- The paper introduces self-normalized importance sampling, simplifying softmax normalization in neural language models by eliminating extra correction steps.
- It compares variants that include or exclude target classes and demonstrates competitive perplexity and WER against methods like NCE.
- Experimental results on datasets like Switchboard and Librispeech show improved training efficiency and strong performance in ASR applications.
Self-Normalized Importance Sampling for Neural Language Modeling
Introduction
The paper "Self-Normalized Importance Sampling for Neural Language Modeling" (2111.06310) presents advancements in sampling-based training criteria for neural LMs, specifically addressing the inefficiencies of traversing large vocabularies during softmax normalization. Neural LMs, which consistently outperform count-based methods in terms of perplexity, encounter challenges in efficient training and testing due to large vocabulary sizes. This study builds on previous work by proposing self-normalized importance sampling, which negates the need for additional correction steps to recover intended class posteriors, thus simplifying the training procedure while maintaining competitive performance in both research and production automatic speech recognition (ASR) tasks.
Methodology
The methodology involves comparing various sampling-based training criteria such as Binary Cross Entropy (BCE), @@@@1@@@@ (@@@@3@@@@), and Importance Sampling (IS). The paper identifies that IS lacks self-normalization by default; thus, several modifications are proposed to enable self-normalization directly:
- Mode 1 - Sampling including the Target Class: Subtracts the target term to exclude the target class from the summation, resulting in a self-normalized model output.
2. Mode 2 - Sampling excluding the Target Class: Uses a zero expected count for the target class during sampling to avoid the target class from being sampled.
- Mode 3 - Sampling excluding the Target Class: Employs a specific function that evaluates to zero when the target class is sampled, thus excluding it from the approximation.
These modifications aim to provide an approximation consistent with empirical posterior distribution p(c∣x), thus achieving self-normalization without the necessity of correction steps.
Experimental Results
Experiments conducted on datasets such as Switchboard, Librispeech, and an in-house English dataset demonstrate the effectiveness of self-normalized IS. The study evaluates models with perplexities and rescoring word error rates (WERs) following lattice rescoring protocols for ASR outputs. Notably, the self-normalized IS (Mode 3) shows competitive results compared to NCE across different datasets and sizes. The experimental results emphasize the advantage of self-normalized IS in training efficiency and performance parity with traditional scaling methods.
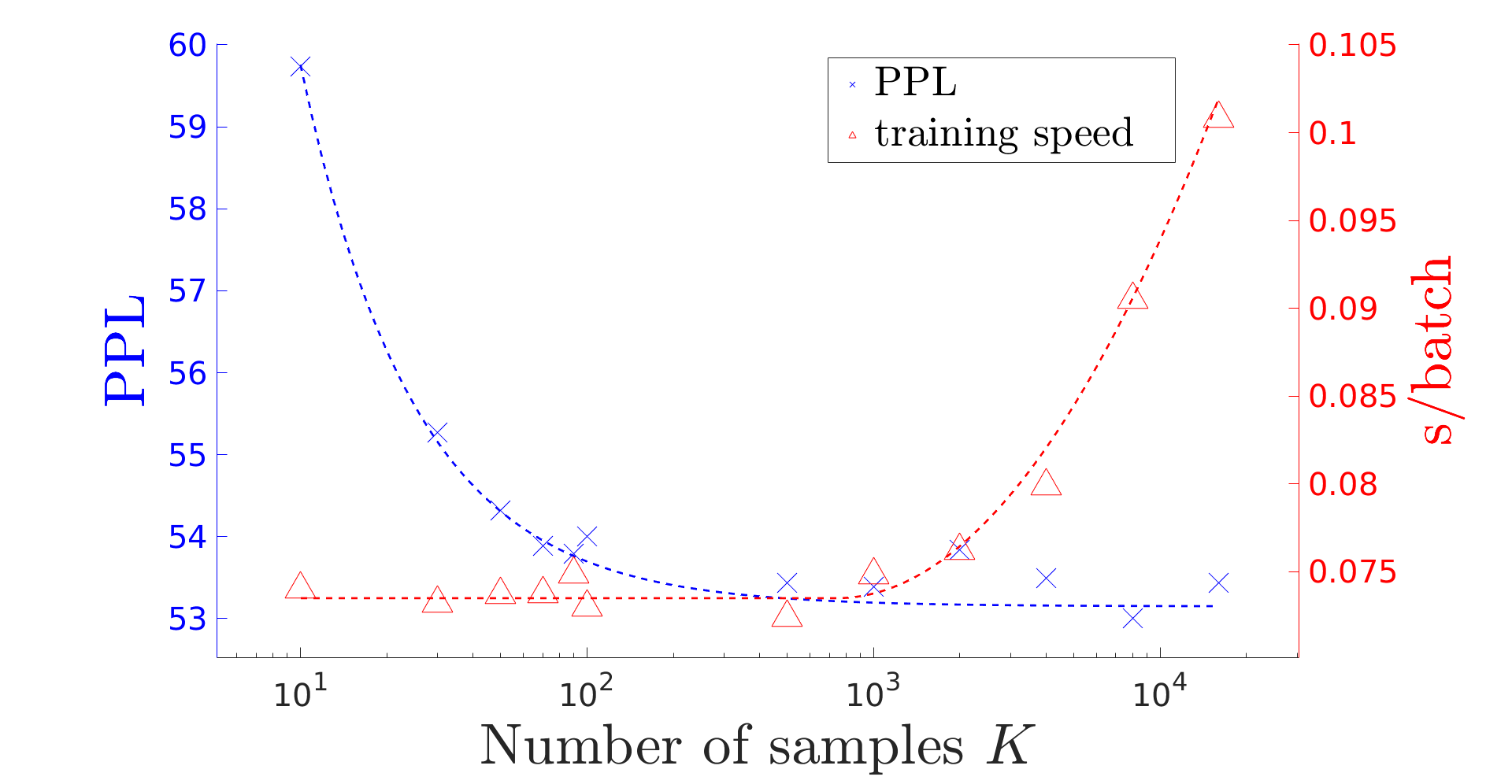
Figure 1: The influence of number of samples K.
The influence of sample number K reveals the trade-off between training speed and perplexity reduction, with larger K offering better approximation and reduced variance at the cost of training speed. Mode 3 is highlighted for its efficiency and competitiveness.
Implications and Future Developments
The implications of this research extend to practical deployment scenarios where training speed and model accuracy are paramount. The simplicity of the self-normalized method paves a path for efficient integration into production systems, particularly in tasks requiring extensive lexical coverage. Future developments may explore extensions to other types of LMs and broaden the scope to multilingual tasks, potentially enhancing generalization and robustness across diverse language corpora.
Conclusion
The paper establishes self-normalized importance sampling as a viable alternative to traditional sampling-based criteria like NCE, simplifying the training process while delivering competitive performance without additional correction steps. The demonstrated benefits in terms of training efficiency and competitive perplexity suggest promising avenues for broader application in neural language modeling and ASR contexts.