AI Descartes: Combining Data and Theory for Derivable Scientific Discovery
Published 3 Sep 2021 in cs.AI | (2109.01634v4)
Abstract: Scientists have long aimed to discover meaningful formulae which accurately describe experimental data. A common approach is to manually create mathematical models of natural phenomena using domain knowledge, and then fit these models to data. In contrast, machine-learning algorithms automate the construction of accurate data-driven models while consuming large amounts of data. The problem of incorporating prior knowledge in the form of constraints on the functional form of a learned model (e.g., nonnegativity) has been explored in the literature. However, finding models that are consistent with prior knowledge expressed in the form of general logical axioms (e.g., conservation of energy) is an open problem. We develop a method to enable principled derivations of models of natural phenomena from axiomatic knowledge and experimental data by combining logical reasoning with symbolic regression. We demonstrate these concepts for Kepler's third law of planetary motion, Einstein's relativistic time-dilation law, and Langmuir's theory of adsorption, automatically connecting experimental data with background theory in each case. We show that laws can be discovered from few data points when using formal logical reasoning to distinguish the correct formula from a set of plausible formulas that have similar error on the data. The combination of reasoning with machine learning provides generalizeable insights into key aspects of natural phenomena. We envision that this combination will enable derivable discovery of fundamental laws of science and believe that our work is an important step towards automating the scientific method.
The paper introduces a hybrid system that integrates symbolic regression with automated theorem proving to generate scientifically derivable models.
It computes reasoning-based quality metrics alongside traditional data-fit errors to ensure models are both accurate and logically consistent.
It validates the approach on Kepler’s Third Law, relativistic time dilation, and Langmuir isotherms, demonstrating improved model generalization and robustness.
A Principled Synthesis of Data and Domain Knowledge for Automated Scientific Discovery
Overview of the Methodological Framework
