- The paper extends permutation invariant training (PIT) to waveform and latent spaces, achieving more stable and accurate speech separation.
- It introduces tPIT variants and leverages clustering with GE2E loss to resolve permutation ambiguity at the frame level.
- The integration of PASE embeddings into uPIT models significantly improves separation performance, as evidenced by SI-SNR gains on standard datasets.
On Permutation Invariant Training for Speech Source Separation
Introduction
Permutation invariant training (PIT) addresses the permutation ambiguity problem inherent in speaker-independent source separation models. This challenge arises from the need to correctly associate multiple separated speaker outputs with ground truth sources within mixtures of speech signals. Existing PIT strategies include utterance-level PIT (uPIT), which minimizes loss over entire utterances, often resulting in permutation consistency, and frame-level PIT (tPIT), which achieves fine-grained separation at the frame level but may induce rapid permutation changes during inference. This paper investigates extensions to these PIT paradigms in both waveform and latent spaces.
tPIT and Clustering for Conv-TasNet
The study extends the tPIT+clustering algorithm, initially developed for STFT domain models, to Conv-TasNet, which employs waveform-based learning. Conv-TasNet’s architecture, with a learned encoder/decoder, adapts tPIT to the shorter frame lengths critical for time-domain models. Several tPIT variants are explored:
tPIT-STFT (Figure 1, top): Implements tPIT using the STFT domain, achieving superb frame-level separation with subsequent recombination enabled through spectral loss optimization. Performance hinges on accurate tracking algorithms to reorder frame-level separations.
tPIT-Time (Figure 1, bottom): Directly applies tPIT in the time domain using waveform. This variant faces challenges due to the inadequacy of short waveform frames to effectively capture separation targets, demanding delicate post-processing to ensure coherent output reconstruction.
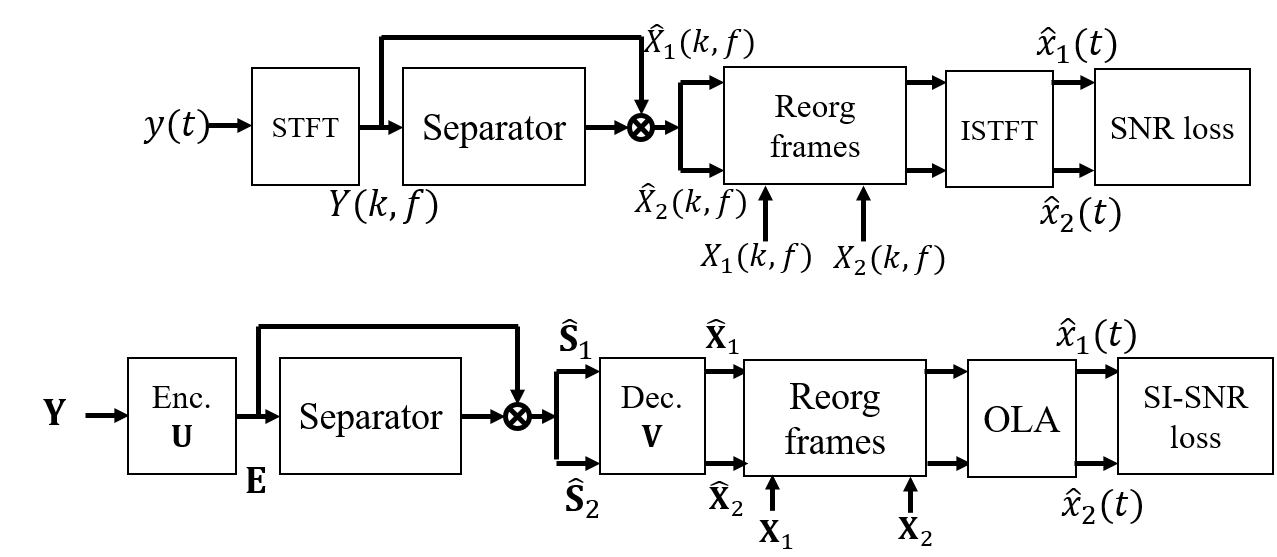
Figure 1: tPIT training for spectrograms (top) and waveforms (bottom).
tPIT-Latent (Figure 2): A novel approach performing tPIT within a learned latent space rather than raw waveform, architecturally facilitating a more stable separation. Training is bifurcated into encoding/decoding with SI-SNR optimization followed by a separator using tPIT loss tailored for the latent domain.
