- The paper’s main contribution is decoupling policy and value by using separate networks and an adversarial regularizer to prevent overfitting.
- It introduces the IDAAC framework, validated on benchmarks like Procgen, achieving state-of-the-art test performance on unseen environments.
- The study reveals that a higher value loss correlates with improved generalization, highlighting the benefits of decoupled representations in RL.
Decoupling Value and Policy for Generalization in Reinforcement Learning
Introduction
The paper "Decoupling Value and Policy for Generalization in Reinforcement Learning" (2102.10330) presents a novel approach designed to enhance generalization in reinforcement learning (RL) by addressing the entanglement of policy and value functions often shared in standard RL models. This coupling has been identified as a key factor inducing overfitting to training environments, thus impairing performance when generalizing to new settings. The innovative approach involves the development of the Invariant Decoupled Advantage Actor-Critic (IDAAC), which utilizes separate networks for policy and value functions, alongside a regularization mechanism to mitigate overfitting.
Policy-Value Representation Asymmetry
The paper highlights an underlying issue in standard RL methods where a single representation is used for both policy and value functions. This can lead to overfitting, especially when operating on procedurally generated environments. The authors demonstrate this with two visually different yet semantically identical levels in the game Ninja, where discrepancies in value predictions due to visual differences illustrate the potential for overfitting (Figure 1).

Figure 1: Policy-Value Asymmetry.
Methodology
Decoupled Advantage Actor-Critic (DAAC)
The DAAC framework separates the policy and value function networks, reducing interference in optimization and enhancing the learning of both components separately. The policy network estimates the advantage function rather than the value function, which reduces susceptibility to instance-specific overfitting.
Invariant Decoupled Advantage Actor-Critic (IDAAC)
IDAAC introduces an adversarial regularizer that constrains the policy representation to be invariant to task-specific nuances. This is achieved through a discriminator that discourages the encoder from embedding instance-specific information in the learned features, thereby improving generalization to unseen environments (Figure 2).
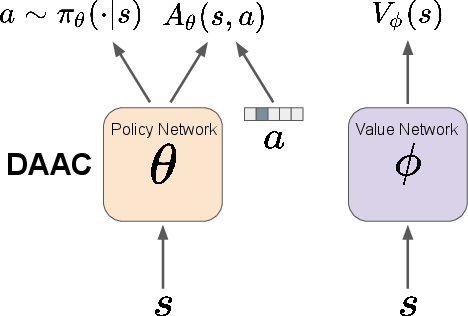
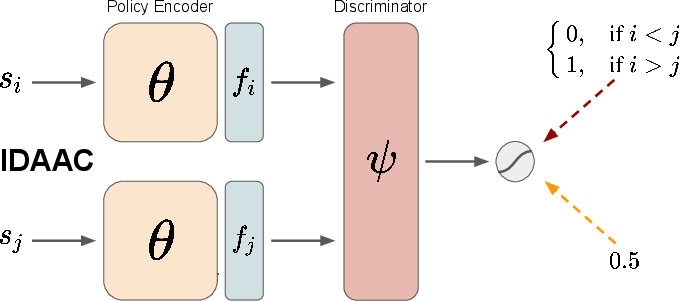
Figure 2: Overview of DAAC (left) and IDAAC (right), highlighting network decoupling and the adversarial regularizer.
Experiments and Results
The authors validate IDAAC on the Procgen and DeepMind Control Suite benchmarks, showing new state-of-the-art results on test distributions while maintaining competitive training performance (Figure 3). They demonstrate generalization advantages over existing methods such as PPG, UCB-DrAC, and PPO through comprehensive ablation studies (Figure 4).