The paper "AI Descartes: Combining Data and Theory for Derivable Scientific Discovery" (2109.01634) presents a novel framework for automatizing scientific law discovery by tightly integrating symbolic regression (SR) and formal logical reasoning. Unlike canonical SR systems, which select hypotheses based solely on fit to data and inductive biases like simplicity, this system prioritizes derivability from background theory—expressed as first-order logical axioms with arithmetic—thus bridging the gap between empirical data fitting and deduction from first principles.
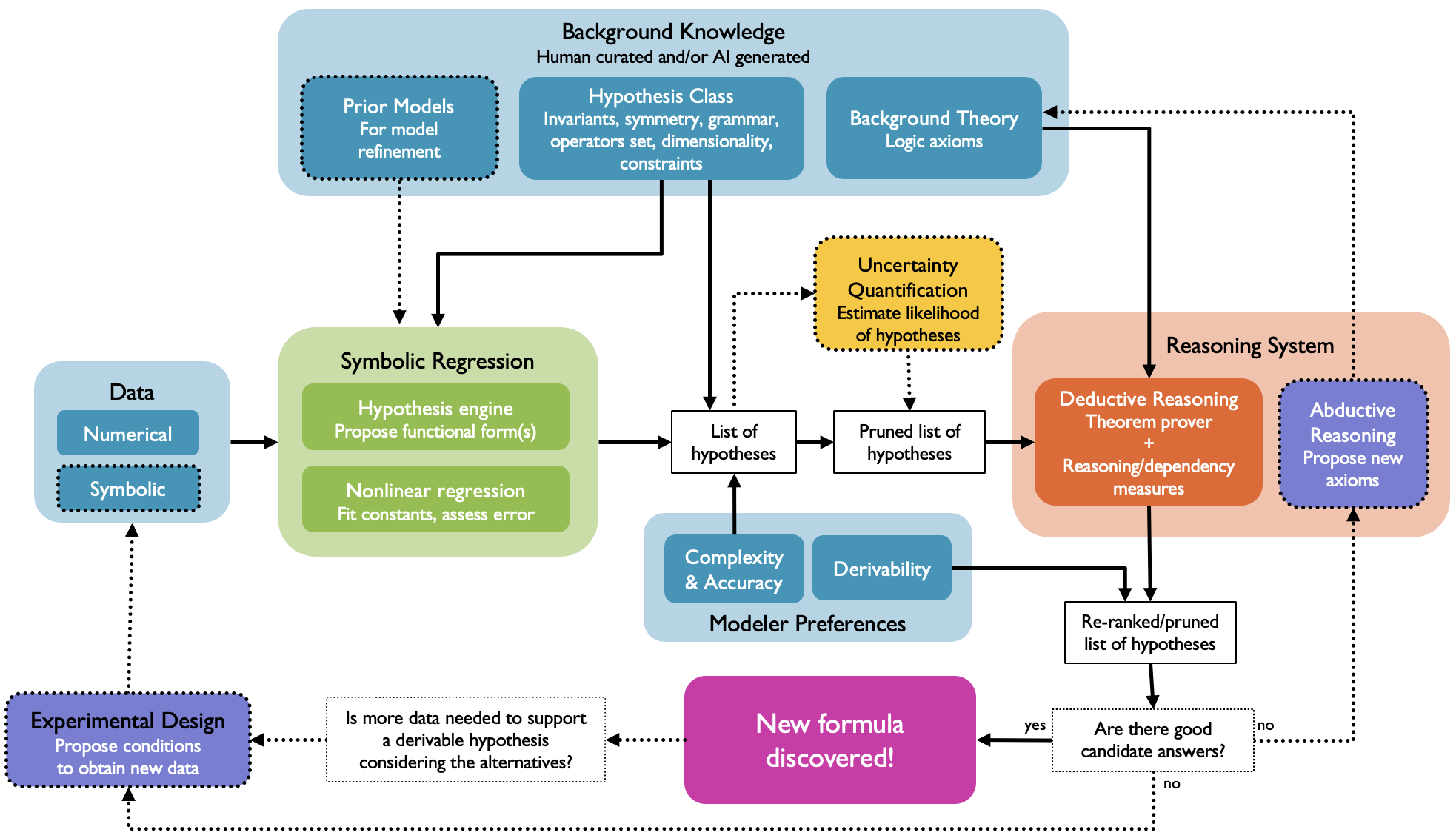
The overall pipeline involves four inputs: a background theory (axiom set B), a symbolic hypothesis class C, empirical data D, and modeler preferences M. The SR module first generates a pool of candidate symbolic models that fit the provided data within pre-specified error and complexity bounds. Each candidate is then passed into a deductive reasoning system, which determines if the candidate is derivable from B. If no candidate is derivable, reasoning-based metrics, such as distance to the set of derivable formulas, generalization error over extended variable domains, and variable dependence, are computed to inform subsequent iteration—either by refining data, axioms, or constraints.
Figure 1: Overview of the hybrid pipeline, uniting symbolic regression and automated theorem proving, with solid lines denoting implemented system modules.
Key Technical Contributions
Integration of Symbolic Regression and Automated Theorem Proving
This work leverages a novel MINLP-based symbolic regression engine that circumscribes hypothesis generation by not only error minimization but also enforces dimensional consistency and user-imposed invariance constraints. This is coupled with KeYmaera X, a hybrid systems theorem prover, to algorithmically check derivability or produce formal proofs of inconsistency. Notably, this pipeline can also return counterexamples demonstrating that a candidate cannot be derived from axioms, thus offering a path to automated scientific refutation.
Reasoning-Based Quality Measures
A central advance is the formalization of reasoning error metrics (β), which quantify the distance between candidate models and functions derivable from background theory, as a complement to classical data-fit error (ε). Both pointwise and generalized reasoning errors are used to assess not only the interpolation power of models but also their anticipated performance outside the observed data manifold—crucial for physical extrapolation and model selection in domains where ground truth is accessible only through axioms.
