- The paper introduces a framework that delineates four neural scaling regimes validated through rigorous theoretical and empirical experiments.
- It demonstrates that both variance-limited and resolution-limited regimes follow power-law behaviors, with exponents shaped by dataset and model size.
- Results from teacher-student models and diverse architectures confirm predicted scaling laws, offering insights for efficient large-scale AI training.
Explaining Neural Scaling Laws
Explaining Neural Scaling Laws offers a comprehensive framework to understand scaling laws in neural networks with respect to model size and dataset size. The theory presented delineates four scaling regimes, emphasizing the predictability of neural network performance improvements through power-law relations.
Scaling Laws in Neural Networks
Variance-Limited Regime
The variance-limited regime deals with scenarios where either the dataset size D or the number of parameters P becomes arbitrarily large, resulting in a simplification of certain aspects of neural network training. The scaling behavior in this regime follows a universal power-law with exponent $1$, applicable to both underparameterized models scaling with dataset size and overparameterized models scaling with width.
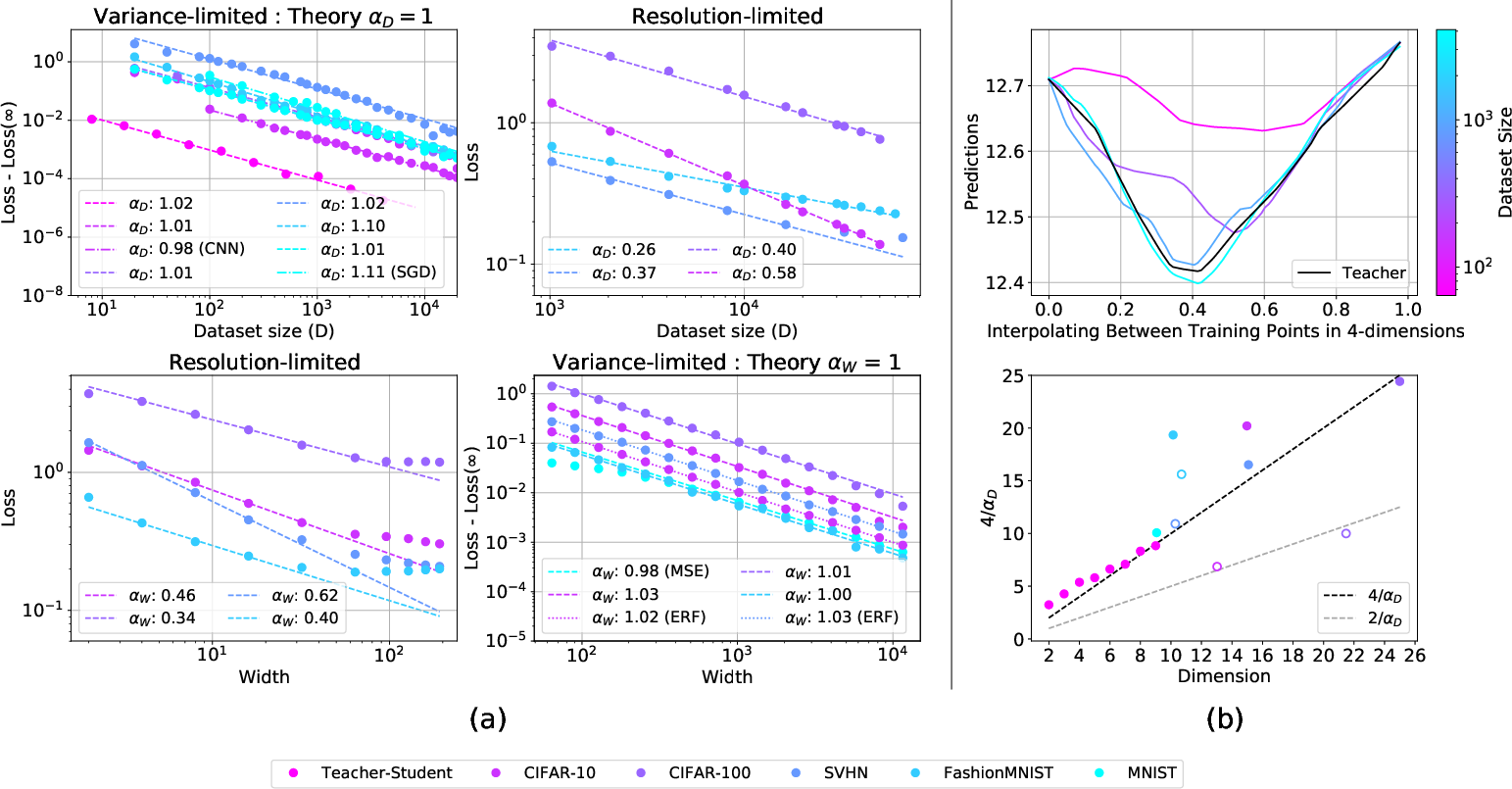
Figure 1: Four scaling regimes. Variance-limited scaling of underparameterized models with dataset size and overparameterized models with model width show universal scaling.
