- The paper introduces a novel DCT-based mask representation that transforms high-resolution masks into compact frequency domain vectors, improving boundary detail.
- The approach integrates with Mask R-CNN by converting mask prediction into a regression task for DCT vectors, maintaining high IoU scores with reduced complexity.
- Experiments on COCO and Cityscapes demonstrate that DCT-Mask delivers higher AP scores and improved mask quality, supporting real-time vision applications.
Introduction
The paper "DCT-Mask: Discrete Cosine Transform Mask Representation for Instance Segmentation" introduces a novel approach to instance segmentation by leveraging the discrete cosine transform (DCT) to encode high-resolution binary grid masks into compact vectors. This method is designed to overcome limitations in existing low-resolution binary grid mask representations, such as those used in Mask R-CNN, which suffer from insufficient detail capture and increased complexity when scaled to higher resolutions.
DCT-Mask Representation
In standard instance segmentation methods like Mask R-CNN, masks are predicted on a fixed low-resolution binary grid, which can compromise the granularity of object boundaries. The proposed DCT-Mask representation resolves this by transforming the high-resolution mask into the frequency domain via DCT, allowing the retention of essential low-frequency components in a compact form.






Figure 1: Binary grid mask representation vs. DCT mask representation. The leftmost sub-graph is the ground truth, the left-middle is the mask representation, the middle right is the reconstructed mask, the rightmost is the error between the reconstructed mask and the ground truth.
DCT's inherent "energy compaction" effectively encapsulates critical mask information, allowing significant detail in object boundaries to be preserved in a reduced vector size. The experiments demonstrate that a 300-dimensional DCT vector from a 128×128 resolution grid maintains a high Intersection over Union (IoU) score, significantly reducing complexity compared to a direct high-resolution grid.
Integration with Mask R-CNN
Integration of the DCT-Mask necessitates minor modifications to the architecture of Mask R-CNN. Specifically, the mask branch adapts to predict DCT vectors instead of binary grids by incorporating fully connected layers following feature extraction through convolution layers.
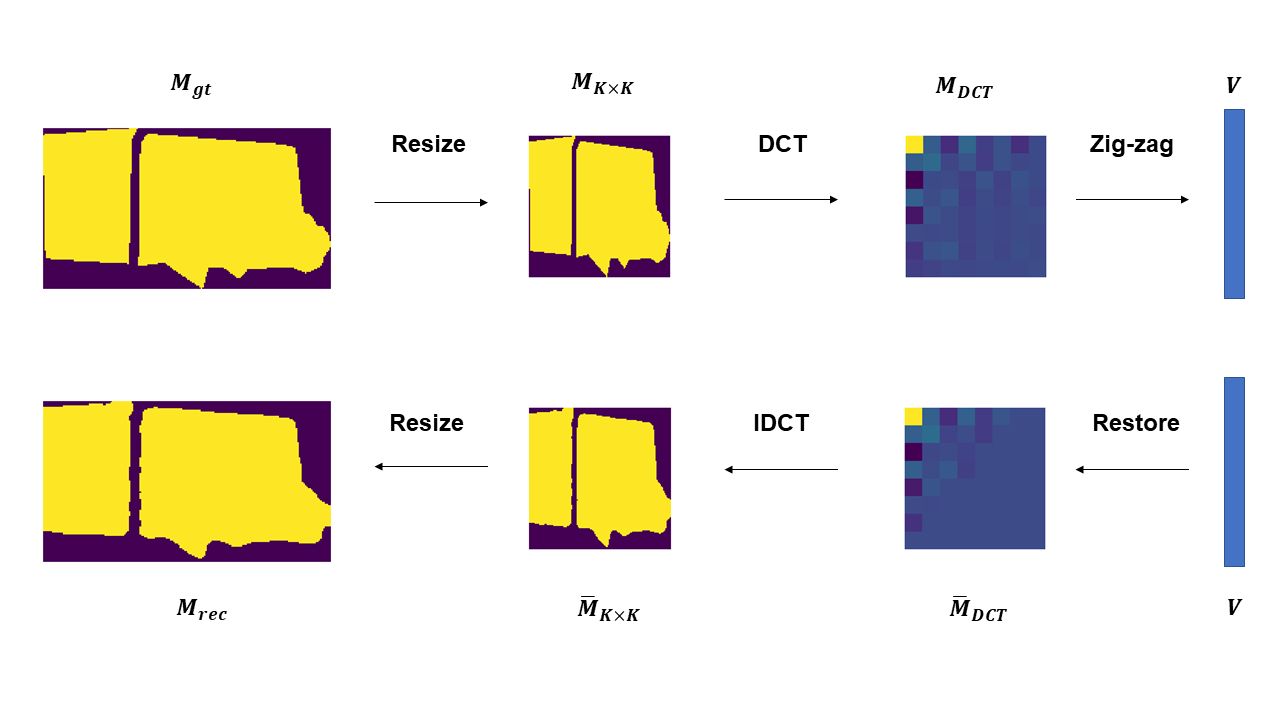
Figure 2: The pipeline of DCT mask representation.
