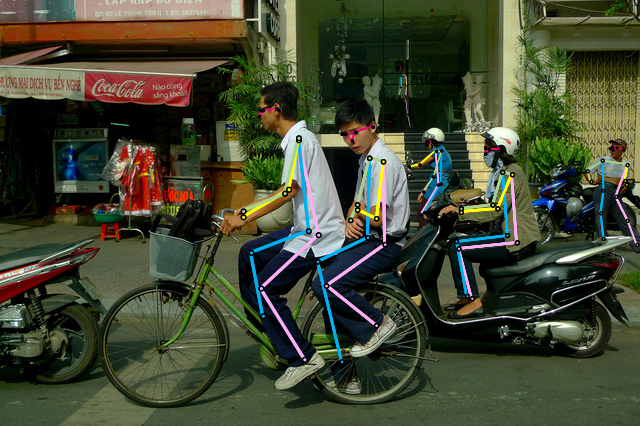HRFormer: High-Resolution Transformer for Dense Prediction
Published 18 Oct 2021 in cs.CV | (2110.09408v3)
Abstract: We present a High-Resolution Transformer (HRFormer) that learns high-resolution representations for dense prediction tasks, in contrast to the original Vision Transformer that produces low-resolution representations and has high memory and computational cost. We take advantage of the multi-resolution parallel design introduced in high-resolution convolutional networks (HRNet), along with local-window self-attention that performs self-attention over small non-overlapping image windows, for improving the memory and computation efficiency. In addition, we introduce a convolution into the FFN to exchange information across the disconnected image windows. We demonstrate the effectiveness of the High-Resolution Transformer on both human pose estimation and semantic segmentation tasks, e.g., HRFormer outperforms Swin transformer by $1.3$ AP on COCO pose estimation with $50\%$ fewer parameters and $30\%$ fewer FLOPs. Code is available at: https://github.com/HRNet/HRFormer.
The paper introduces HRFormer, a high-resolution transformer that combines HRNet's multi-resolution design with local-window self-attention for improved dense prediction tasks.
It leverages a multi-resolution architecture and incorporates 3×3 depth-wise convolutions in the FFN to enhance local feature exchange, reducing computational costs.
Experimental results demonstrate that HRFormer-B outperforms DeiT and HRNet with up to +1.2% mIoU gain and significantly fewer parameters and FLOPs.
HRFormer: High-Resolution Transformer for Dense Prediction
The paper "HRFormer: High-Resolution Transformer for Dense Prediction" (2110.09408) introduces a novel High-Resolution Transformer (HRFormer) designed to generate high-resolution representations for dense prediction tasks. HRFormer addresses the limitations of Vision Transformers (ViTs), which typically produce low-resolution representations and incur high computational costs. By integrating the multi-resolution parallel design of high-resolution convolutional networks (HRNets) and local-window self-attention mechanisms, HRFormer achieves improved memory and computational efficiency. Furthermore, the incorporation of convolution within the feed-forward network (FFN) facilitates information exchange across disconnected image windows, enhancing the model's ability to capture fine-grained spatial details.
Architecture and Implementation Details
The HRFormer architecture is based on the multi-resolution parallel design of HRNet, which maintains high-resolution streams throughout the network while incorporating parallel medium- and low-resolution streams to enhance high-resolution representations. The architecture of HRFormer is illustrated in (Figure 1).
Figure 1: The multi-resolution parallel transformer modules are marked with light blue color areas.
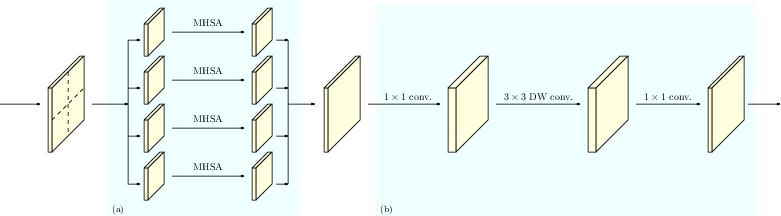
The first stage of HRFormer employs convolution, while subsequent stages utilize transformer blocks. Each transformer block consists of a local-window self-attention mechanism followed by an FFN with a 3×3 depth-wise convolution. Local-window self-attention reduces computational complexity by partitioning feature maps into non-overlapping windows and performing self-attention within each window independently. The depth-wise convolution in the FFN enables information exchange between these disconnected windows, expanding the receptive field. The HRFormer block is illustrated in (Figure 2).
Figure 2: The HRFormer block is composed of (a) local-window self-attentionm, and (b) feed-forward network (FFN) with depth-wise convolution.
where Xp is the input feature map, Wqh, Wkh, and Wvh are the query, key, and value projection matrices, respectively, H is the number of heads, D is the number of channels, and Xp is the output representation of MHSA.
Experimental Results
The paper presents experimental results on image classification, pose estimation, and semantic segmentation tasks. On ImageNet classification, HRFormer-B achieves a +1.0% top-$1$ accuracy improvement over DeiT-B with 40% fewer parameters and 20% fewer FLOPs. For COCO pose estimation, HRFormer-B outperforms HRNet-W48 by 0.9% AP with 32% fewer parameters and 19% fewer FLOPs. On PASCAL-Context test and COCO-Stuff test, HRFormer-B + OCR gains +1.2% and +2.0% mIoU over HRNet-W48 + OCR, respectively, with 25% fewer parameters. Example results for pose estimation and semantic segmentation are shown in (Figure 3) and (Figure 4).
Figure 3: Example results of HRFormer-B on COCO pose estimation val.
Figure 4: Example results of HRFormer-B + OCR on Cityscapes val, COCO-Stuff test, and PASCAL-Context test.
Ablation studies demonstrate the importance of the 3×3 depth-wise convolution within the FFN, which enhances locality and enables interactions across windows. HRFormer also outperforms ViT and DeiT on pose estimation tasks with fewer parameters and FLOPs. Visualization of the pose estimation and semantic segmentation results based on HRFormer-B on COCO val are shown in (Figure 5) and (Figure 6).
Figure 5: Visualization of the pose estimation results based on HRFormer-B on COCO val.
Figure 6: Visualization of the semantic segmentation results based on HRFormer-B + OCR on Cityscapes val, PASCAL-Context test, and COCO-Stuff test.
Conclusion
The HRFormer architecture presents a compelling approach to dense prediction tasks by combining the strengths of both Transformers and CNNs. The multi-resolution design, local-window self-attention, and depth-wise convolution mechanisms contribute to improved performance and efficiency across various vision tasks. The results suggest that HRFormer can serve as a robust backbone for future research in dense prediction and other vision applications.