- The paper introduces SPiRL, which integrates learned skill embeddings and a prior to significantly accelerate reinforcement learning using large, unstructured datasets.
- It employs a deep latent variable model with an encoder-decoder architecture to map state-action sequences into a latent skill space, guiding the policy's exploration.
- The approach demonstrates faster convergence and superior performance in complex tasks such as maze navigation and robotic manipulation compared to traditional hierarchical methods.
Accelerating Reinforcement Learning with Learned Skill Priors
Introduction
Reinforcement Learning (RL) commonly faces the challenge of inefficient learning due to starting from scratch for each new task. The paper "Accelerating Reinforcement Learning with Learned Skill Priors" introduces a method to leverage prior agent experience for more efficient RL by learning skill priors and embeddings. These are extracted from large, unstructured datasets to guide the exploration of skill spaces, thus enabling the acceleration of RL in complex environments.
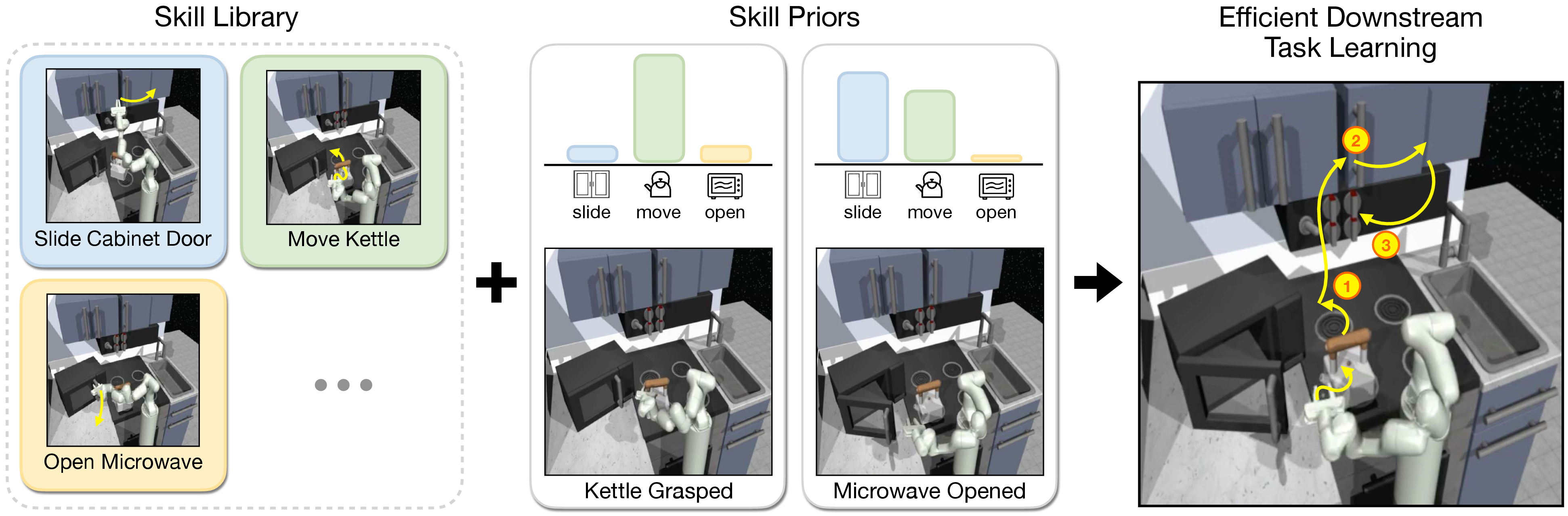
Figure 1: Intelligent agents can use a large library of acquired skills when learning new tasks. Instead of exploring skills uniformly, they can leverage priors over skills as guidance, based on the current environment state.
Methodology
The approach, named SPiRL (Skill-Prior RL), consists of two primary components: learning a skill embedding space and a skill prior. A deep latent variable model jointly learns these components from offline datasets containing state-action trajectories. The model uses a skill encoder-decoder architecture to map action sequences into a latent space that captures essential skills.
