- The paper introduces a semi-quantitative framework that identifies the optimal negative sample ratio in contrastive learning under noisy conditions.
- It proposes an adaptive negative sampling method that dynamically adjusts sample ratios during training to enhance model efficacy.
- Experimental analysis across diverse tasks confirms that medium negative sample counts yield superior performance compared to static sampling.
Rethinking InfoNCE: Optimal Number of Negative Samples
This essay provides an in-depth analysis of the paper titled "Rethinking InfoNCE: How Many Negative Samples Do You Need?" (2105.13003).
Introduction
The paper addresses the widely recognized InfoNCE loss function, pivotal for contrastive learning, which estimates mutual information between variable pairs by distinguishing positive samples from associated negative samples. The exploration is driven by a core observation: although augmenting negative samples tightens the lower-bound mutual information estimation under clean labels, real-world datasets frequently contain noise. Misleading gradients from excessive noisy samples hinder model learning efficacy. The authors propose a semi-quantitative framework to discern optimal negative sample ratios under various scenarios, furthering this proposition with an adaptive negative sampling method enhancing InfoNCE-based model training.
Proposed Framework
The authors establish a probabilistic model assessing the impact of the negative sampling ratio K. A critical aspect involves measuring sample informativeness through a training effectiveness function, identifying the K value that optimizes this metric. Grounded in this framework, an adaptive negative sampling method is proposed, adjusting the sampling ratio dynamically across training phases, thereby optimizing model performance.
Figure 1: Results and predictions on the news recommendation task. Gray dashed line represents the optimal K under lambda=0.9.
Experimental Analysis
Extensive experiments across diverse real-world datasets substantiate the framework's predictive accuracy regarding optimal negative sampling ratios. Notably, the empirical findings reinforce that model performance optimizes at a medium negative sample count, corroborating the theoretical predictions.
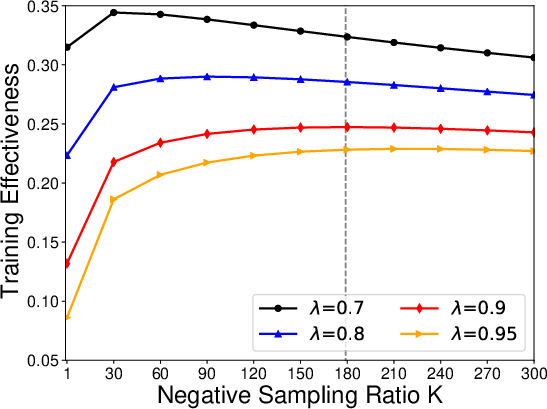
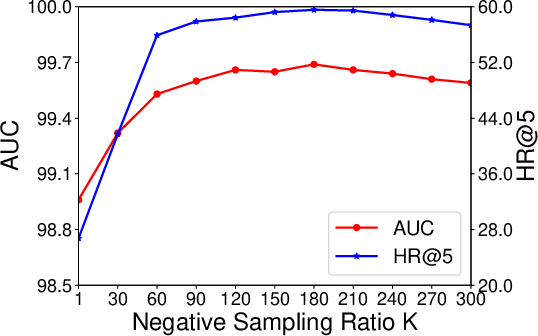
Figure 2: Results and predictions on the title-body matching task. Gray dashed line represents the optimal K under lambda=0.9.
Adaptive Negative Sampling (ANS) Method
The ANS method introduces a strategy to dynamically adjust the negative sampling ratio, thereby accommodating nuanced differences throughout model training stages. This method aims to mitigate the inefficacies of static sampling ratios and adaptively fine-tunes the sampling process through early and late training phases.
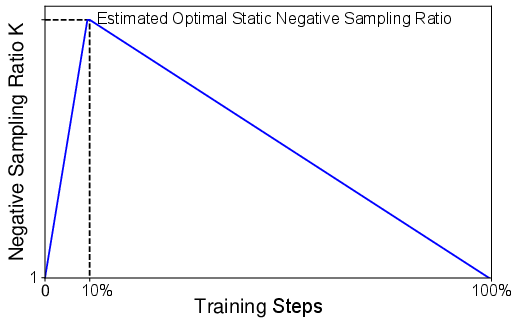
Figure 3: The curve of negative sampling ratio in the ANS method.
Implications and Future Directions
While the paper provides foundational insights into optimal negative sampling in InfoNCE contexts, several areas warrant further research. The empirical nature of tuning certain hyperparameters and the challenges in deriving closed-form solutions for key variables demand additional exploration. Moreover, potential biases inherent in datasets may propagate through contrastive learning under the proposed framework, necessitating further validation and calibration.
Conclusion
The paper presents a significant advancement in understanding and optimally applying negative samples within the InfoNCE framework of contrastive learning. The proposed semi-quantitative model and adaptive sampling method show promise in enhancing model efficacy across diverse tasks, headlining a flexible, theoretically grounded approach adaptable to varied training scenarios. Future work might explore refining parameter estimation processes and mitigating biases inherent in real-world applications.