- The paper introduces NFNets that eliminate batch normalization by using adaptive gradient clipping to maintain training stability and achieve competitive accuracy.
- The method leverages Scaled Weight Standardization, extensive regularization, and optimized architecture design to reduce computational overhead and enhance convergence.
- Results demonstrate that NFNet-F1 trains up to 8.7 times faster than EfficientNet-B7 while delivering comparable performance on large-scale datasets such as ImageNet.
The paper "High-Performance Large-Scale Image Recognition Without Normalization" proposes a novel approach to train deep networks using Normalizer-Free ResNets, which eliminates the need for batch normalization (BN) and achieves state-of-the-art accuracies in large-scale image recognition tasks.
Overview and Motivation
Batch normalization is commonly used in deep networks to stabilize training, improve convergence, and enhance overall performance. However, BN introduces several drawbacks, such as dependency on batch size, increased computational overhead, and challenges in distributed training. Despite recent advancements in training deep ResNets without normalization layers, achieving competitive test accuracy remains a challenge. The paper introduces an adaptive gradient clipping technique to stabilize training in Normalizer-Free Networks (NFNets) and proposes architectures that outperform batch-normalized networks.
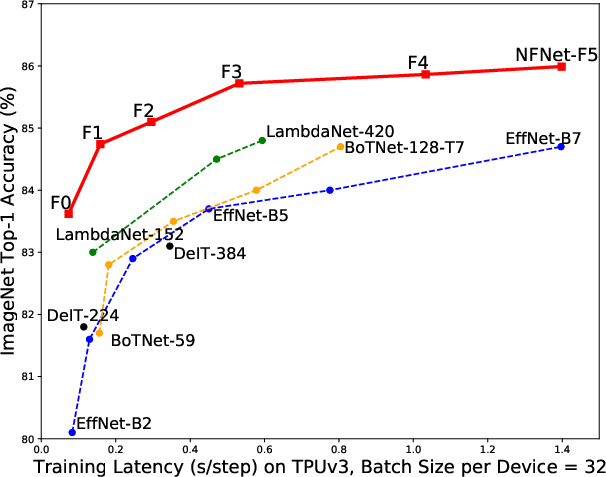
Figure 1: ImageNet Validation Accuracy vs Training Latency showing NFNet-F1 model achieves accuracy comparable to EfficientNet-B7, but with significantly faster training.
Elimination of Batch Normalization
Disadvantages of Batch Normalization
Batch normalization complicates training by synchronizing batch statistics during distributed training, leading to hardware-specific implementations that can result in inconsistencies across different platforms. BN often requires tuning of hyper-parameters due to discrepancies between training and inference modalities and demands higher computational resources.
Normalizer-Free Approach
Instead of relying on normalization, the proposed NFNets use Adaptive Gradient Clipping (AGC) which clips gradients based on the unit-wise ratio of gradient norms to parameter norms. This method facilitates the use of larger learning rates and batch sizes, improving training stability. The NFResNet architecture introduces Scaled Weight Standardization aiming to suppress mean shift in activations and apply extensive regularization techniques such as dropout and stochastic depth.
Adaptive Gradient Clipping
AGC proposes an elegant solution to training instability by ensuring the parameter updates remain within a bounded range relative to the current parameter norm. This is specifically useful in scenarios where large batch sizes are used, permitting smoother and efficient convergence even under aggressive data augmentation techniques like RandAugment and CutMix.
\begin{equation}
G{\ell}_i \rightarrow
\begin{cases}
\lambda \frac{|W{\ell}_i|\star_F}{|G{\ell}_i|_F}G{\ell}_i& \text{if ∥Wiℓ∥F⋆∥Giℓ∥F>λ}, \
G{\ell}_i & \text{otherwise.}
\end{cases}
\end{equation}
This strategy diverges from LARS and other normalized optimizers by allowing adaptive learning rates tailored to the data distribution, ensuring performance optimization without sacrificing stability.
Architecture Design and Results
Architecture Design: NFNets are crafted to operate optimally on existing hardware accelerating both training and inference. The modified SE-ResNeXt-D configuration leverages preferred depth scaling and network-width alternatives to enhance throughput on accelerators like GPUs and TPUs.
Performance: NFNet-F1 achieves a notable improvement over EfficientNet-B7 in terms of training latency, delivering as much as 8.7 times faster training while maintaining comparable accuracy (Figure 2). On fine-tuning post pre-training over 300 million images, NFNets outperform conventional batch-normalized networks significantly, showcasing enhanced generalizability without extensive data augmentation.
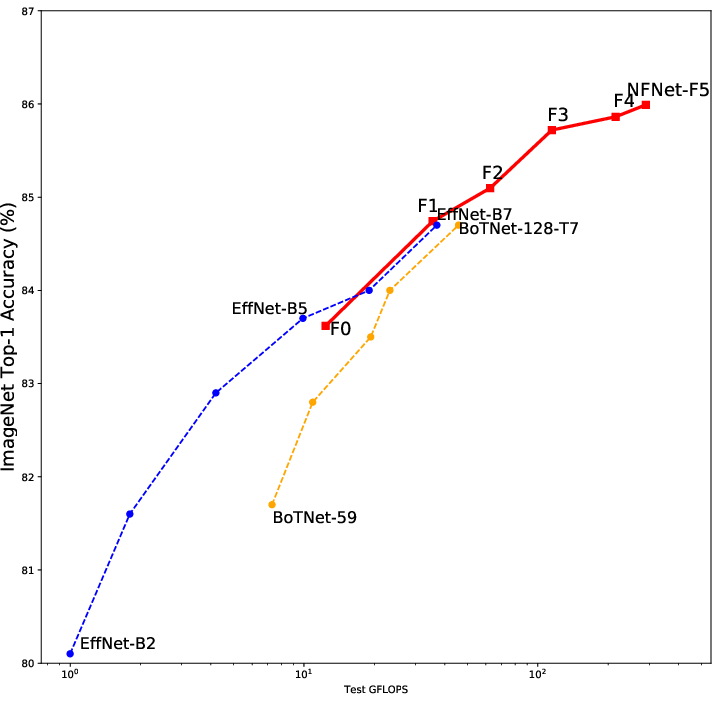
Figure 2: ImageNet Validation Accuracy vs. Test GFLOPs showing NFNet models are competitive with EfficientNet variants, optimized for training latency.
Conclusion
The paper concludes that NFNets, powered by adaptive gradient clipping and thoughtful architectural adjustments, redefine the efficiency and accuracy standards of deep networks for large-scale image classification. By removing the dependency on normalization layers, NFNets demonstrate enhanced scalability, training speed, and adaptability to hardware constraints while achieving superior accuracies on challenging benchmarks like ImageNet. This approach is poised to influence future research directions and deployment strategies in large-scale AI applications.