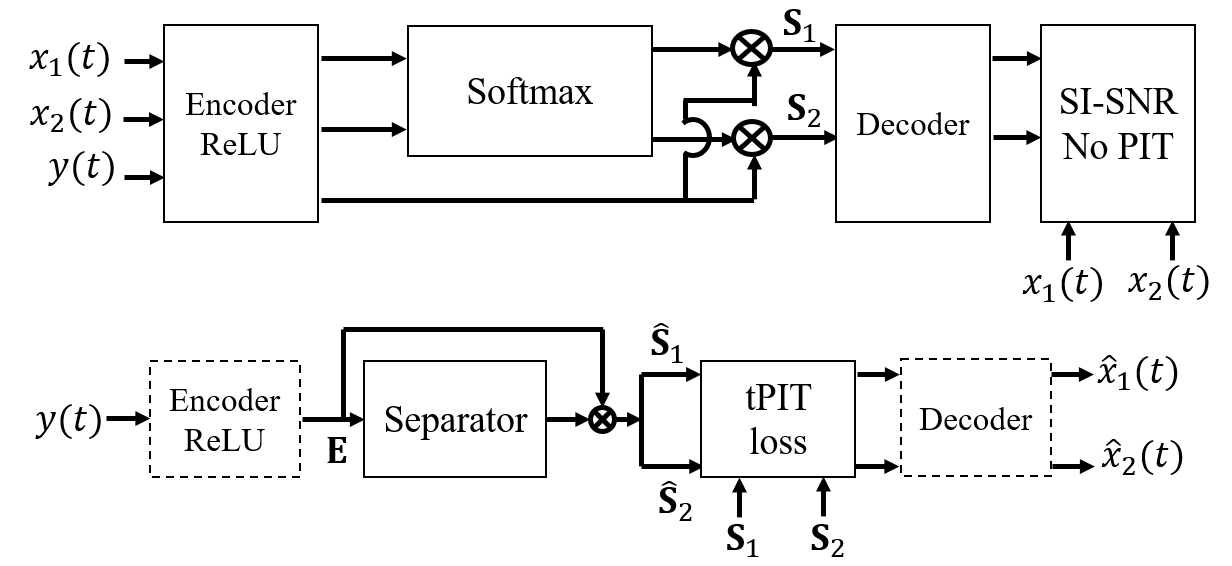
Figure 2: tPIT training in the latent space. First, train the encoder/decoder to generate the optimal latent representation (top). Next, train the separator only with tPIT loss (bottom).
Clustering: Following tPIT separation, a clustering technique is applied to resolve frame-wise permutations into coherent sequences across utterances. Leveraging GE2E loss, this clustering technique efficiently scales for waveform domains previously constrained by computational overheads inherent in STFT models.
uPIT and PASE Enhancements
The paper investigates incorporation of problem agnostic speech embeddings (PASE) into uPIT models. These embeddings, generated through broad self-supervised learning tasks, inject robust speech features which complement basic speaker-ID loss used in existing systems.
Single-stage uPIT+PASE (Figure 3, solid) incorporates PASE into uPIT, resulting in enhanced separation performance stemming from enriched embedding contexts beyond mere speaker identification.
Cascaded uPIT+PASE (Figure 3, dashed) explores a pipeline approach where initial separation informs fine-tuning of a secondary Conv-TasNet equipped with FiLM conditioned PASE embeddings, aimed at achieving iterative improvement through feedback integration from stage outputs.