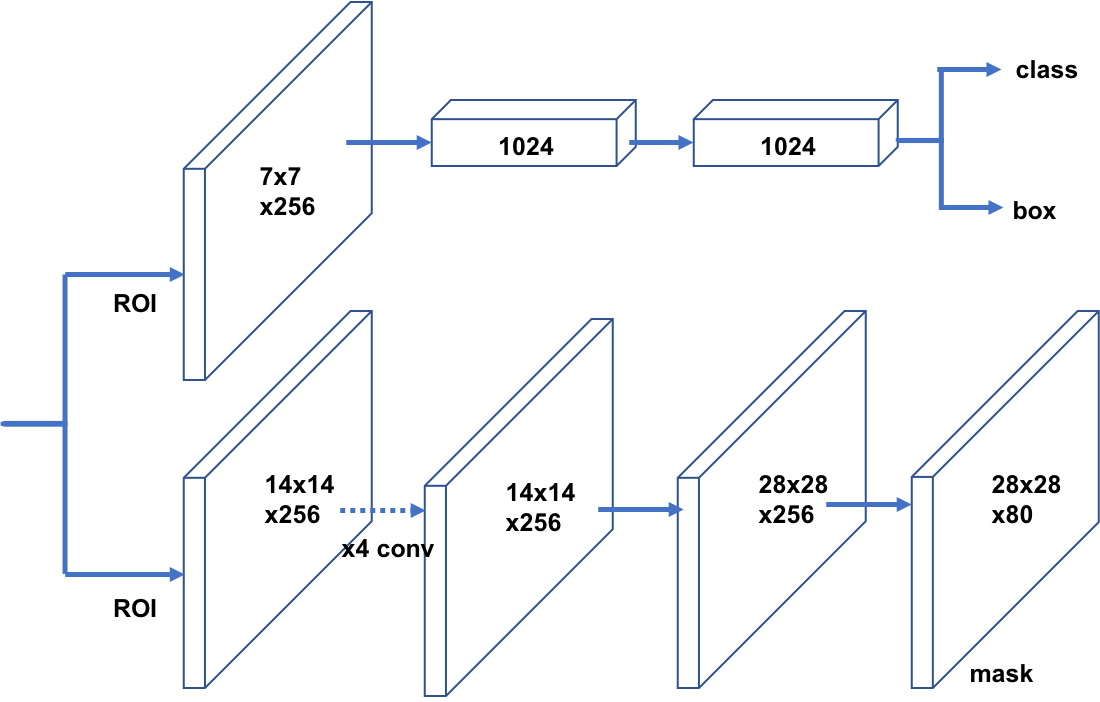
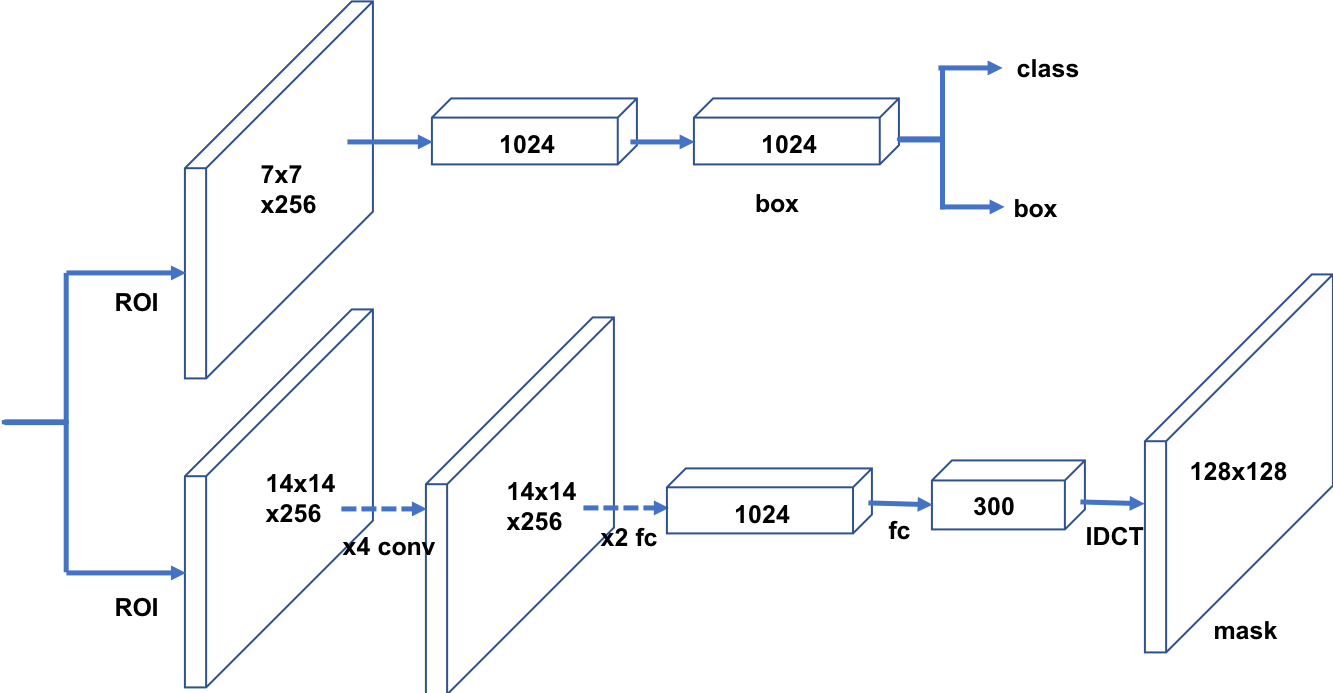
Figure 3: The implementation of DCT-Mask on the basis of Mask R-CNN.