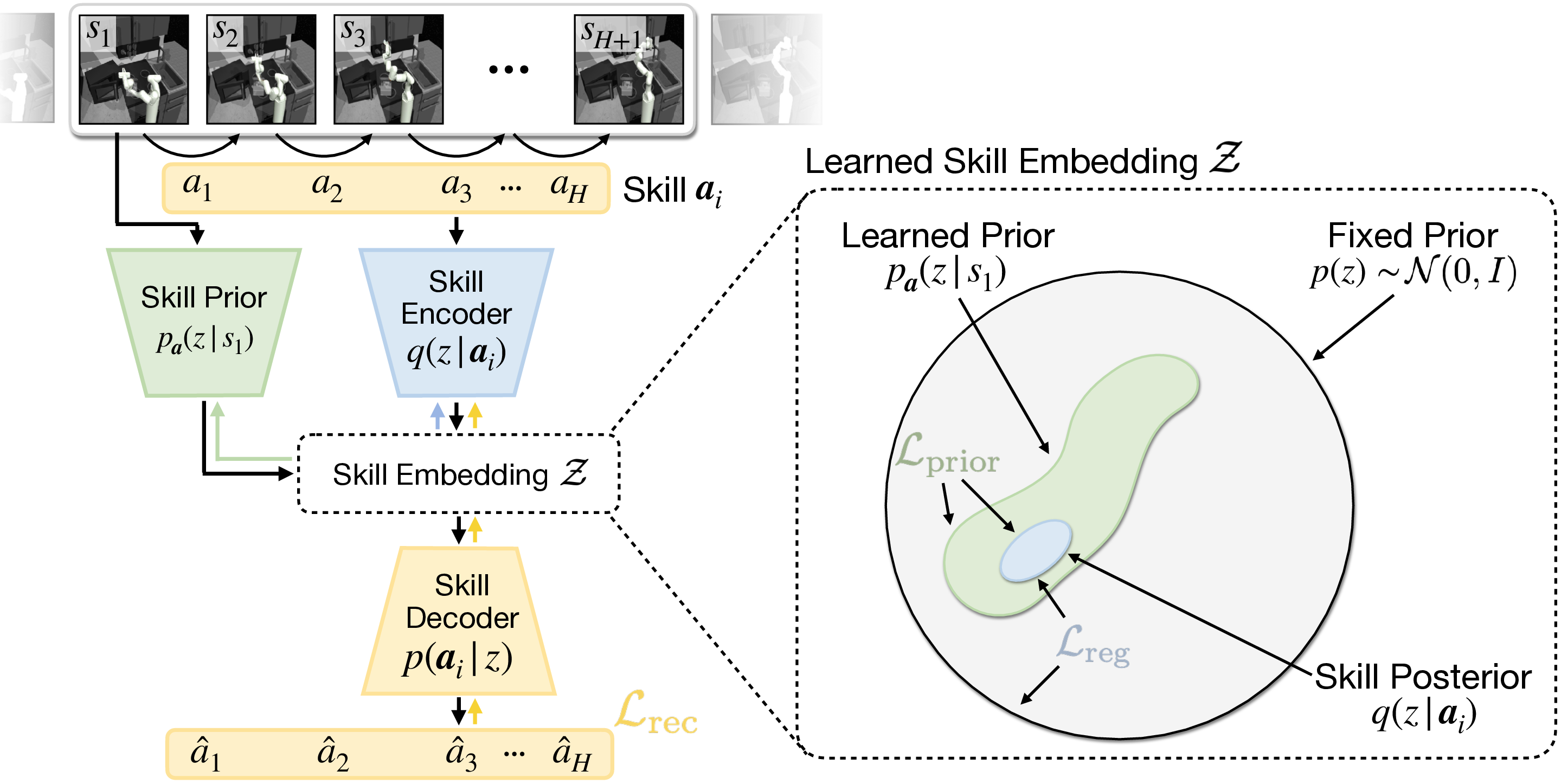
Figure 2: Deep latent variable model for joint learning of skill embedding and skill prior. The skill encoder maps the action sequence to a posterior distribution over latent skill embeddings.
The learned skill prior, conditioned on the current state, informs the policy on promising skills to explore, effectively reducing the dimensionality of the problem space and focusing exploration on plausible behaviors.
Experiments and Results
Experiments were conducted in a simulated maze navigation task and two robotic manipulation tasks (block stacking and a kitchen environment). The results demonstrated that SPiRL significantly enhances exploration and learning efficiency compared to baselines such as naive skill-space policies and hierarchical policies without skill priors.
