- The paper demonstrates that overparameterization and gradient-based implicit regularization enable effective solutions in non-convex deep learning models while tolerating benign overfitting.
- The paper shows through linear regime analysis that neural networks can be approximated as linear models where initialization and minimal norm solutions drive generalization.
- The paper bridges classical statistical learning theory with deep learning by clarifying limitations of uniform convergence and suggesting new approaches for efficient optimization.
Deep Learning: A Statistical Viewpoint
Introduction
The paper "Deep learning: a statistical viewpoint" presents a statistical perspective on deep learning. It explores the success of simple gradient methods in solving non-convex optimization problems and achieving excellent predictive accuracy despite overfitting training data. It conjectures that overparametrization, implicit regularization, and benign overfitting explain this success. The paper surveys progress in statistical learning theory, highlighting key principles that underpin deep learning, and reviews relevant results in simple settings to illustrate these principles.
Overparametrization, Implicit Regularization, and Benign Overfitting
The paper posits that overparametrization allows simple gradient methods to find effective solutions by reducing the problem's complexity. This overparametrization leads to benign overfitting, enabling models to fit training data while maintaining predictive accuracy.
Implicit regularization, introduced by gradient methods, is part of the explanation. These methods prioritize minimizing parameter norms, resulting in interpolating functions that fit training data perfectly. The paper discusses prediction methods that exhibit benign overfitting, particularly in regression problems with quadratic loss.
This section reexamines classical statistical learning theories and uniform convergence results. The paper identifies where these theories fall short in explaining deep learning behavior. It depicts how classical approaches align complex models with regularization to maintain generalization, whereas deep learning methods manage to generalize well without explicit regularization efforts.
Implicit Regularization
The paper reviews results showing how gradient methods impose implicit regularization. By favoring minimal norm solutions, gradient methods regularize model complexity implicitly. The paper discusses the linear regime where neural networks can be treated as linear models, showing how overparametrization and initialization influence gradient flow and contribute to benign overfitting.
Benign Overfitting
The paper provides analyses of benign overfitting scenarios, where the prediction rule interpolates noisy data without harming accuracy. It decomposes the prediction rule into a simple prediction component and a spiky overfitting one. This approach clarifies how overfitting is benign in high-dimensional settings, with results on kernel smoothing methods and high-dimensional linear regression.
Efficient Optimization
This section addresses the efficiency of solving non-convex empirical risk minimization problems using gradient methods. It reviews tractability via overparametrization and discusses mechanisms enabling efficient solution finding. Examples include the linear regime in neural networks, where models exhibit near-linear application behavior, and the success of gradient methods in overparametrized settings.
Neural Networks in the Linear Regime
The linear regime is characterized by regimes where neural networks behave akin to linear models. Overparametrization satisfies the conditions for efficient optimization, leading to approximations that facilitate problem-solving. It considers future directions for extending understanding to realistic deep learning settings.
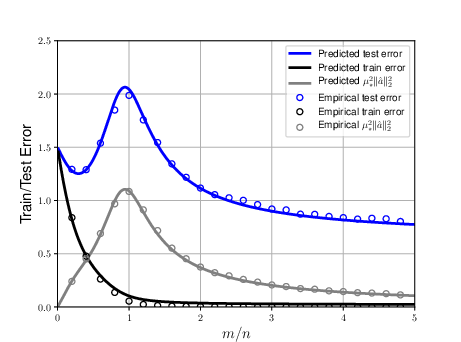
Figure 1: Train and test error of a random features model (two-layer neural net with random first layer) as a function of the overparametrization ratio m/n. Here d=100, n=400, τ2=0.5, and the target function is $f^*=\<_0,\>, |_0\|_2=1$. The model is fitted using ridge regression with a small regularization parameter λ=10−3.
Conclusion
The paper concludes by highlighting challenges in applying these insights to practical deep learning settings. It underscores the need for further research to extend current understanding to models with complex architectures and real-world data complexities. Implicit regularization and the role of overparametrization merit further exploration to leverage their potential in practical applications of deep learning models.