- The paper presents a novel crowdsourced cough dataset enabling machine learning models to differentiate COVID-19 coughs from other respiratory sounds.
- It employs an XGB-based cough detection algorithm combined with expert annotation to filter and validate audio recordings effectively.
- The dataset’s comprehensive demographic and geographic analysis supports scalable digital health solutions and advances respiratory diagnostic research.
Introduction
The paper "The COUGHVID crowdsourcing dataset: A corpus for the study of large-scale cough analysis algorithms" provides a notable contribution to the field of cough sound analysis, specifically targeting the COVID-19 pandemic. Given the challenges posed by the pandemic in terms of screening and diagnosis, this corpus is designed to equip researchers with a robust dataset for developing machine learning models capable of differentiating coughs indicative of COVID-19 from other respiratory conditions.
Dataset Overview
The COUGHVID dataset is extensive, encompassing over 20,000 cough recordings sourced from a diverse demographic. The primary goal was to collate a dataset sufficiently large and varied to train machine learning algorithms effectively. To achieve this, the authors applied a multi-faceted approach:
- Crowdsourcing: Recordings were gathered through an online platform, ensuring broad participation by simplifying the submission process. Participants only needed to click once to record their coughs.
- Cough Detection and Cleaning: The dataset includes a pre-processing stage where recordings are filtered using a cough detection algorithm. This algorithm evaluates the likelihood of a recording containing a cough, allowing researchers to exclude non-cough sounds efficiently.
- Expert Annotation: Over 2,000 recordings were meticulously labeled by pulmonologists. They provided detailed annotations regarding the quality of the cough sound, type of cough, and presence of other audible clinical features. This expert labeling enhances the dataset's reliability and utility.
- Geographical and Demographic Analysis: The dataset was scrutinized to ensure demographic and geographic representativeness, confirming that COVID-19 labeled recordings corresponded to individuals from regions heavily affected by the virus at the time.
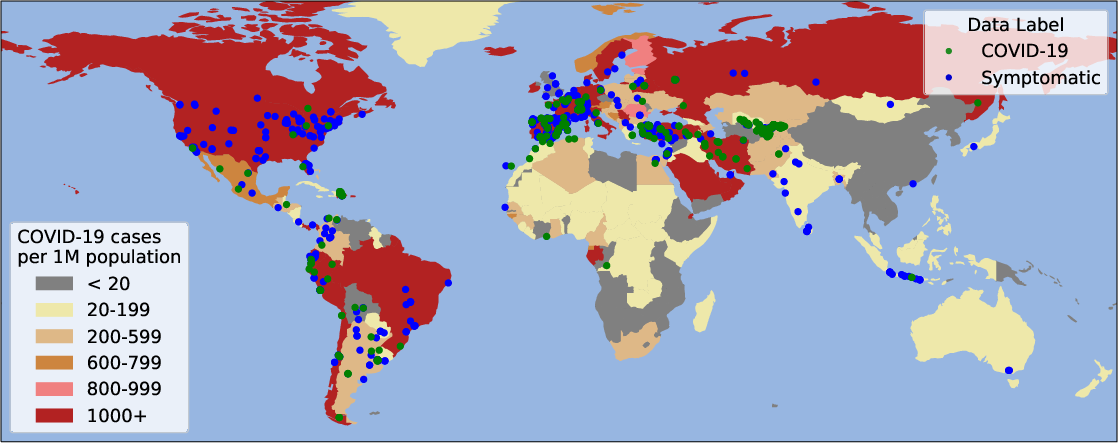
Figure 1: Cumulative COVID-19 cases in April and May 2020 per 1 million population, along with the GPS coordinates of the received recordings.
Cough Detection Algorithm
Central to the utility of the COUGHVID dataset is its cough detection algorithm, developed using an eXtreme Gradient Boosting (XGB) model. The algorithm classifies recordings based on a probability threshold, offering precision and recall sufficient for high-confidence identification of coughs. This approach ensures that machine learning models trained on this dataset can focus on biologically relevant signals.
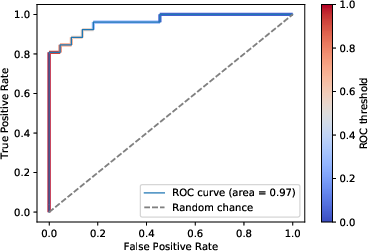
Figure 2: Receiver operating characteristic curve of the cough classifier.
Expert Annotation and Inter-rater Reliability
The expert annotations are invaluable as they provide a dimension of clinical validation. The study employed Fleiss' Kappa to assess inter-rater agreement among the pulmologists. Results indicated moderate agreement primarily for nasal congestion detection, demonstrating variability among diagnoses. Such variability underscores the complexity of audio-based COVID-19 diagnosis.