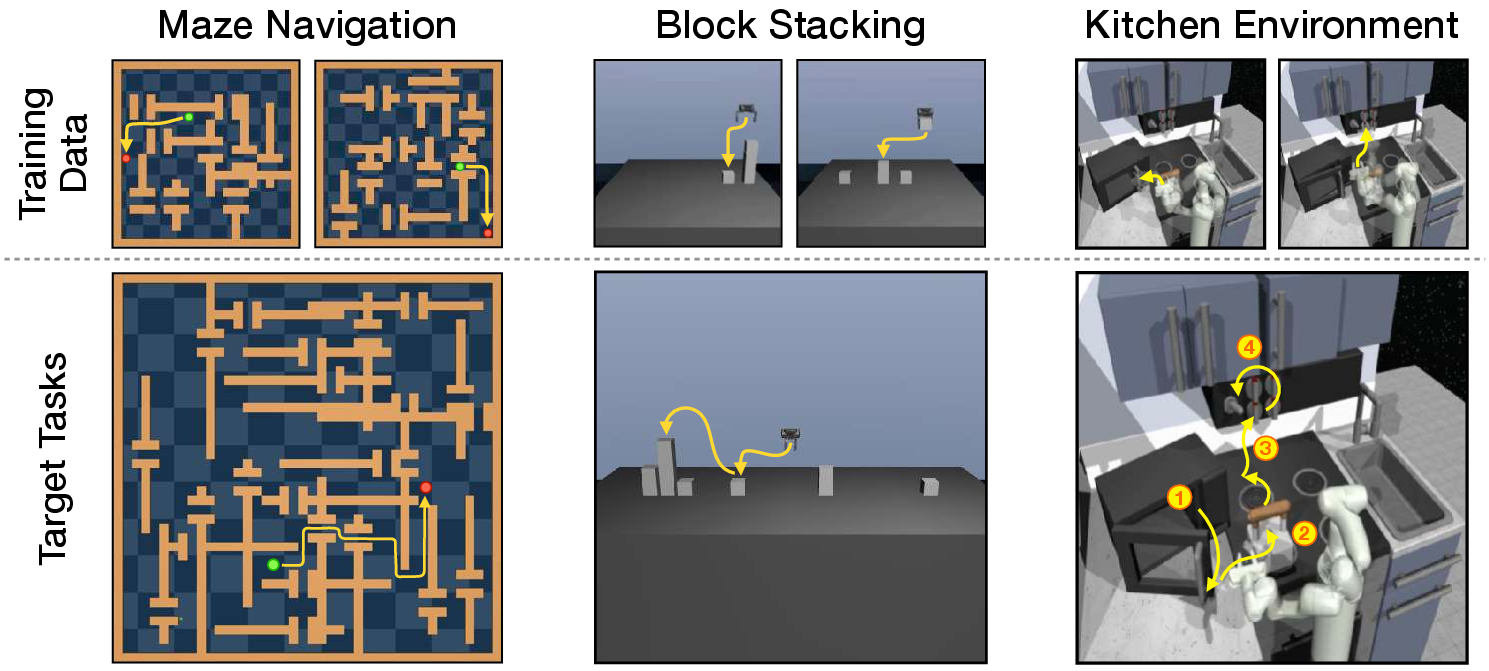
Figure 3: Diverse dataset collection from a wide range of training tasks for testing skill transfer to more complex target tasks.
The hierarchical policies using skill priors converged faster and achieved superior performance on complex, long-horizon tasks. In robotic manipulation scenarios, skill priors enabled the agent to recombine learned skills to achieve objectives not directly presented in the training data.
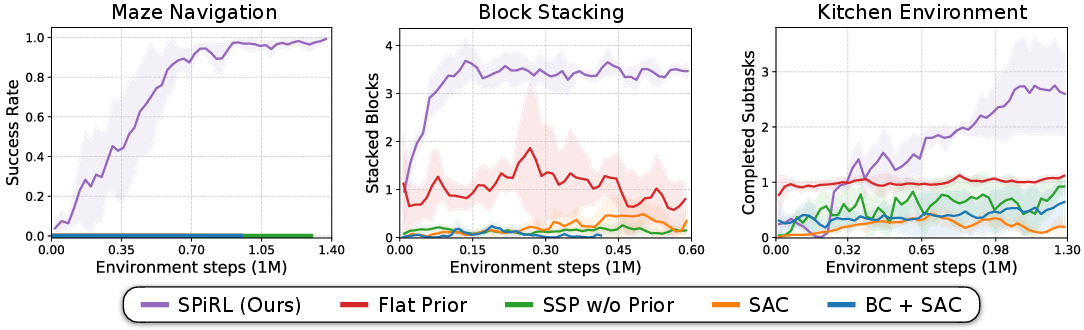
Figure 4: Downstream task learning curves showing the efficacy of learned skill embeddings and skill prior.
Practical Implications
The methodology's ability to scale learning from unstructured large datasets without task-specific reward information broadens its applicability to real-world systems. The approach is especially relevant in scenarios with costly data collection and safety concerns, such as autonomous driving or industrial robot operation.
Conclusion
"Accelerating Reinforcement Learning with Learned Skill Priors" presents a model that significantly advances RL by incorporating a learned skill prior and embedding, proving advantageous in complex and data-rich scenarios. Future work could explore semantic skill learning with flexible skill lengths and more complex skill prior distributions to enhance the adaptability and efficiency of RL in even more diverse environments.
This effort represents a critical step towards more intelligent agents that can leverage extensive prior experience, thus enhancing RL outcomes in practical applications.