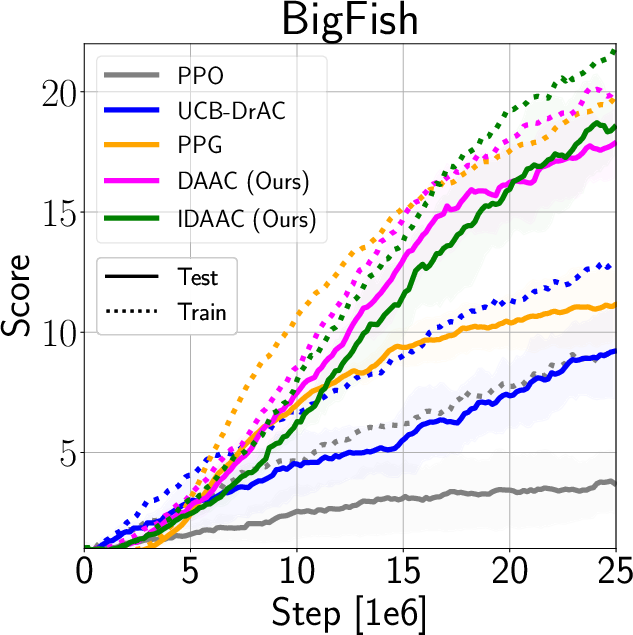
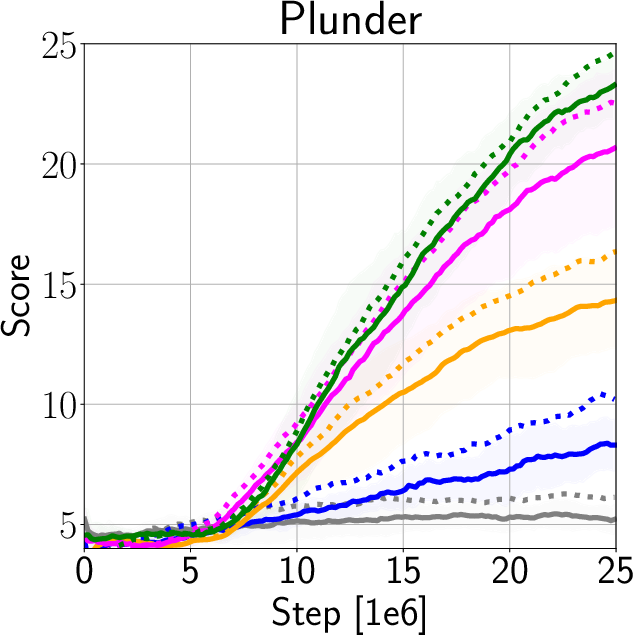
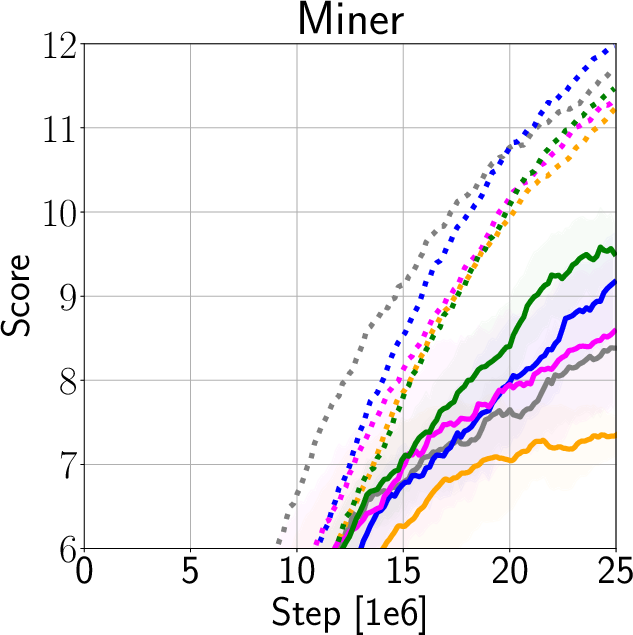
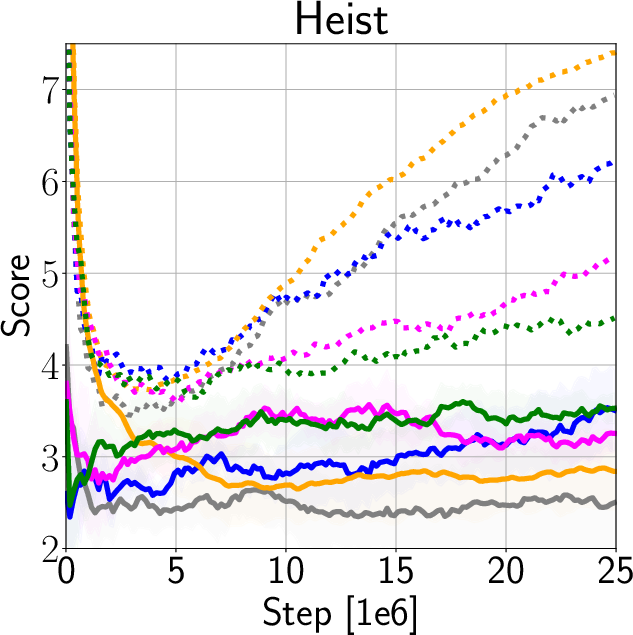
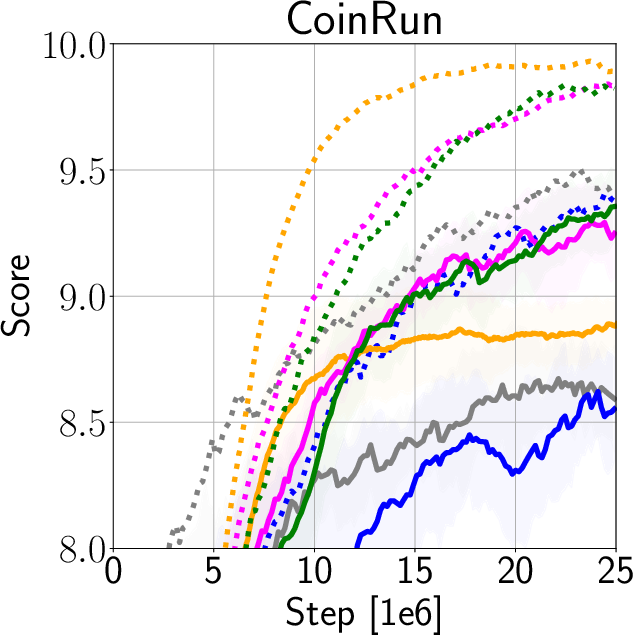
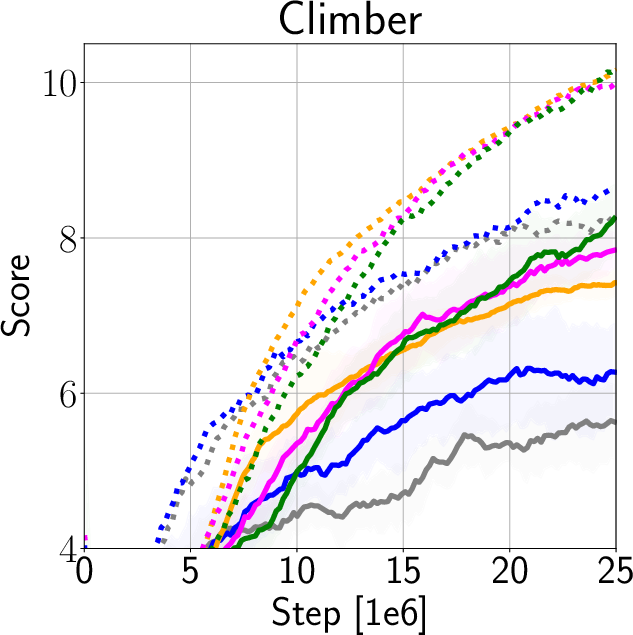