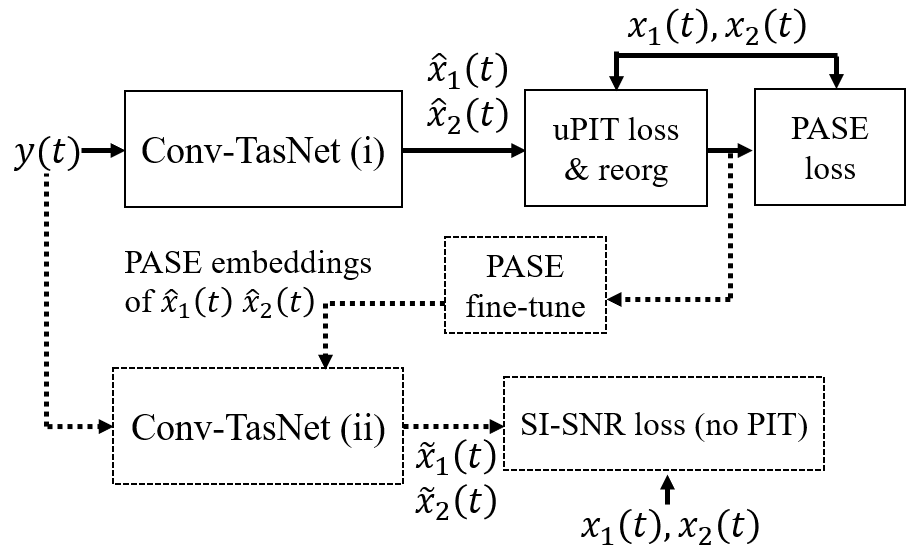
Figure 3: uPIT+PASE (solid) and its cascaded extension (dashed).
Empirical Evaluations
Experiments conducted on WSJ0-2mix, Libri-2mix, and VCTK-2mix demonstrate the statistical significance of proposed methods. Models leveraging STFT reveal superior generalization and permutation handling over waveform-based architectures, suggesting an intrinsic advantage in spectral processes against permutation ambiguity.
Notably, tPIT-latent+clustering offers promising results with efficient GE2E loss clustering outperforming traditional pairwise methods. On permutation robustness, detailed evaluation metrics including SI-SNRi and FER reveal marked improvements in separation fidelity.
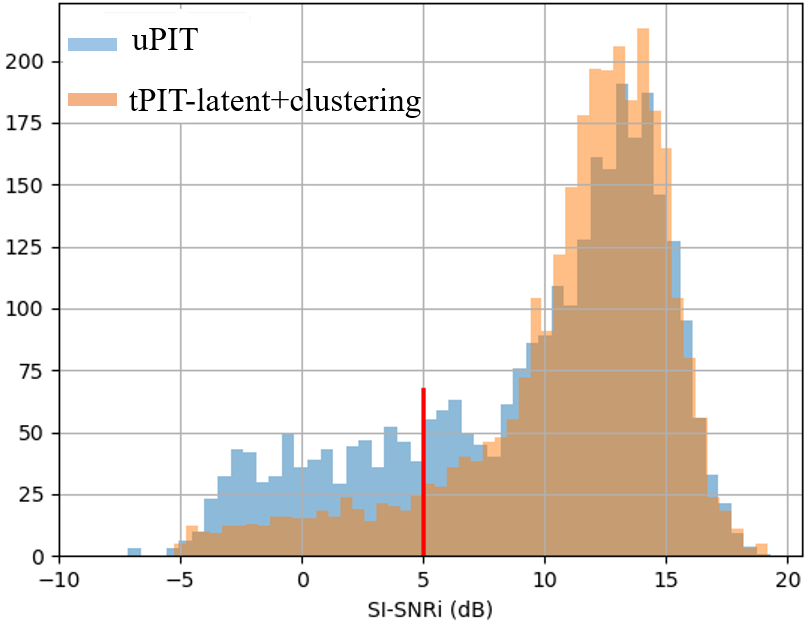
Figure 4: Histogram: SI-SNRi (dB) results of tPIT-latent+clustering on VCTK-2mix. Red line: 5dB threshold defining ``hard" samples.
Conclusion
This study advances PIT methodologies by embedding them within waveform and latent spaces, refining separation quality via efficient clustering mechanisms. Although STFT-based models demonstrate higher resilience to permutation errors, the extensions proposed for Conv-TasNet hold substantive promise for expanding time-domain model capabilities. Future research may further explore hybrid model frameworks or adaptive learning strategies to synchronize benefits of both spectral and waveform domains in overcoming permutation obstacles within speech separation tasks.

