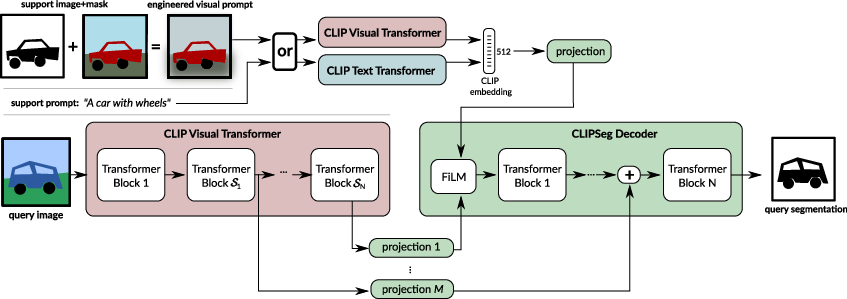
Figure 2: Architecture of CLIPSeg: We extend a frozen CLIP model (red and blue) with a transformer that segments the query image based on either a support image or a support prompt.
The decoder achieves segmentation by generating a binary map based on the input prompts, which can be either textual or visual. FiLM conditioning is used to modulate the decoder’s activations based on the prompt information, allowing the model to operate in a hybrid input setting.
Visual Prompt Engineering
A critical component in the use of CLIPSeg is the engineering of visual prompts. Through comprehensive evaluations, the paper determines that how a visual prompt is created has significant effects on segmentation performance. They find that modifying the background of the image — by lowering its brightness, blurring, and cropping around objects — significantly improves the alignment of visual and text-based embeddings.

Figure 3: Different forms of combining an image with the associated object mask to build a visual prompt have a strong effect on CLIP predictions (bar charts).
The paper reports strong performance of the CLIPSeg model across several segmentation benchmarks, notably outperforming existing systems on some tasks. For instance:
- Referring Expression Segmentation: The model shows competitive performance on datasets like PhraseCut, highlighting its ability to generalize well to novel queries.
- Generalized Zero-Shot Segmentation: By training on PhraseCut+ while excluding certain Pascal classes, CLIPSeg demonstrates the capability to segment both seen and unseen categories effectively.
- One-Shot Semantic Segmentation: The model displays robust capabilities, achieving results close to state-of-the-art for Pascal-5i and COCO-20i datasets.
Through these experiments, CLIPSeg proves the feasibility of a unified model capable of zero-shot, one-shot, and generalized segmentation tasks using both text and image queries.
Generalization Capabilities
The CLIPSeg system also showcases significant generalization capabilities by segmenting based on generalized prompts related to affordances and attributes, such as “can fly” or “sit on.” This demonstrates its potential flexibility in dealing with novel or unseen inputs, making it suitable for real-world applications where training data might not cover all scenarios.
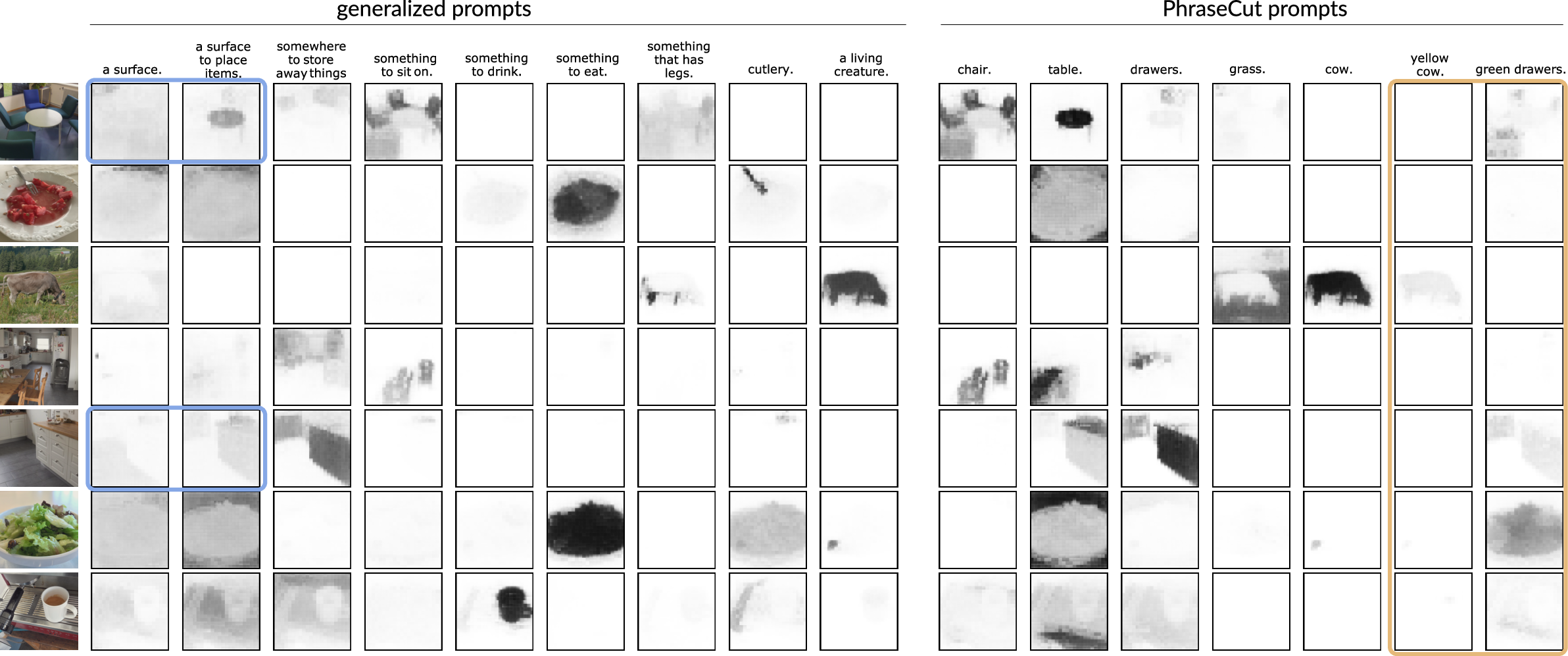
Figure 4: Qualitative predictions of CLIPSeg (PC+) for various prompts, darkness indicates prediction strength.
Conclusion
"Image Segmentation Using Text and Image Prompts" contributes significantly by providing a model that can generalize across various segmentation tasks. The developed techniques in prompt engineering, combined with the powerful CLIP backbone, allow for effective segmentation that adapts to both textual and visual queries. Such advances mean that CLIPSeg is particularly valuable in applications where rapid adaptation to new tasks and environments is crucial, such as in interactive systems or autonomous robots. The paper highlights the promising direction of integrating multimodal input in vision models, pointing towards future developments involving even richer data modalities.