Resolution-Limited Regime
In the resolution-limited regime, either D or P is effectively infinite, and the scaling with the other parameter exhibits power-law behavior with exponents dependent on the data distribution. Empirical observations denote exponents typically satisfying 0<α<1, applicable to both model size and dataset size scaling. These behaviors are theoretically derived and tested empirically in various standard architectures and datasets.
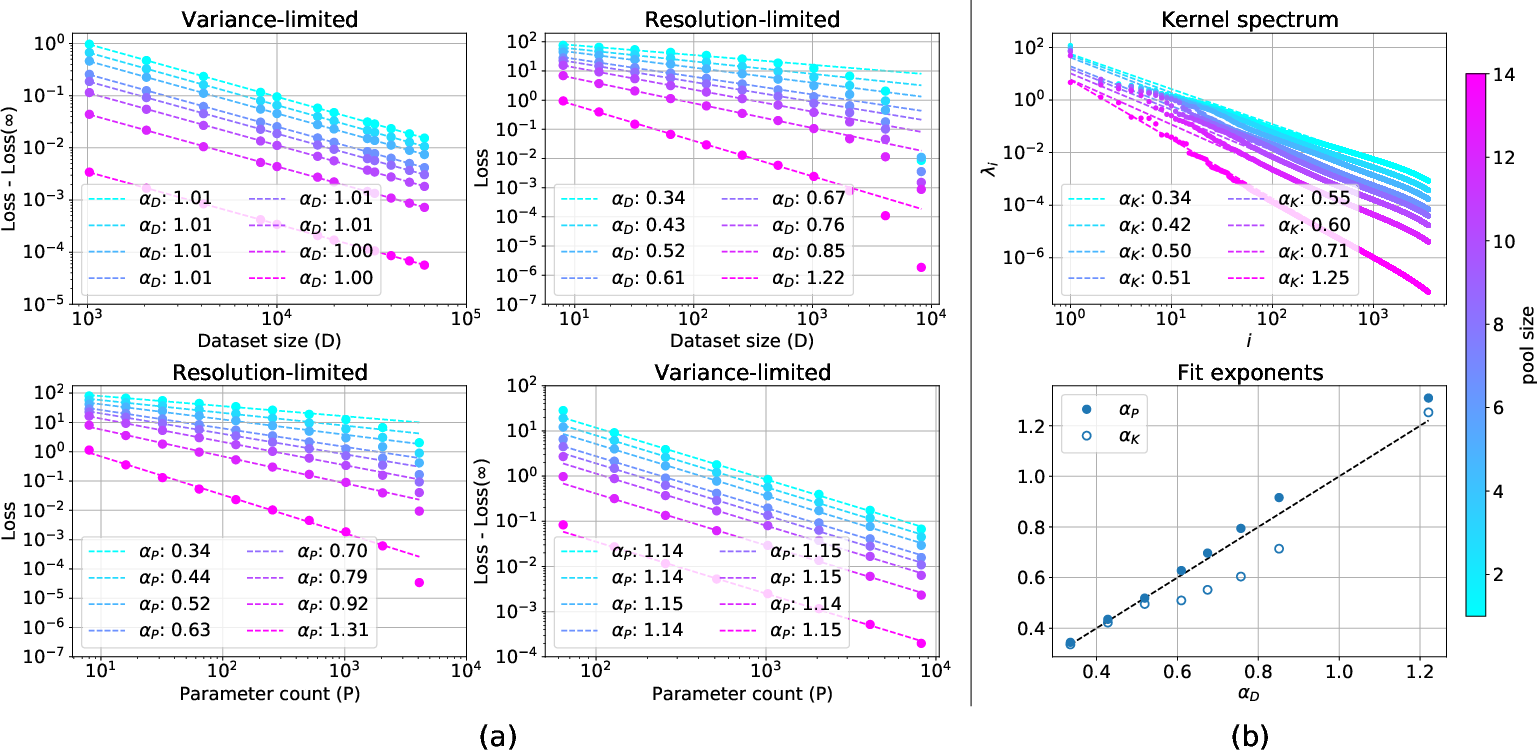
Figure 2: Random feature models demonstrate both variance-limited scaling and resolution-limited scaling.
