- The paper introduces a framework that evaluates language models by comparing their output to natural language distributions such as Zipf's and Heaps' laws.
- Experiments show that model architecture and sampling strategies, like nucleus sampling, significantly influence adherence to empirical linguistic trends.
- Findings reveal that while transformers and LSTMs capture some statistical properties effectively, beam sampling yields poorer alignment overall.
LLM Evaluation Beyond Perplexity
Introduction
The paper "LLM Evaluation Beyond Perplexity" (2106.00085) presents an alternative approach to evaluating how well LMs learn natural language by examining the alignment of generated texts with the statistical tendencies of human language. This study dives deeply into various linguistic phenomena beyond traditional metrics such as perplexity, offering a framework for quantifying model adherence to empirical patterns. The investigation reveals that while LMs capture certain statistical aspects of language, this capability varies profoundly based on architectural and generational nuances.
Statistical Tendencies in LLMs
The authors aim to evaluate LMs by how closely the generated text aligns with known statistical laws and distributions of natural language, such as Zipf's law and Heaps' law, among other empirical tendencies.
Classical Laws
- Zipf's Law: The rank-frequency distribution of words in natural language typically follows Zipf's law, where frequency is inversely proportional to rank. The paper discusses the empirical adherence of model-generated text to this law.
- Heaps' Law: Describes the non-linear relationship between the number of unique words and document length. The assessment involves fitting a non-homogeneous Poisson process to model the type-token relationship.
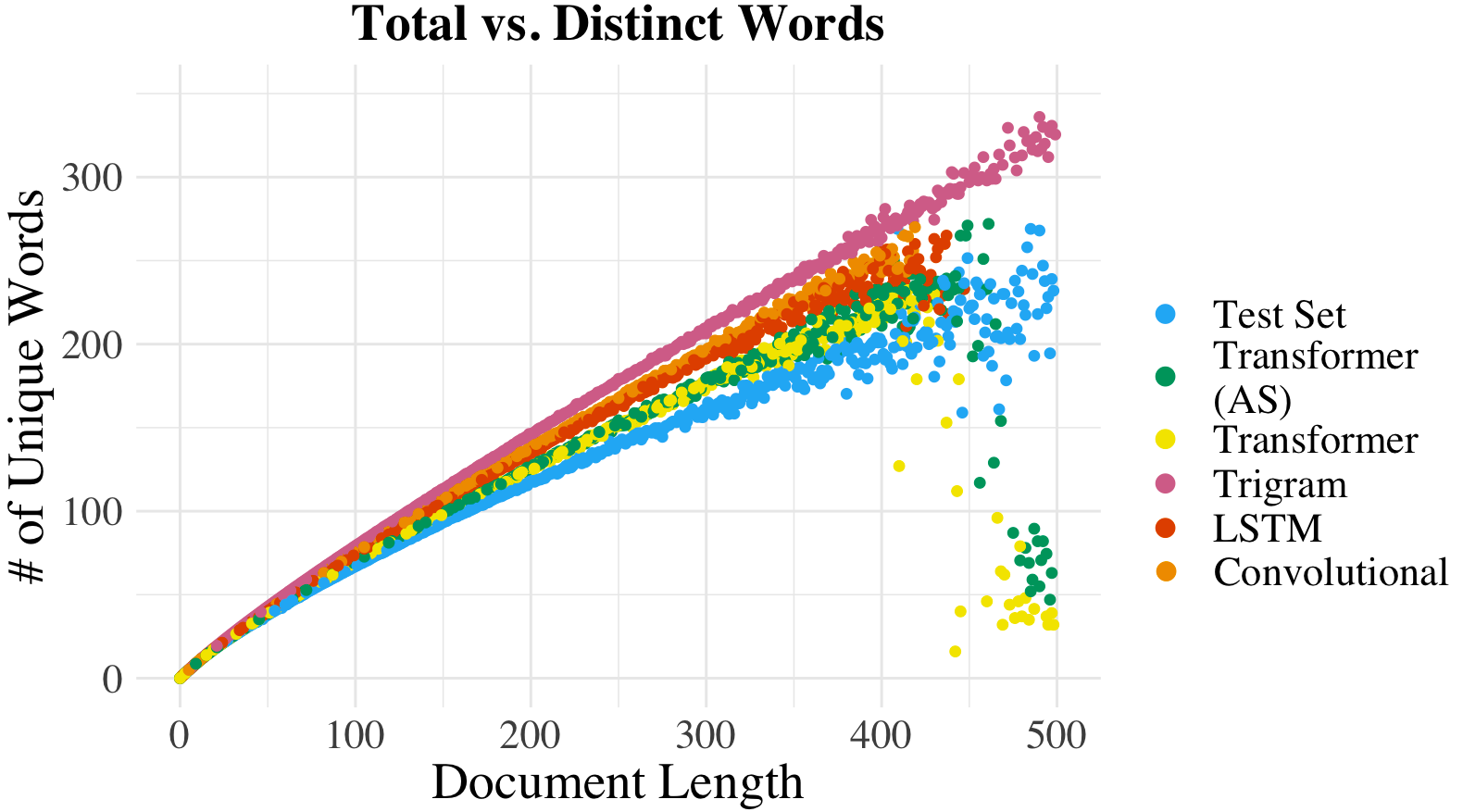
Figure 1: Average number of unique words vs. document length, i.e., type-token, in text sampled from LLMs. Values from models' test set are plotted for reference.
