- The paper demonstrates that large language models can execute zero-shot vulnerability repair without task-specific training.
- It presents an experimental framework incorporating prompt engineering, security testing, and regression assessment to validate code fixes.
- Findings reveal high success in synthetic tests while highlighting the need for refinement in complex, real-world scenarios.
Implementing Zero-Shot Vulnerability Repair with LLMs
The paper "Examining Zero-Shot Vulnerability Repair with LLMs" explores the potential of LLMs, such as OpenAI's Codex and AI21's Jurassic J-1, in assisting with zero-shot vulnerability repair in software security. It evaluates the ability of these models to generate secure, functional code repairs without specific training for this task. This essay will detail practical implementation strategies, including the experimental setups, model configurations, and applications for real-world use.
Experimental Framework and Implementation
Model Selection and Configuration
Multiple LLMs with varying parameters were used for evaluation:
- OpenAI Codex: Specifically, models like code-cushman-001, code-davinci-001, and code-davinci-002. These models are distinguished by their parameter sizes and API restrictions (e.g., token limits).
- AI21 Jurassic-1: Network sizes like j1-jumbo and j1-large with differing access limitations.
- Locally-Trained Models: Included the 'polycoder' and a custom 'gpt2-csrc', trained specifically on C/C++ code, providing greater control over training datasets and model configurations.
The choice of model impacts both the computational cost and practicality of deployment. OpenAI's models, being API-driven, limit batch processing due to token restrictions, whereas locally-trained models offer full control but require significant computational resources.
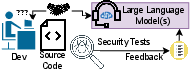
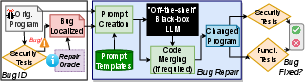
Figure 1: Results when using black-box LLMs.
Synthetic Vulnerability Generation
The initial step involved generating synthetic vulnerabilities within code snippets to study LLMs' response in repairing them. For instance:
- CWE-787: Buffer overflow vulnerabilities were synthetically created in C programs by utilizing Codex to suggest multiple program continuations with specific parameter variations.
- CWE-89: SQL injection vulnerabilities in Python were similarly generated.
The models' performance was assessed by processing these synthetic scenarios through security tools like CodeQL for vulnerability detection, followed by an automated repair attempt using the LLM-generated code.
Vulnerability Repair Framework
The framework developed automates vulnerability repair by integrating:
- Prompt Engineering: Careful construction of input prompts, including contextually relevant code and comments to guide LLMs toward generating secure fixes.
- Security Testing: Using external tools like CodeQL to verify that LLM's suggestions remedied the vulnerabilities without introducing new issues.
- Regression Testing: Ensuring functional correctness post-repair through existing test suites.
This framework demonstrates a loop of vulnerability identification, repair generation, and subsequent validation, crucial for any iterative code refinement process.
Real-World Application and Findings
Dataset Utilization
From the ExtractFix dataset, real-world vulnerabilities (CVEs) from popular libraries like Libtiff, Libxml2, and Libjpeg-turbo were selected. The process included:
Discussion and Future Directions
Efficacy of LLMs in Repair
The LLMs demonstrated the capability to repair vulnerabilities in synthetic scenarios with high success rates. However, in real-world contexts, while some bugs were effectively addressed, the complexity of changes needed often exceeded model capabilities without fine-tuned adjustments.
Challenges and Considerations
- Prompt Complexity: Effective zero-shot repair hinges on the ability to contrive prompts that coerce LLMs into producing viable, secure code fragments.
- Code Context Limitations: Realistic applications showed the constraints of current LLM token limits, suggesting the need for architecture advancements to handle larger code contexts.
Reliability Assessment
While LLMs showed potential, especially with local fixes, comprehensive adoption in development workflows requires improvements in model reliability, security assurance, and prompt engineering strategies.
Conclusion
The examined approach presents promising use cases for LLMs in automated security repair, highlighting both the potential and the need for further refinement in AI-assisted code repair paradigms. As the frameworks around LLMs evolve and computational resources improve, their utility in developing secure software will follow suit, creating robust, AI-driven solutions for software vulnerability management.