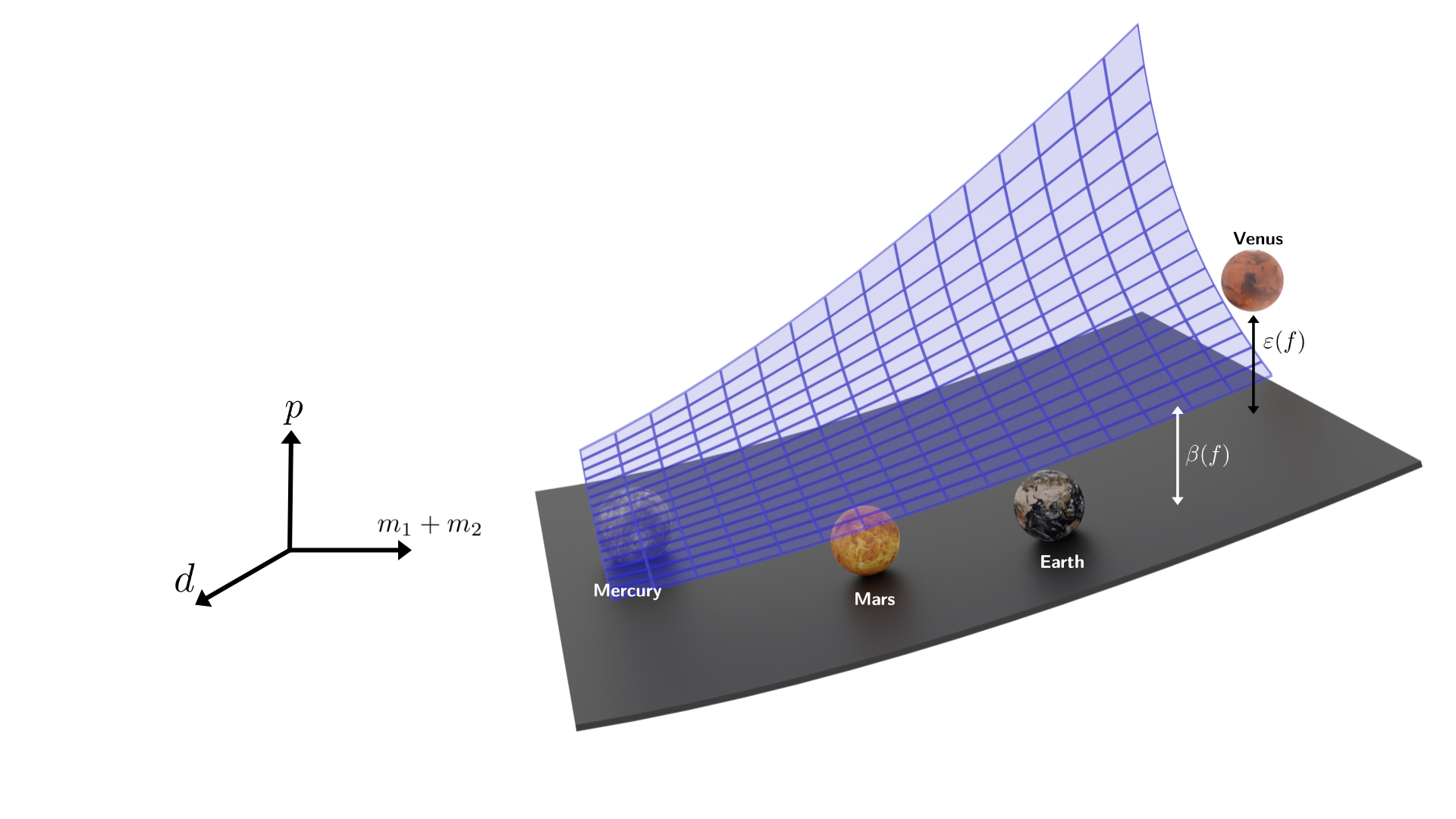
Figure 2: Illustration of how empirical data, theoretical background (Newton’s laws), and discovered models are situated with respect to the true derivable law for Keplerian motion.