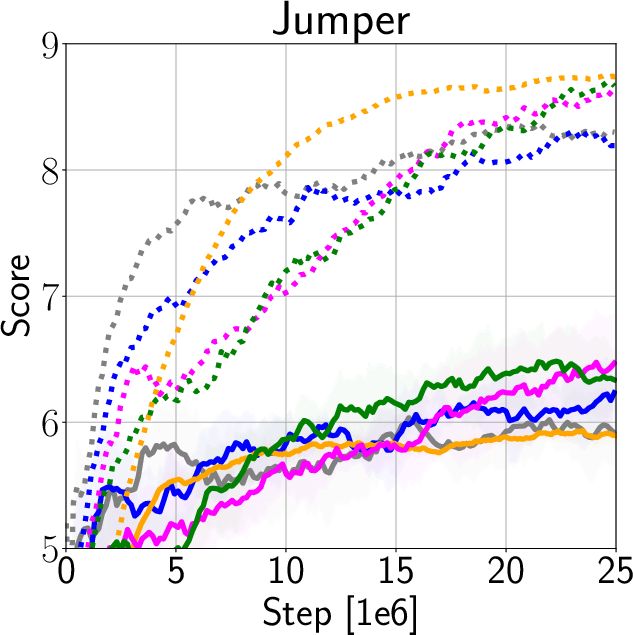
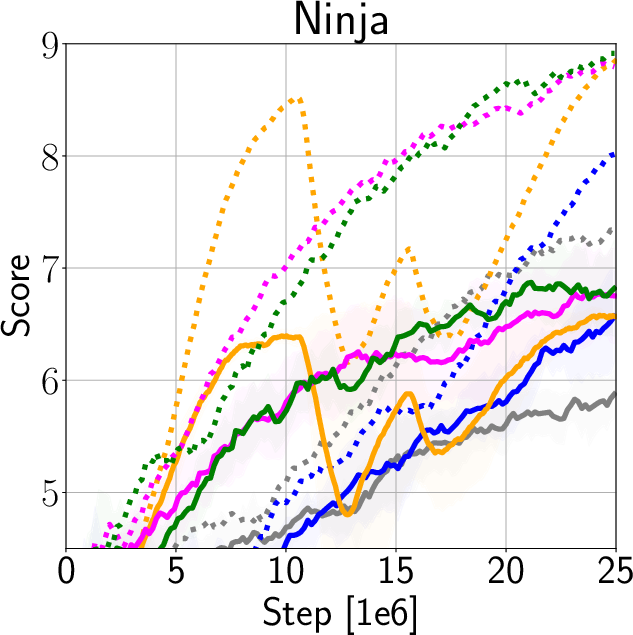
Figure 3: Train and Test Performance for IDAAC and other benchmarks.
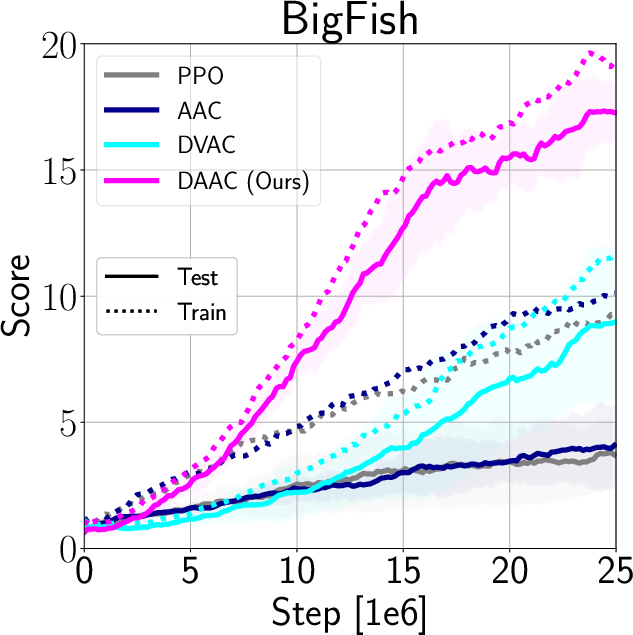
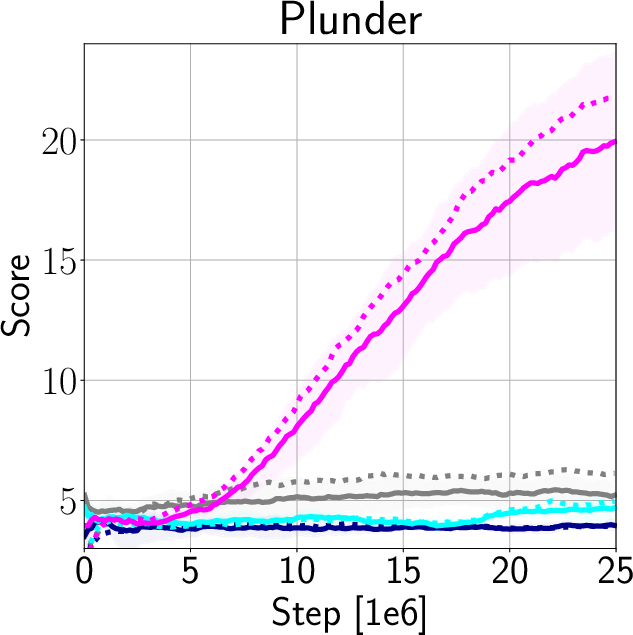
