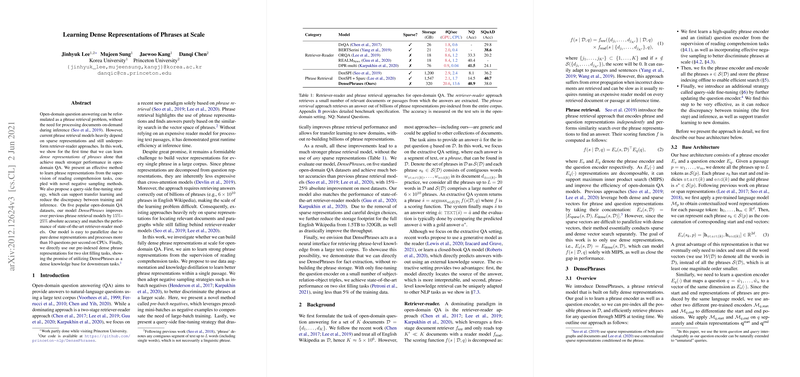
Learning Dense Representations of Phrases at Scale
This paper focuses on advancing open-domain question answering (QA) by enhancing phrase retrieval models through the innovation of dense representations. Historically, state-of-the-art QA systems have relied heavily on retriever-reader models which demand on-the-fly document processing. These have shown efficacy but come with high computational costs and complexity. The proposed model, DensePhrases, circumvents these challenges by leveraging purely dense phrase representations and eliminating the need for sparse components traditionally used in similar tasks.
Key Contributions
- Dense Representation Learning: The research introduces a method to accurately learn phrase representations using dense vectors, supervised by reading comprehension tasks. By employing data augmentation and knowledge distillation, alongside innovative negative sampling strategies, the model refines its phrase representation capacity. These strategies include in-batch and pre-batch negative sampling which significantly improve discrimination among phrases across a large dataset.
- Query-Side Fine-Tuning: This technique addresses the discrepancy between the training and inference phases. It allows robust transfer learning by updating only the question encoder without necessitating re-indexing of phrase representations. This mechanism markedly enhances the model's adaptability across different QA datasets and tasks.
- Performance and Efficiency: Evaluated across five standard open-domain QA datasets, the dense representation model demonstrates substantial performance gains of 15%–25% in absolute accuracy over previous models. DensePhrases also achieves accuracy on par with top retriever-reader systems. Moreover, due to its dense nature, the model is inherently more parallelizable, thus improving throughput significantly to over 10 questions per second on CPUs. The reduced storage footprint from 1.5TB to 320GB further illustrates the model's efficiency.
- Utilization as a Dense Knowledge Base: Beyond QA, the model's potential extends to other knowledge-intensive tasks, such as slot filling, projecting it as a neural interface for phrase-level knowledge retrieval. In practical terms, this suggests an avenue for DensePhrases to be employed in different NLP contexts without necessitating extensive retraining or restructuring of the knowledge base.
Implications and Future Directions
The introduction of DensePhrases marks a pivotal shift towards fully dense systems which promise scalability and efficiency in open-domain QA landscapes. Its implications for offline indexing and real-time response could transform the accessibility and efficiency of QA systems. Furthermore, the advancement in dense retrieval can aid other domains such as fact extraction and relation classification, enabling seamless, rapid integration of knowledge across diverse NLP tasks.
Looking forward, the ability to leverage simple, dense-only architectures presents fascinating avenues for research progression, including but not limited to more efficient data indexing, refined retrieval pipelines, and broader applications across unexplored datasets and languages. Future efforts could also focus on reducing computational overheads and enhancing the natural language understanding capabilities within more compact models.
In summation, the research provides a comprehensive and practical framework for dense phrase representation and retrieval, emphasizing an intersection of efficiency and accuracy that could set a precedent for future QA systems and related NLP endeavors.