- The paper presents a regret minimization framework that directly optimizes experience replay to enhance policy returns.
- It introduces ReMERN, a neural network-based method, and ReMERT, a temporal structure-based method, with detailed performance evaluations.
- Empirical results show superior performance on benchmarks like MuJoCo and Meta-World, highlighting significant advancements in RL.
Regret Minimization Experience Replay in Off-Policy Reinforcement Learning
The paper "Regret Minimization Experience Replay in Off-Policy Reinforcement Learning" introduces a novel approach aimed at optimizing experience replay strategies to minimize regret directly in reinforcement learning (RL) systems. This study seeks to improve upon existing methodologies by devising a strategy that better aligns with the ultimate objective of RL, which is to maximize policy return.
Introduction to Prioritization in Experience Replay
Experience replay is a critical component of off-policy RL algorithms, as it enables the reuse of past transitions, thereby enhancing sample efficiency. Traditional approaches, such as Prioritized Experience Replay (PER), prioritize samples based on temporal-difference (TD) error, and others like DisCor focus on corrective feedback. However, these methods are often heuristic and do not directly target the regret minimization goal of RL.
The Problem with Existing Methods
Existing prioritization strategies do not align perfectly with the RL objectives, often leading to suboptimal training processes. For instance, they may prioritize samples that do not necessarily contribute most effectively to policy improvement. This misalignment is exemplified in the case of PER and DisCor, both of which can slow down the convergence to optimal policies under certain conditions.
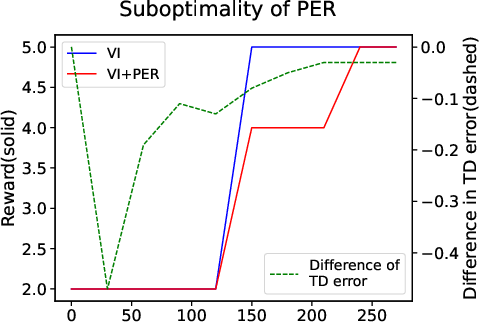
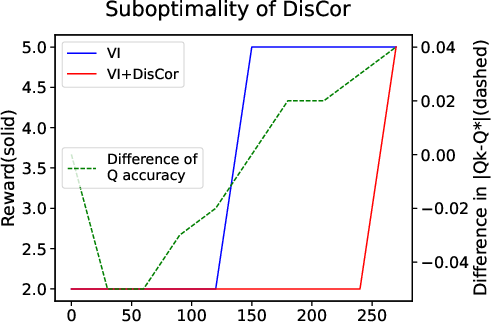
Figure 1: A simple MDP showing the objectives of PER and DisCor can slow down the training process. (a) Illustration of a 5-state MDP. (b) and (c) depict the relationship between TD or Q error and performance.
Developing an Optimal Prioritization Strategy
The core contribution of this paper is the formulation of a prioritization strategy that aims to minimize expected policy regret. The authors first formalize the optimization problem where the prioritization weight is designed to directly minimize regret by improving the sampling strategy from the replay buffer.
Theoretical Insights
The paper derives a theoretical framework that suggests prioritizing experiences with higher hindsight TD error, better approximation to Q-values, and greater on-policiness. This framework offers a coherent explanation for the partial effectiveness of existing methods while proposing a more comprehensive solution.
Implementation of ReMERN and ReMERT Methods
ReMERN: Neural Network-Based Estimate
ReMERN utilizes a neural network to estimate the cumulative Bellman error, which serves as a surrogate for the discrepancy between the estimated and true Q-values. The paper outlines the algorithmic steps required to implement ReMERN, emphasizing its robustness in environments with high randomness due to its reliance on dynamic programming techniques for error estimation.
ReMERT: Temporal Structure-Based Estimate
ReMERT leverages the temporal ordering of states to approximate Q-value accuracy. This method is computationally efficient as it does not require the additional overhead of training an error network. It excels in environments with stable state transitions due to its reliance on the temporal properties of trajectories.