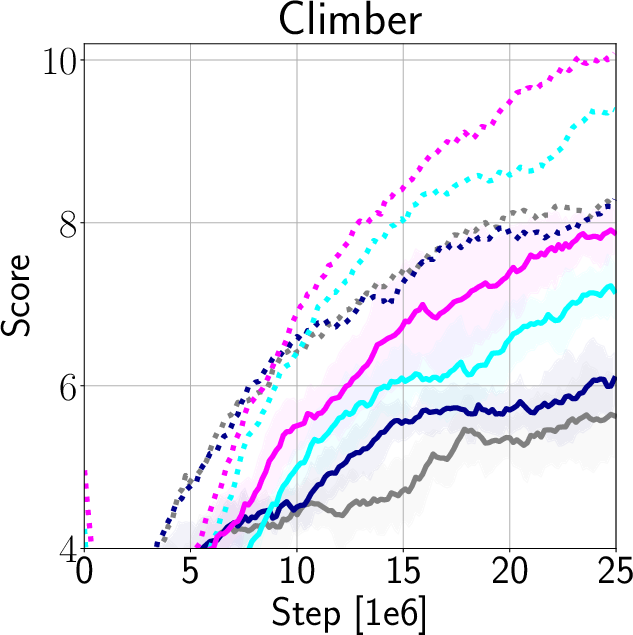
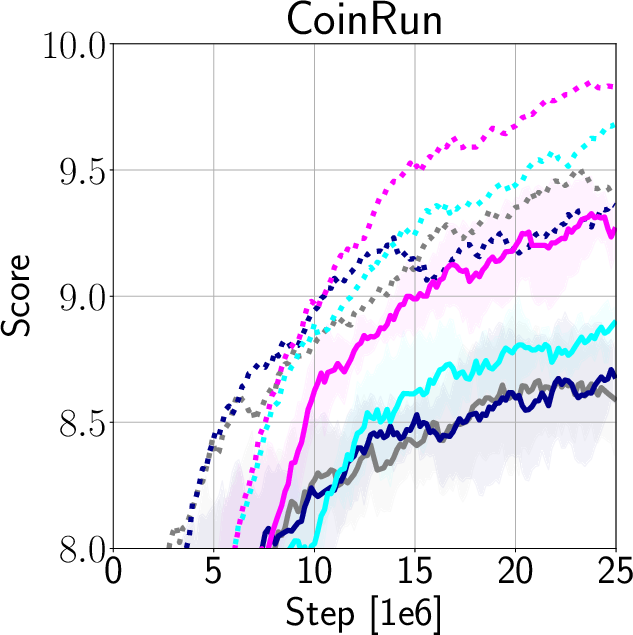
Figure 4: Comparison of train and test performance for DAAC, DVAC, AAC, and PPO.
A key finding is the positive correlation between value loss and generalization capability, suggesting that models with less precise value predictions may generalize better. Overfitted models that perfectly predict training environment values often fail in new environments, underscoring the need for the decoupling proposed in this paper (Figure 5).