Through this integration, the prediction task is transformed into a regression problem for the compact DCT vector, enabling high-quality mask representation with minimal impact on computational efficiency and operational speed.
Experimental Validation
The paper provides a comprehensive evaluation on the COCO and Cityscapes datasets, showing that DCT-Mask significantly improves the performance metrics of instance segmentation tasks. The method achieves higher AP scores across various scenarios, particularly for cases with high-quality annotations or complex backbone architectures.
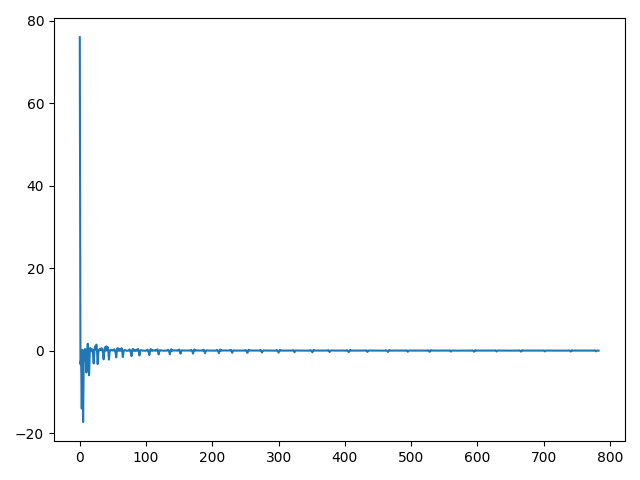
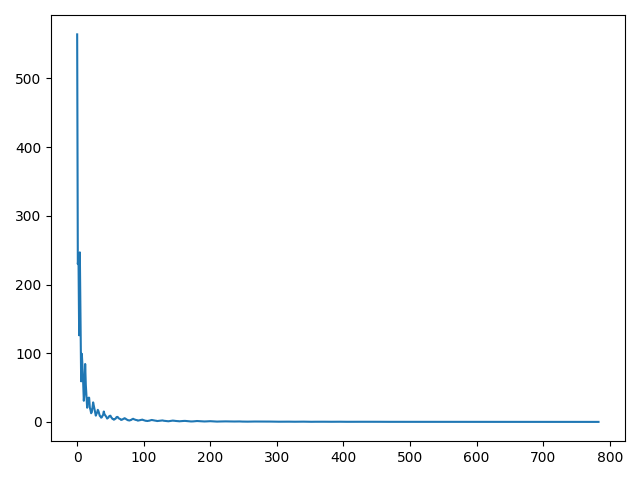
Figure 4: Mean value and Variance of DCT mask vectors on COCO 2017 val dataset.
The computational efficiency of DCT is evidenced by maintaining nearly the same processing speed as traditional low-resolution methods, while offering superior mask quality.
Implications and Future Directions
The DCT-Mask approach offers several implications for the field of computer vision, particularly in tasks where high fidelity in object delineation is necessary, such as autonomous driving and robotic perception systems. The ability to improve mask quality without sacrificing computational efficiency makes this method attractive for real-time applications.
Future research may explore the utilization of DCT-Mask with other instance segmentation frameworks or extend its application to diverse datasets and tasks requiring high-resolution spatial representations. Additionally, advancements could be pursued in optimizing DCT parameterization, further reducing computational overhead while maintaining or enhancing mask quality.
Conclusion
"DCT-Mask: Discrete Cosine Transform Mask Representation for Instance Segmentation" presents an effective solution to the challenges associated with mask representations in instance segmentation. By leveraging DCT, the method provides a high-quality, low-complexity alternative that integrates seamlessly with existing frameworks, offering a promising tool for both academic exploration and practical deployment in complex visual environments.