- The paper shows that prompt order substantially affects in-context few-shot performance, sometimes reducing accuracy to near-random levels.
- It introduces an entropy-based probing method that automatically identifies high-performing prompt permutations without requiring additional labeled data.
- Empirical results demonstrate robust improvements across various tasks and model sizes, highlighting a critical limitation in current in-context learning.
Overcoming Few-Shot Prompt Order Sensitivity in In-Context Learning
Introduction
The paper "Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity" (2104.08786) investigates a largely overlooked but impactful dimension of prompt engineering for in-context learning: the order sensitivity of few-shot prompts. The authors provide a rigorous analysis demonstrating that the ordering of training samples within a prompt can lead to drastic variations in performance, ranging from near state-of-the-art accuracy to levels indistinguishable from random guessing, even when using the same underlying model and data. They introduce a probing-based methodology leveraging the generative capabilities of LLMs to identify high-performing prompt permutations without requiring additional labeled data, achieving up to a 13% relative improvement across eleven text classification tasks.
Empirical Characterization of Prompt Order Sensitivity
Extensive experiments reveal that prompt order sensitivity is pronounced across different model sizes, task types, and dataset domains. For instance, with SST-2 sentiment classification and the Subj dataset, the same model exhibits performance from near-chance to competitive with fully supervised baselines solely due to sample ordering (see Figure 1).
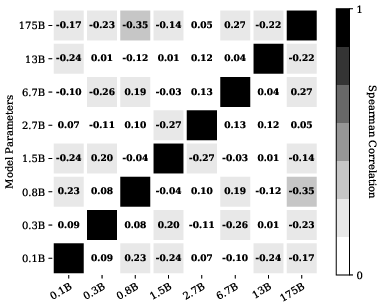
Figure 1: Training sample permutation performance correlation across different models, showing dramatic differences in outcome based on prompt ordering.
Increasing model size only marginally mitigates order sensitivity; even GPT-3 175B shows substantial variance for some tasks. Notably, the phenomenon persists regardless of the number of training samples and is not resolved by simply increasing data coverage. Thus, order sensitivity emerges as a persistent and fundamental challenge for in-context few-shot learning.
The authors further demonstrate that performant permutations for one model do not reliably transfer to another—even between closely related models (e.g., GPT-2 Large vs. GPT-2 XL), as evidenced by low Spearman's rank correlations (see Figure 1). Similarly, the relative ordering of label patterns (such as alternating positive/negative assignments) lacks consistency across models (see Figure 2).
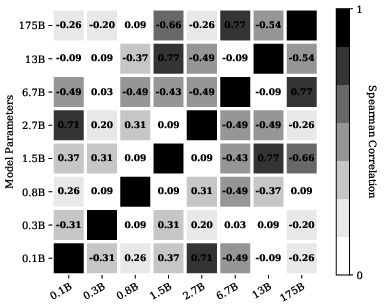
Figure 2: Training label pattern permutation performance correlation across different models, highlighting lack of transferability of good label orderings.
Error analysis shows that poor prompt permutations often yield highly skewed predicted label distributions, leading to degenerate output behaviors. Calibration techniques help but do not eliminate high variance (see Figure 3).
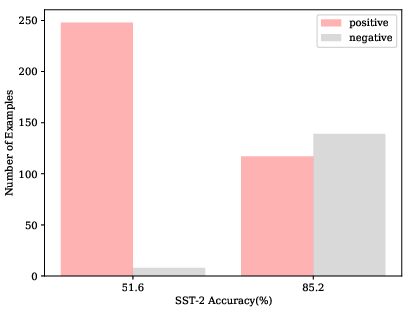
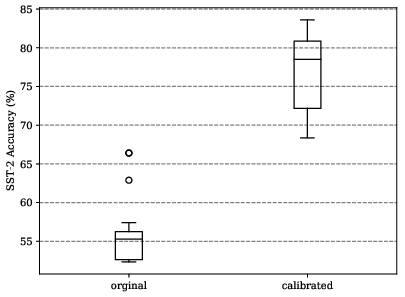
Figure 3: Left: Predicted SST-2 label distribution under different prompts. Right: 2-shot calibrated performance, illustrating persistent variance post-calibration.