Other Tendencies
The authors extend their analysis to other text characteristics like length, stopwords, and symbols distribution. These factors do not have fixed theoretical laws and are assessed based on empirical distribution comparisons.
Statistical Distances
The study employs several probability metrics to quantify the fit between the LM-generated text and human language distributions, using:
- Kolmogorov-Smirnov (KS) Metric: Measures differences between empirical cumulative distribution functions (cdfs).
- Total Variation Distance (TVD): Evaluates discrepancies in probability distributions.
These metrics facilitate hypothesis testing, examining both the goodness of fit to known distributions and the model-generated versus naturally occurring empirical distributions.
Experiments and Results
Rank-Frequency
The empirical rank-frequency adherence to Zipfian distribution is measured with KS metrics. Results indicate that transformer and LSTM models align closely with natural language but deviate more significantly from an ideal Zipfian distribution.
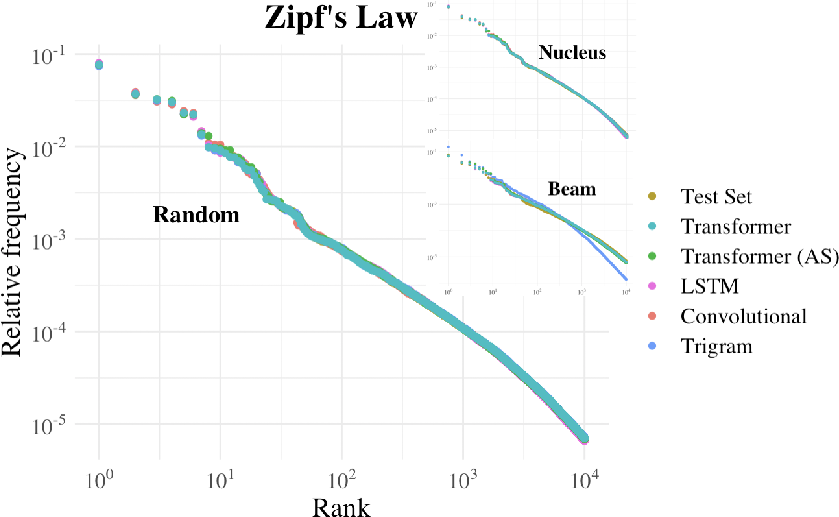
Figure 2: Rank-frequency distributions for different samples. All follow a remarkably similar trend.
Type-Token Relationship
The type-token trend is examined using KS metrics for varying document lengths. Transformer architectures with nucleus sampling demonstrate closer alignment with natural language type-token distributions.
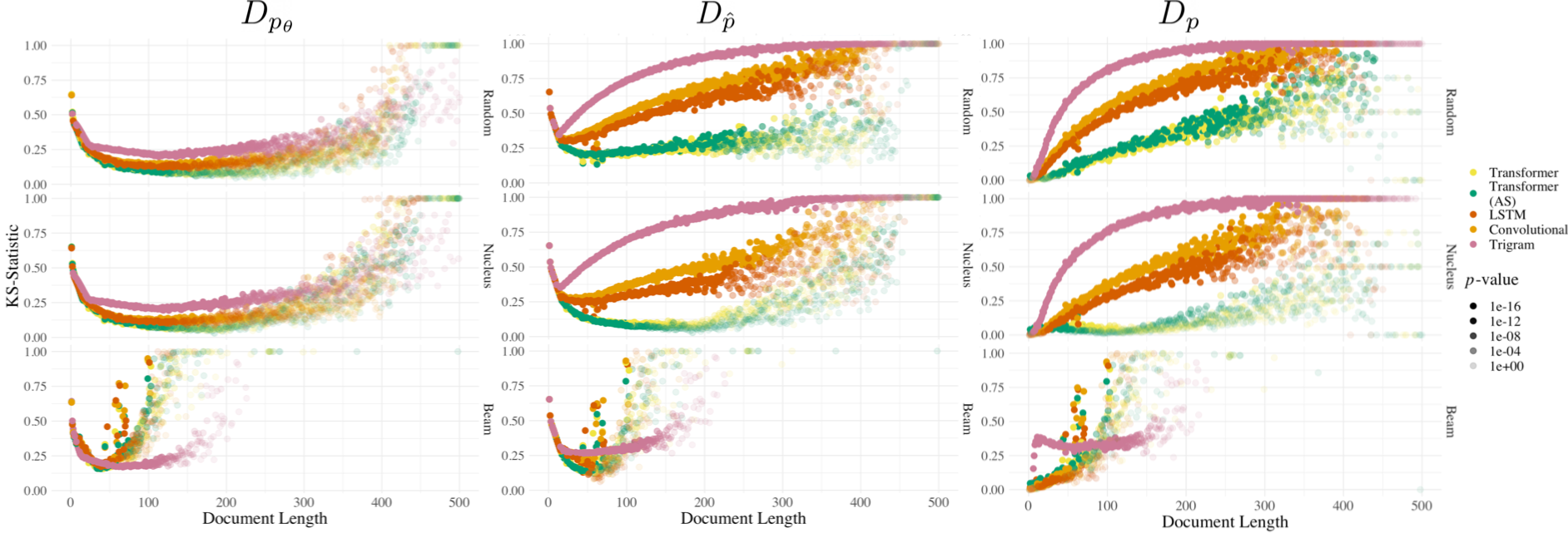
Figure 3: KS metrics (lower implies closer fit) with reference distributions for the type-token relationship as a function of document length.