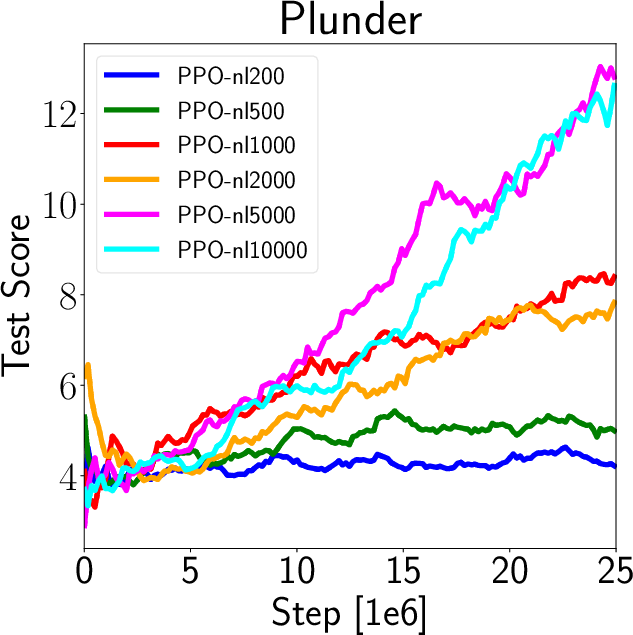
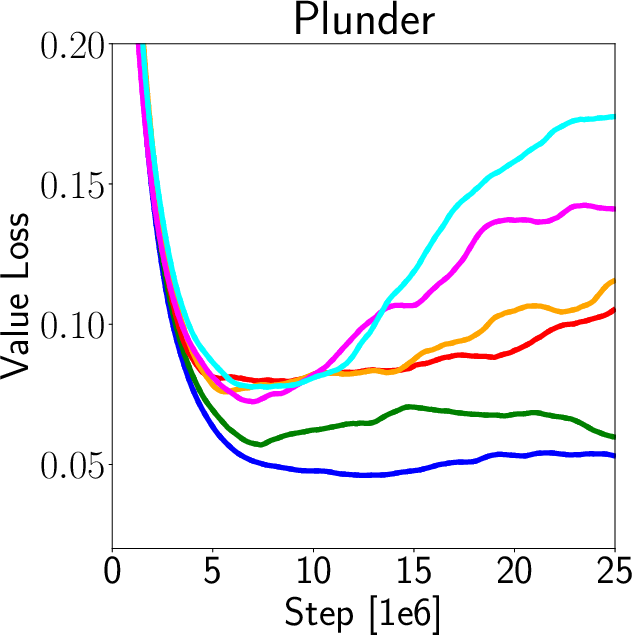
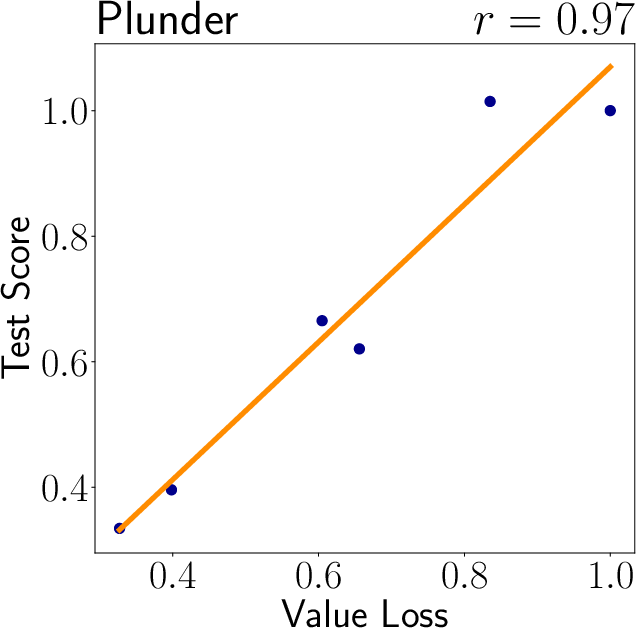
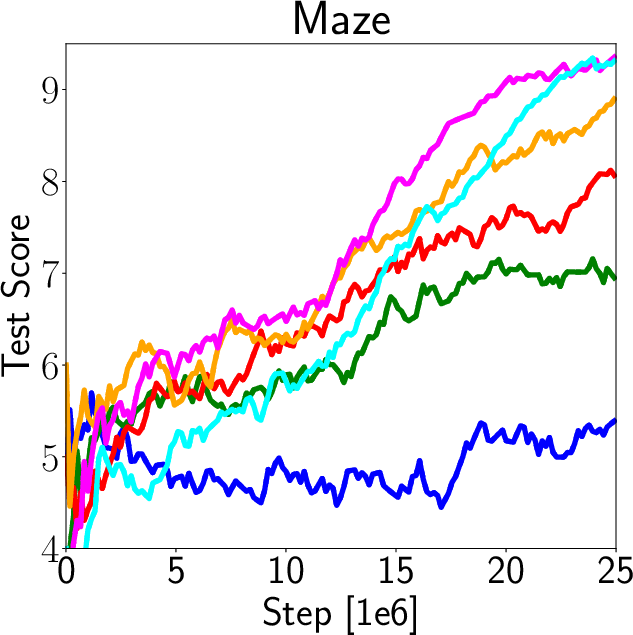
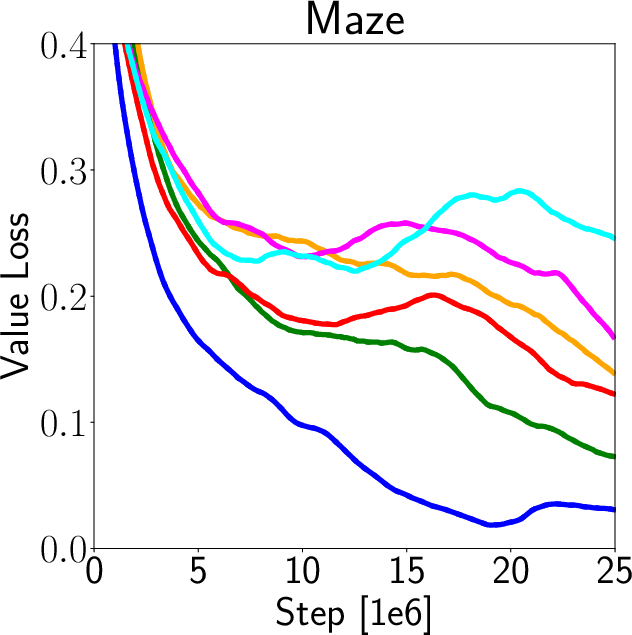
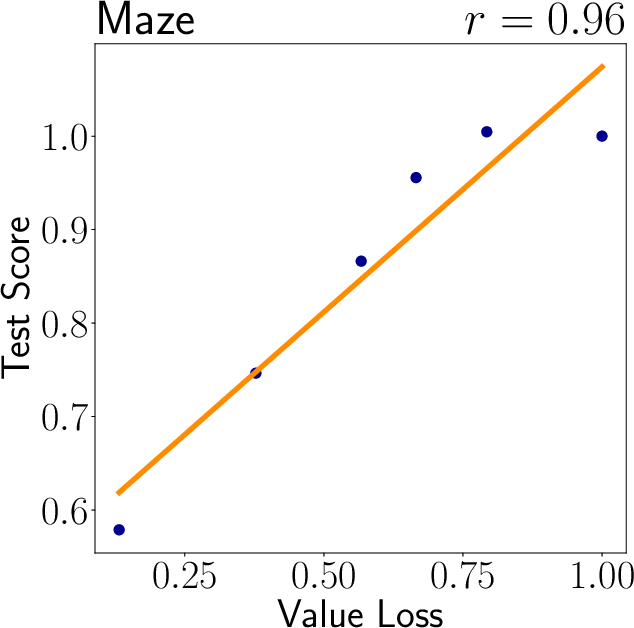
Figure 5: Analysis of value loss correlation with generalization.
Conclusion
The research identifies critical issues in standard RL frameworks related to the shared representation of policy and value functions. By introducing separately optimized networks and invariant regularization, IDAAC effectively improves generalization across diverse environments. Future work should explore further auxiliary loss functions to support broader generalizability across more complex RL scenarios.