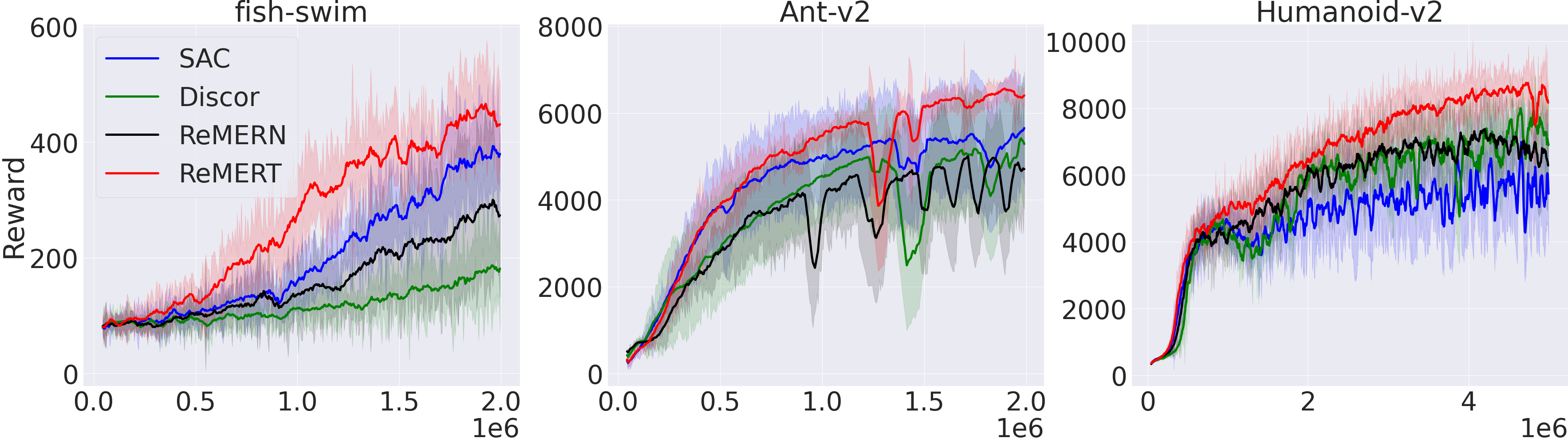
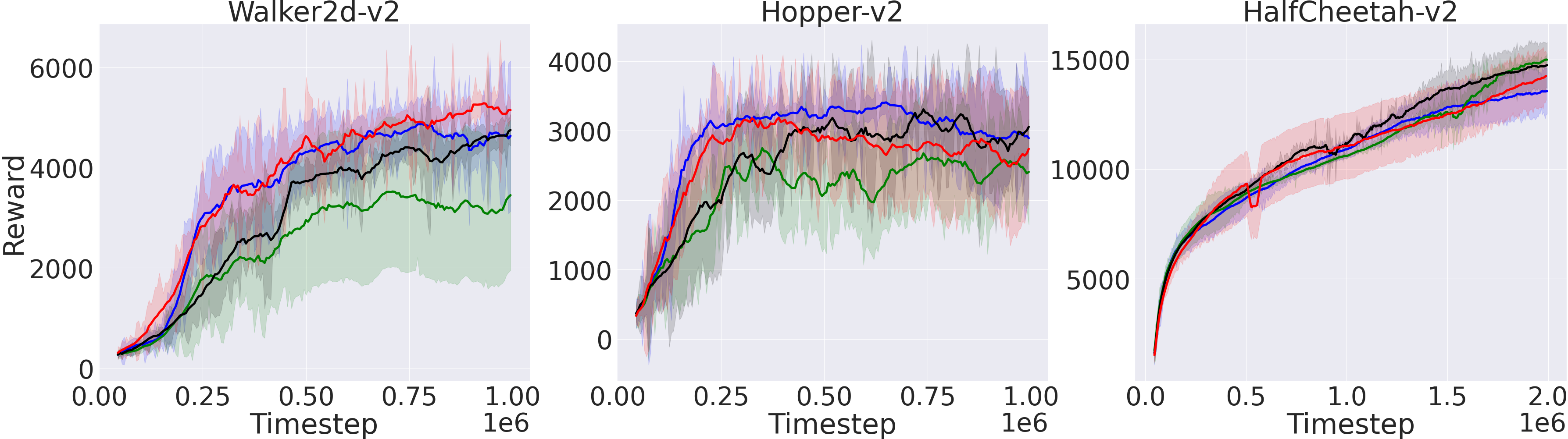
Figure 2: Performance of ReMERT, ReMERN with SAC and DisCor as baselines on continuous control tasks.
Comparative Evaluation and Empirical Results
The paper evaluates ReMERN and ReMERT across various benchmarks, including MuJoCo, Meta-World, and different Atari games. The empirical results demonstrate that both methods generally outperform standard algorithms like SAC and DQN, as well as prior sampling strategies such as PER and DisCor.
