- The paper presents a novel ensemble method that leverages character n-grams with sequence-to-sequence models for post-OCR correction.
- The methodology includes dividing documents into overlapping n-grams and merging corrections using a weighted voting scheme to improve accuracy.
- Experimental evaluations demonstrate state-of-the-art results in multiple languages, highlighting the approach’s efficiency and scalability.
Post-OCR Document Correction with Large Ensembles of Character Sequence-to-Sequence Models
Introduction
The task of post-OCR document correction is vital in improving the accuracy of text scanned using Optical Character Recognition (OCR), particularly in historical documents that present unique challenges in vocabulary, typography, and layout. While modern neural network approaches, particularly sequence-to-sequence models, have advanced text correction substantially, handling long sequences in a resource-efficient manner remains a barrier. The presented study addresses these challenges by introducing a strategy that processes documents using character-based sequence-to-sequence models, assembling their outputs through a robust ensemble approach.
Methodology
The core innovation of this approach is the use of character n-grams for correcting text sequences. Instead of processing document sequences in their entirety, which is computationally dense, this method leverages n-grams, allowing parallel processing and thereby improving efficiency. The segmentation of documents into n-grams is followed by individual n-gram correction using a pre-trained Transformer model.
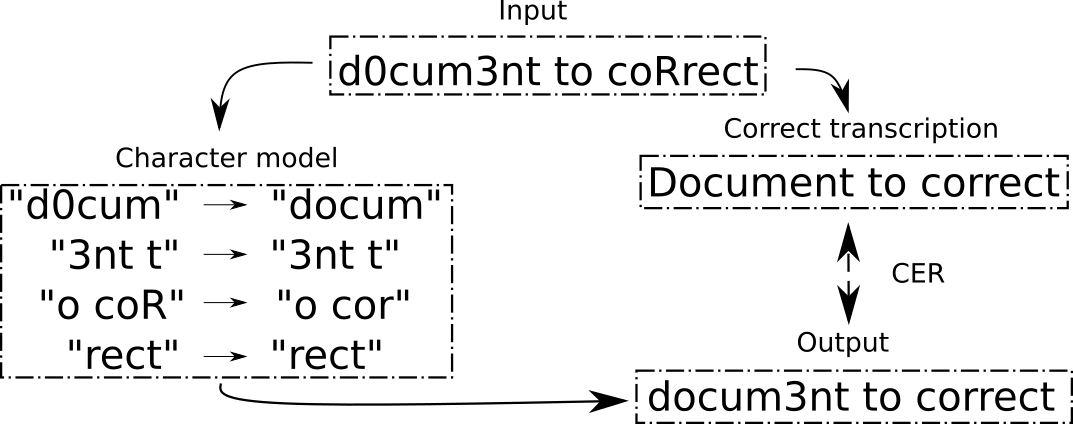
Figure 1: An example of correcting a document using disjoint windows of length 5.
Sequence Model
A standard Transformer-based sequence-to-sequence model is employed, trained on aligned text pairs extracted from the raw OCR and their correct transcriptions. Through this model, the input sequences are corrected to better align with their correct versions.
Document Correction
At inference time, documents are divided into overlapping n-grams, alleviating context-based errors at window boundaries. These corrected segments are then merged using a voting scheme, weighted based on their positions within n-grams. This ensemble effectively acts as multiple sequence models applying corrections over the document.
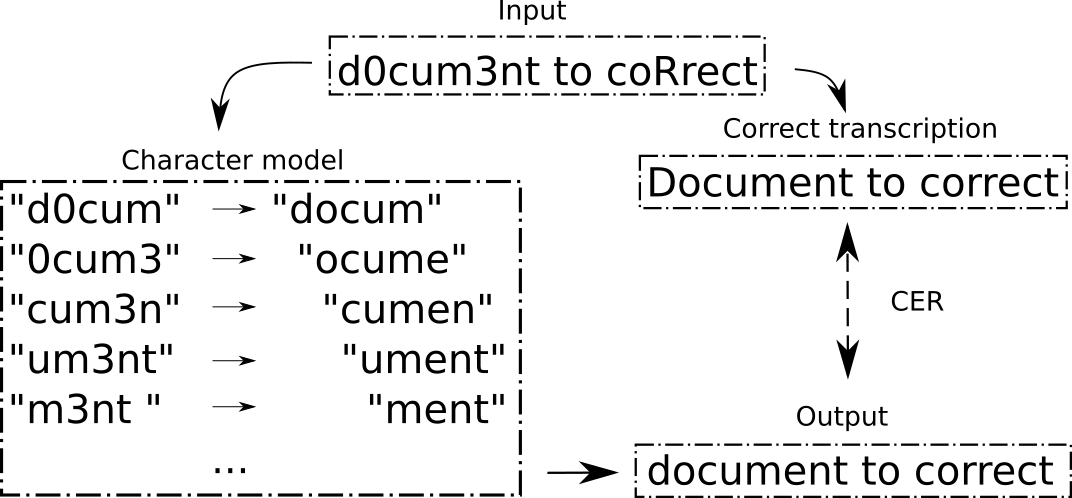
Figure 2: An example of correcting a document using n-grams of length 5.
Experimental Setup
The authors evaluated the approach on datasets from the ICDAR 2019 competition, spanning nine languages. Training involved pre-aligning OCR outputs with ground truth using character-based pairs, with n-gram lengths judiciously chosen to balance context and computational feasibility.
Results and Discussion
The ensemble method achieved new state-of-the-art performance in five languages: Bulgarian, Czech, German, Spanish, and Dutch. Notably, robust improvements were noted in languages with varied linguistic characteristics and document types, though less improvement was seen in French due to unique dataset properties. The method exhibited minor sensitivity to weighting functions, indicating that even simple uniform weighting could provide competitive results.
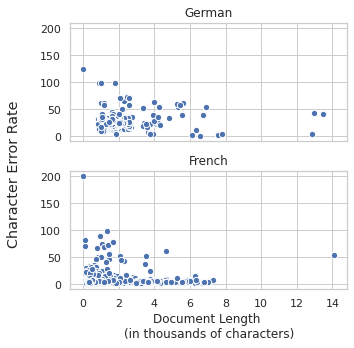
Figure 3: Distribution of the length in characters against the Character Error Rate for each document in the German and French datasets.
The analysis suggests that increasing window size does not consistently yield better performance, with disparities potentially arising from language-specific characteristics. Greedy Search, offering computational speed, sometimes surpassed Beam Search, challenging traditional expectations regarding search-based refinement in sequence models.
Conclusions
This research demonstrates an efficient, scalable method for post-OCR correction harnessing character-based models. By adopting n-gram parallelism and ensemble techniques, the approach enhances correction accuracy without extensive computational overhead. Future extensions might explore applicability to other domains such as Automatic Speech Recognition, where sequence alignment challenges persist.
The findings promote scalable document correction, broadening the potential for resource-constraining environments and diverse linguistic applications.