Empirical Validation and Strong Results
The framework is validated on three archetypal scientific laws:
Kepler's Third Law: Despite multiple candidate expressions exhibiting commensurate data-fit errors, only those models that retain mass and distance dependencies consistent with Newtonian gravity theory are validated by logical reasoning. For the binary star dataset, the derived model p=d3/(0.9967m1+m2) is identified as both data-faithful and derivable, correctly generalizing across orders of magnitude in physical parameters.
Relativistic Time Dilation: Data alone is insufficient to recover the full form of Einstein’s time dilation law; however, the deductive module discards nonphysical candidates, and crucially, distinguishes between Newtonian versus relativistic axiom sets by finding high reasoning error for the former, thereby automating selection among competing theoretical explanations based on data.
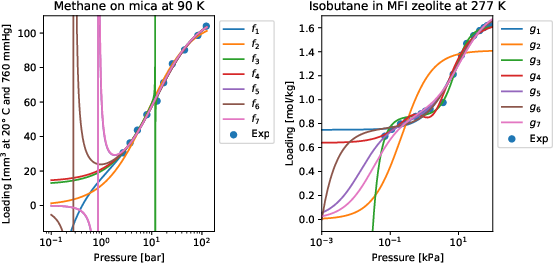
Langmuir Adsorption Isotherms: For adsorption in chemical engineering, the system recovers forms equivalent to Langmuir’s single- and two-site isotherms and is able to formally establish (via existential quantification over coefficients) logical derivability from the underlying kinetic and equilibrium axioms, ruling out data-fitting artifacts that violate physical monotonicity or limiting behavior.
Figure 3: Symbolic regression outputs for adsorption datasets, with models f2, g2 (single-site) and g5, g7 (two-site Langmuir) verified as consistent with background chemical theory.
Strong numerical outcomes are observed, such as reasoning errors in the 10−3 to 10−5 range and explicit identification of variable dependencies with generalization reasoning error quantifying true extrapolation robustness. Notably, models selected by pointwise data error alone frequently lack in-domain or variable robustness, highlighting the necessity for the deductive component.
Implications and Comparative Analysis
This approach fundamentally shifts the paradigm of automated scientific discovery from heuristic selection among black-box models to certified derivability from theory. Compared to other SR systems (e.g., AI-Feynman, PySR, BMS), the AI Descartes pipeline is able to outperform on the Feynman Symbolic Regression Database in noisy, small-sample regimes—achieving 60.49% exact or near-exact identification rates vs. 40-49% for strong baselines. More importantly, only this framework is able to certifylogical consistency with background science, addressing both overfitting and the risk of spurious correlations in the data.
Critically, the analysis shows that reasoning-based selection consistently identifies physically correct laws from the set of nearly-error-equivalent candidates, whereas other systems may select spurious or underconstrained expressions.
Limitations and Directions for Extension
The system’s applicability is bounded by the expressivity and completeness of the formalized background theory and the tractability of current ATPs for arithmetic-rich theories. The authors note the exponential scaling of both MINLP enumeration and symbolic logic reasoning; proofs involving higher-order logic, calculus beyond ODEs in time, or axioms requiring nontrivial abductive closure are challenging. The limited availability of machine-readable scientific axioms further constrains applicability. Emerging solutions may include semi-automated axiom extraction from structured scientific documents, and using machine learning to guide clause selection or support abduction for theory augmentation.
