- The paper demonstrates that simple probing techniques do not significantly extract PHI from clinical-note pretrained BERT models.
- The methodology employs fill-in-the-blank templates, cosine similarity analysis, and generative techniques to assess memorization of sensitive data.
- The results imply that while current models show low extraction rates of PHI, further research is needed as language models scale up.
Does BERT Pretrained on Clinical Notes Reveal Sensitive Data?
The paper "Does BERT Pretrained on Clinical Notes Reveal Sensitive Data?" (2104.07762) explores the potential risk of sensitive data leakage from BERT models pretrained on Electronic Health Records (EHR). The research investigates whether such models could inadvertently reveal Personal Health Information (PHI) such as patient names and medical conditions.
Introduction and Motivation
Pretraining LLMs like BERT on domain-specific corpora, including clinical notes for medical NLP tasks, has shown great utility, improving prediction accuracy in clinical settings. However, the release of pretrained model weights raises privacy concerns, particularly when the training data includes sensitive and potentially identifiable patient information. In the United States, HIPAA regulations prohibit sharing non-deidentified PHI, yet the practice of sharing pretrained models is common. This paper aims to assess whether these models can safely be released without compromising patient privacy.
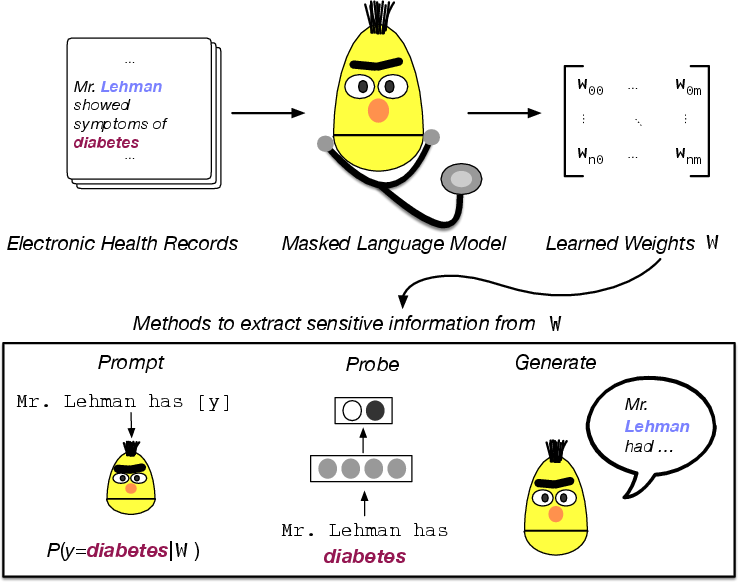
Figure 1: Overview of this work. We explore initial strategies intended to extract sensitive information from BERT model weights estimated over the notes in Electronic Health Records (EHR) data.
Methodology
The authors employed several probing methods to evaluate the potential for sensitive data extraction from BERT, specifically targeting PHI such as names and conditions associated with patients. These methods include:
- Fill-in-the-Blank Templates: Designed to reveal memorized associations between patient names and conditions using masked template strings.
- Probing Tasks: Training auxiliary models to predict conditions based on embeddings from pretrained BERT.
- COSINE Similarity Analysis: Assessing whether static word and contextual embeddings could differentiate conditions associated with specific names compared to unaffiliated conditions.
- Advanced Generative Techniques: Inspired by methods developed to extract information from models like GPT-2.
The dataset used for these experiments was derived from MIMIC-III, with names pseudo-randomly inserted to mimic the presence of PHI for testing purposes.
Key Findings
Fill-in-the-Blank and Probing Results
The experiments revealed that simple probing mechanisms fell short of significantly extracting PHI with performance metrics often aligning with chance levels. Even when more advanced probing models were leveraged, PHI extraction rates did not surpass frequency baselines of conditions in the dataset.
Static vs. Contextualized Embeddings
The investigation into COSINE similarities did not produce evidence of substantial sensitive information leaks using either static or dynamic embeddings derived from BERT, suggesting that BERT does not memorize PHI in ways that would make it trivially extractable. Notably, even when altering embedding pooling strategies, detection of sensitive data patterns remained below concerning thresholds.
Results from attempts to extract memorized data using text generation techniques were mixed. While models could generate sentences containing names associated with known conditions, this did not definitively confirm memorization of PHI pairs; the prevailing patterns likely reflected broader distributional norms rather than concrete memorized data.
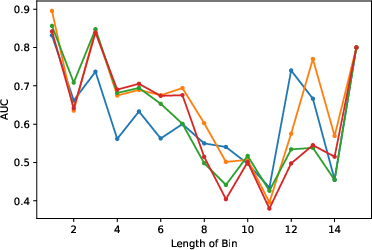
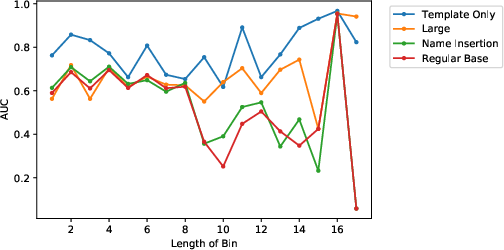
Figure 2: Per-length performance of both ICD-9 and MedCAT labels for the `masked condition' (only) experiments. A bin length of k contains conditions comprising k token pieces.
Limitations and Future Directions
The study acknowledges limitations such as the reliance on a single dataset, MIMIC-III, which due to its style and deidentification techniques makes it particularly challenging to yield name-condition linkages. It also speculates that larger and auto-regressive LLMs might present heightened risks of PHI leakage. To better understand data memorization risks, future research should explore more sophisticated attack techniques and different training regimes on diverse EHR datasets.
Conclusion
The work suggests that while initial probing methods do not significantly expose sensitive information within pretrained BERT models, the risk is not entirely precluded. As models grow in size and complexity, so too may the potential for unintended memorization and leakage of sensitive data. The authors stress the importance of ongoing research in this area and recommend cautious approaches to releasing models pretrained on sensitive datasets, advocating for the exclusive use of thoroughly deidentified data.