Recognizing that brute-force development set selection is either impractical or fundamentally restricts the true few-shot setting, the paper proposes an automatic methodology for identifying good prompt permutations. The approach leverages the generative properties of LLMs to create an "artificial development set." Specifically, it involves:
- Enumerating all (or a random subset of) possible prompt orderings from the chosen few-shot samples.
- For each candidate permutation, using the LM to generate synthetic samples (probing set) reflecting the prompt's induced output distribution.
- Scoring each permutation using unsupervised metrics derived from the predicted label distribution over the probing set.
Two entropy-based metrics are introduced:
- Global Entropy (GlobalE): Measures the entropy of the predicted category distribution over the probation set for a given prompt ordering; high values indicate balanced, non-degenerate predictions.
- Local Entropy (LocalE): Computes the average entropy of individual sample predictions, penalizing overly confident or poorly calibrated outputs.
This ranking approach enables selection of prompt orders that circumvent degenerate behaviors without reliance on external labeled validation data.
Experimental Results and Numerical Findings
Across eleven standard text classification benchmarks (including SST-2, MR, Subj, TREC, AGNews, RTE, and CB), the entropy-based probing approach yields robust improvements. GlobalE–based selection achieves, on average, a 13% relative performance gain over random prompt orderings. LocalE provides a 9.6% improvement. Importantly, prompt selection dramatically reduces prediction variance, leading to safer deployment with consistent outcomes.
The method exhibits generality—it works across model sizes from 0.1B to 175B parameters, on diverse datasets, and is robust against variations in prompt templates. This universality is supported by template-agnostic results, with entropy-based selection outperforming both naïve random ordering and split-validation baselines.
Empirical analysis further shows that top-K selection using entropy scores produces a monotonic performance increase, with K=4 yielding stable improvements (see experimental curve data in the main text). On tasks where baseline variance is high, improvements reach up to 30% relative gain. For very small models or inherently difficult tasks (e.g., RTE, CB), gains are limited; these regimes likely lack any genuinely performant few-shot prompt.
Theoretical and Practical Implications
This work establishes that prompt order sensitivity is not an idiosyncratic artifact but a fundamental limitation of current in-context learning mechanisms in large-scale generative LMs. By formalizing and mechanizing prompt selection through artificial probing sets and entropy statistics, the approach removes the dependence on labeled validation data, thus maintaining fidelity to the strict few-shot paradigm.
The demonstrated improvements are especially significant for practical few-shot NLP applications, where computational and annotation budgets preclude extensive prompt trials. The method generalizes well across models and tasks, facilitating reliable performance when scaling to real-world systems.
Theoretically, the order sensitivity challenge points to deeper issues in how LLMs summarize and utilize context, and indicates that context processing is not permutation invariant nor robust via scaling alone. The results advocate for future research into architectural and algorithmic modifications that endow in-context learning procedures with greater stability or that can leverage the proposed probing signals in an online or adaptive manner.
Future Directions
Potential avenues for subsequent research and development include:
- Integration of probing–based prompt selection into automated prompt optimization pipelines, coupled with reinforcement learning or Bayesian optimization for efficient exploration.
- Further decomposition of the source of order sensitivity, including layer-wise and attention-focused analyses, to understand its roots in LLM context encoding.
- Design of architectures or objectives that inherently encode permutation-invariant processing or explicitly penalize high variance across input permutations.
- Extension to multimodal and multi-hop reasoning tasks, where prompt order effects may interact with cross-modal alignment or compositionality challenges.
Conclusion
The paper rigorously demonstrates that few-shot performance of LLMs is highly sensitive to the order in which training samples are presented within the prompt. Order sensitivity endures across model sizes, tasks, templates, and remains unsolved by increasing data or calibration. By exploiting LM generation and entropy-based probing metrics, the proposed method reliably identifies performant prompt permutations without requiring additional data—achieving substantial, consistent improvements in real-world few-shot classification scenarios. This framework lays essential groundwork for robust, data-efficient, and principled prompt selection in in-context learning applications.