Experimental Validation
The proposed scaling laws are substantively validated across a spectrum of experiments employing various tasks and architectures:
Teacher-Student Models
Teacher-student configurations allow controlled experiments through synthetic data generated by one network (the teacher) and learned by another (the student). Scaling exponents closely align with predictions based on input data dimensionality, affirming the resolution-limited scaling derivations.
Empirical Scaling Across Architectures
Variance-limited scaling is observed uniformly across diverse deep learning models and datasets, where both width scaling and dataset size consistently demonstrate behavior in accord with the theoretical expectations. Resolution-limited exponents in real datasets exhibit dependencies contingent on inherent dataset characteristics and model architecture parameters.
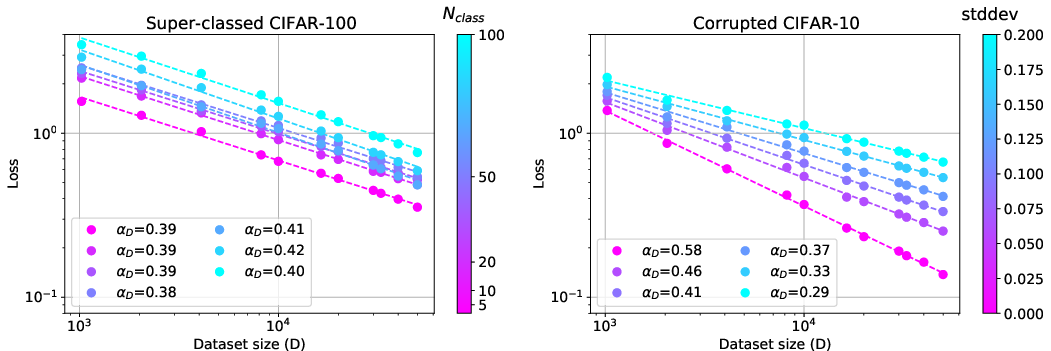
Figure 3: Effect of data distribution on scaling exponents; Gaussian noise strongly affects scaling.
Discussion
The study integrates theoretical rigor with empirical observations, underscoring a taxonomy of neural network scaling laws as linked to the dimensions of data manifolds and kernel spectral decay. Future investigations might further quantify feature learning impacts on scaling behaviors, particularly within dynamically evolving kernels in finite-width, finite-depth networks.
Limitations
The theoretical results are asymptotic, and empirical evaluations are inherently limited by practical computational constraints preventing infinite data and model scenarios. Moreover, accurate empirical definitions of data manifolds remain elusive, demanding approximations that might distort deeper analysis.
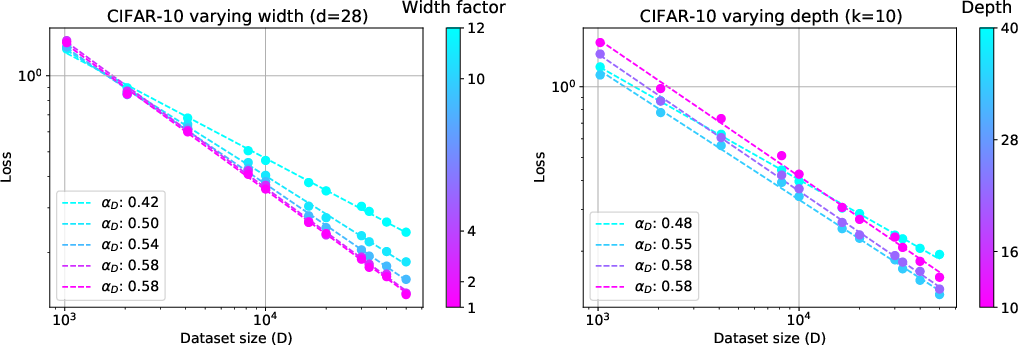
Figure 4: Alternating architecture parameters affect scaling behavior.
Conclusion
The foundation laid in this work not only models neural scaling laws robustly but also elevates scientific comprehension of deep neural networks, potentially guiding future developments in training large-scale AI models. Enhanced understanding of these scaling regimes may catalyze improvements in efficiency and predictability within diverse real-world machine learning applications.