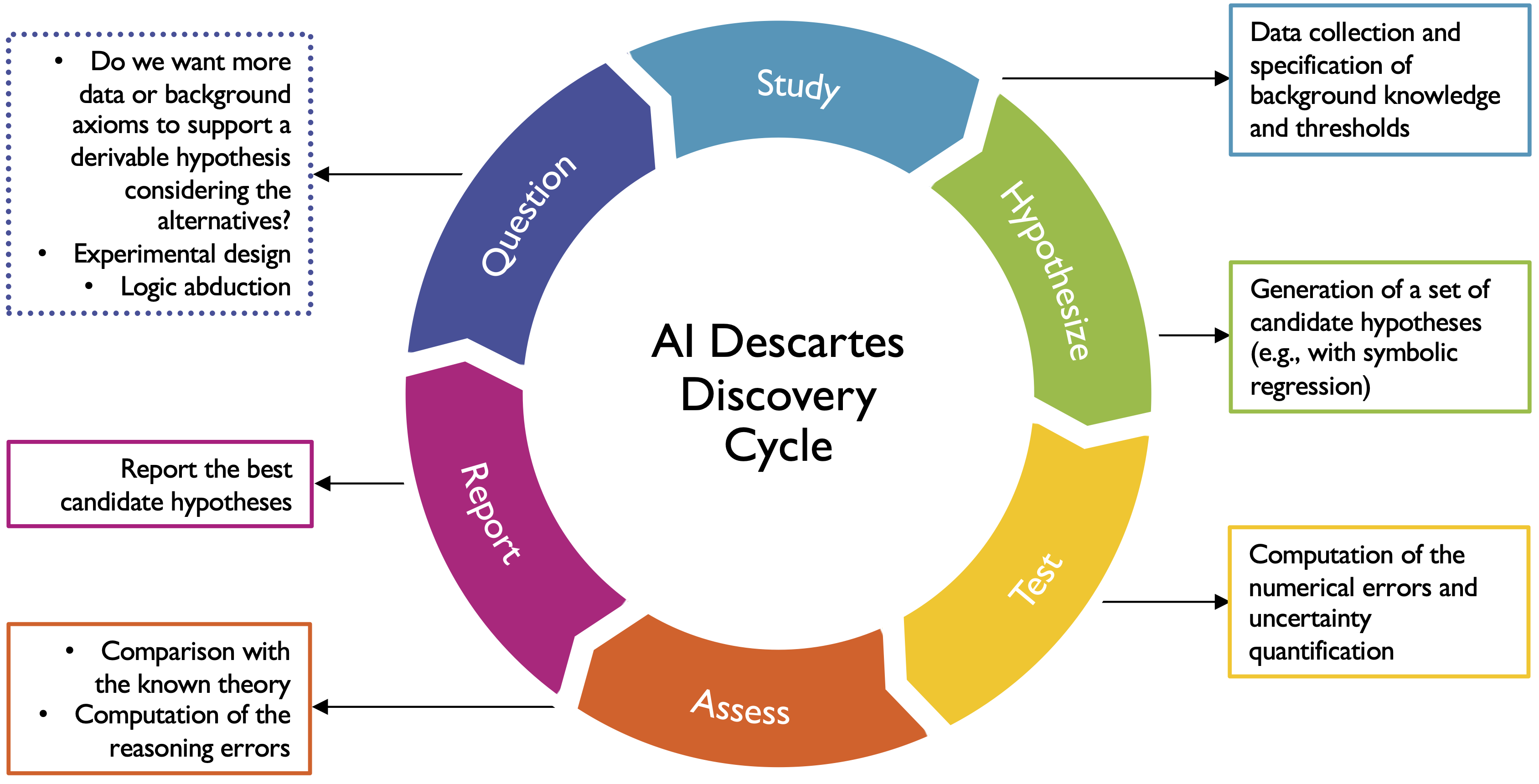
Future research will focus on deeper integration of experimental design modules, advanced abductive reasoning, and hybrid neuro-symbolic architectures for theorem proving, which may help overcome current algorithmic bottlenecks and generalize to new scientific domains.
Figure 4: Depiction of the iterative scientific discovery process in the system, aligning modern cycle with Descartes' logic-centric epistemology, and future avenues such as abduction and experimental design.
Conclusion
This work demonstrates that the union of symbolic regression and formal logical reasoning yields a general, robust architecture for automated scientific discovery: one that is both data-driven and deductively sound. The system’s ability to output physically lawful, derivable, and generalizable expressions sets a new standard for machine-assisted science, with the broader implication that true AI scientists may eventually function as autonomous agents capable of both hypothesis generation and theoretical justification. Future improvements in theorem proving, axiom curation, and neuro-symbolic reasoning can be expected to further enrich this framework’s explanatory, unifying power and extend its reach across the scientific landscape.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.