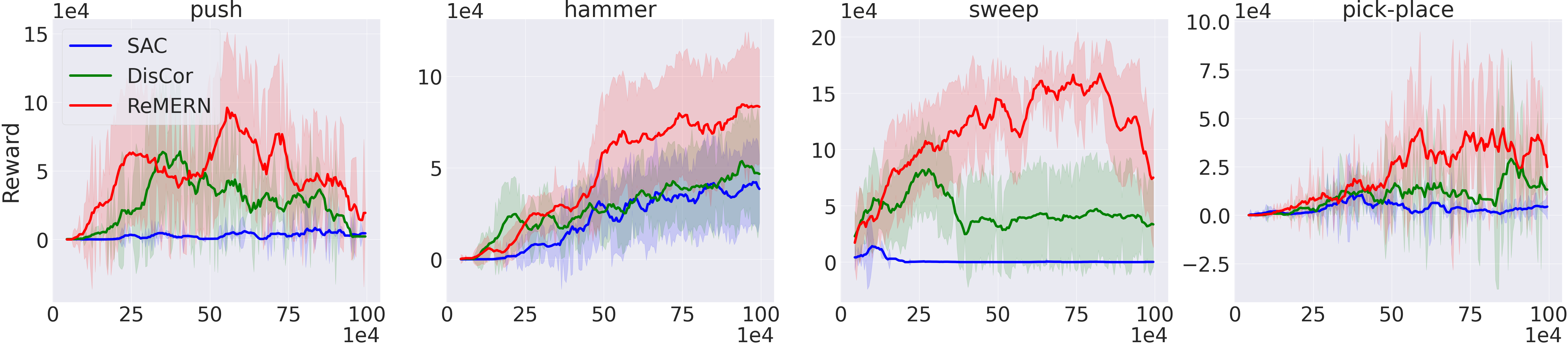
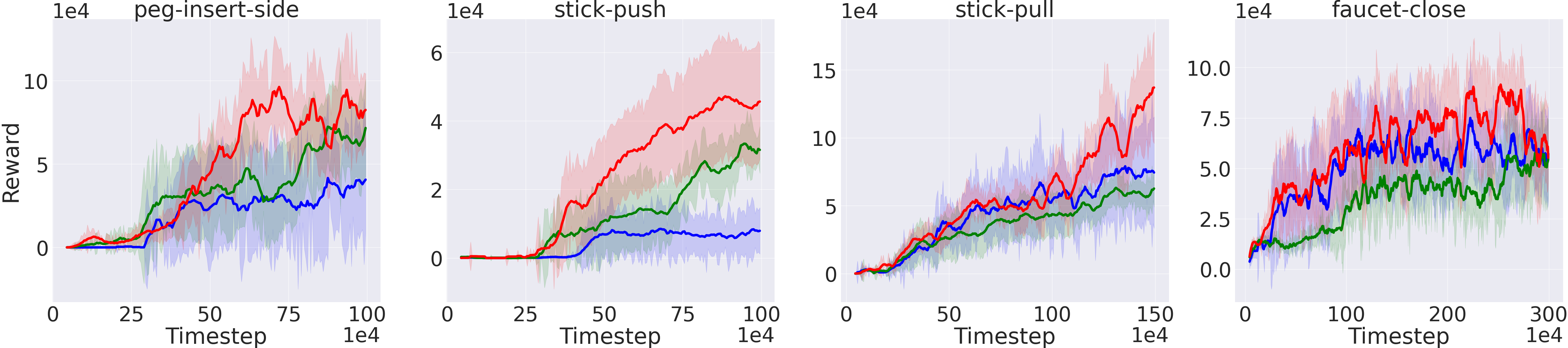
Figure 3: Performance of ReMERN, standard SAC and DisCor in eight Meta-World tasks.
Analysis of Estimation Strategies
The authors provide an in-depth analysis of when to utilize either ReMERN or ReMERT, taking into account factors like environmental randomness and computational resource constraints. While ReMERT offers more efficient computation in environments with stable sequences, ReMERN shows superior performance in variable environments due to its neural network-based estimation of errors.
Conclusion
The study advances the field of RL by presenting a theoretically grounded and practically effective approach to experience replay prioritization. By focusing directly on regret minimization, the proposed methods, ReMERN and ReMERT, present a significant advancement over previous heuristic-based methods. Future research directions include extending the framework to model-based and offline RL, as well as unifying the prioritization strategies into a hybrid approach adaptable to diverse MDPs.