Unigram, Length, Stopword, and Symbol Distributions
For unigram distributions, TVD indicates that most LMs capture natural language distribution effectively. Interestingly, LSTMs showcased notable fidelity to empirical distributions in length, stopwords, and symbols. However, beam sampling strategies typically exhibited poor alignment.
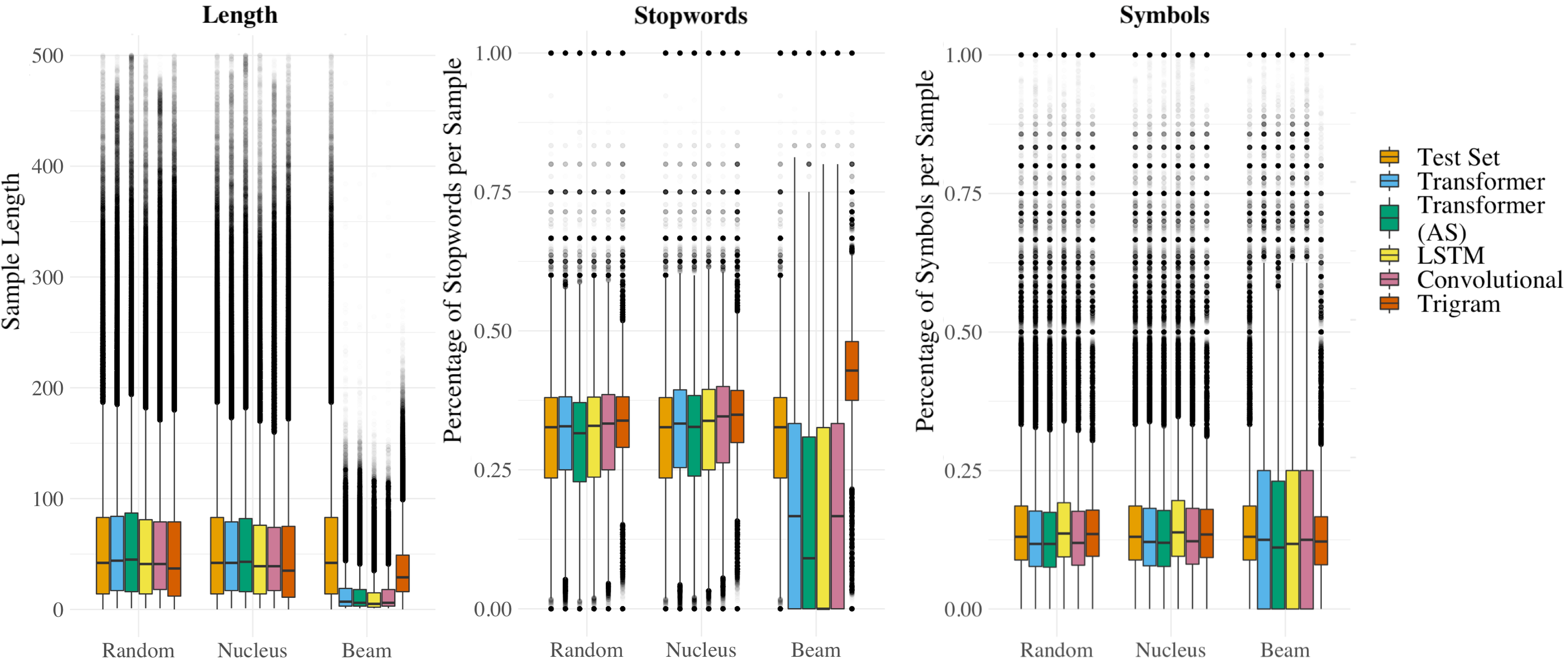
Figure 4: Boxplots showing the distribution of sample length and stopword and symbol percentages.
Discussion and Conclusion
The paper concludes that the selected methodology provides richer insights into an LM's proficiency in capturing natural language nuances compared to perplexity alone. The research illustrates that alignment with natural language distributions is contingent on model architecture and generation strategies. A key takeaway is the advantage in using techniques like nucleus sampling, which improve statistical adherence across several metrics.
Future studies could explore cross-linguistic analyses and the impact of dataset size on distribution alignment. Additionally, examining the correlation of these metrics with other evaluation methodologies may refine our understanding of a model's overall linguistic comprehension. The work underscores the limited scope of perplexity and proposes a more nuanced evaluation framework crucial for advancing LLM assessments.