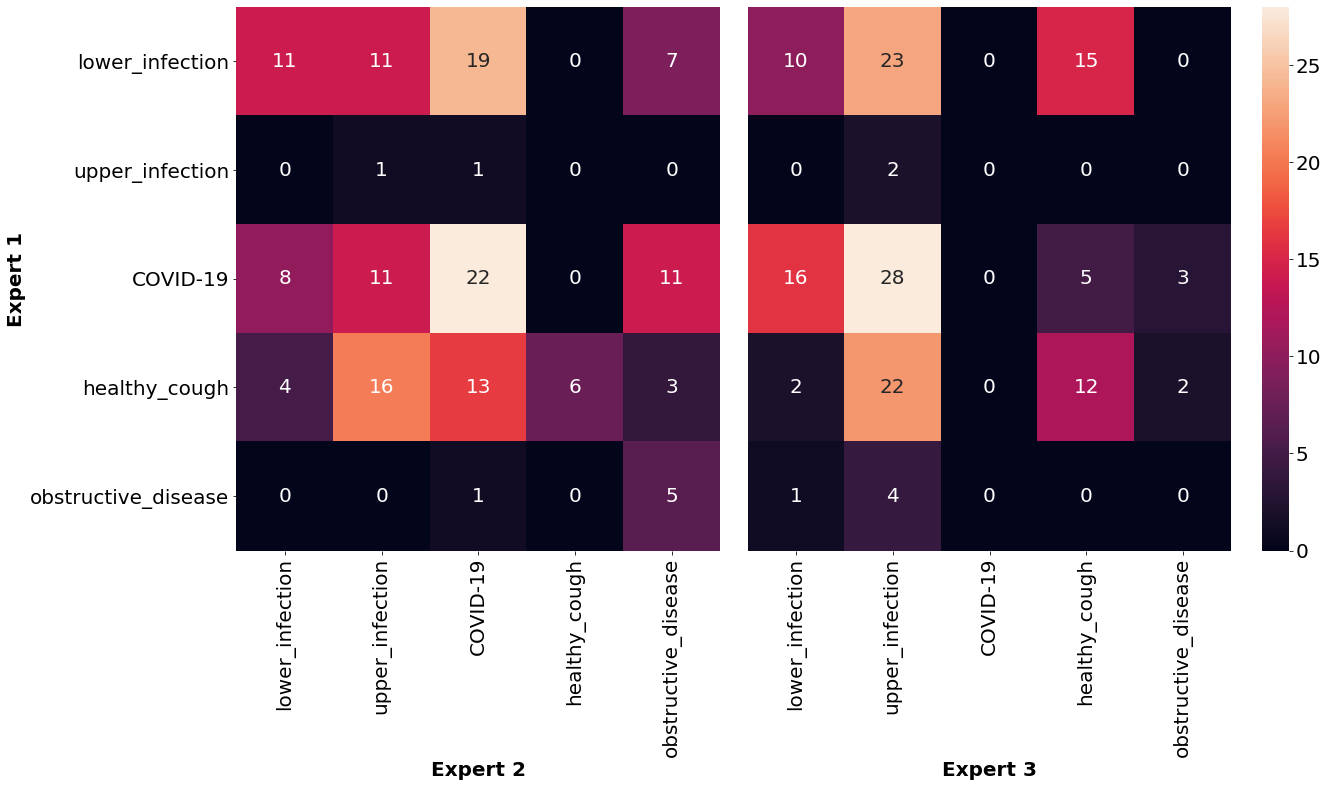
Figure 3: Confusion matrix of common cough recording diagnoses between pulmonology experts.
Implications and Future Directions
The COUGHVID dataset's impact on AI and ML is profound, offering novel pathways for model training in respiratory diagnostics. With its robust design and expert-labeled data, it is poised to aid in the development of scalable digital health solutions that leverage AI for respiratory disease detection, particularly COVID-19. Future developments could involve refinement of cough classification algorithms, potentially integrating more complex features like deep learning architectures.
The dataset also offers fertile ground for exploring distinctions among similar respiratory sounds, optimizing COVID-19 detection algorithms, and testing hypotheses concerning demographic and geographic factors affecting cough characteristics.
Conclusion
The COUGHVID dataset marks a substantial step forward in AI-assisted healthcare applications. By providing a publicly accessible, large-scale corpus of expertly labeled cough sounds, it facilitates the development of robust algorithms for respiratory diagnostics. The dataset's methodological rigor, combined with its attention to practical deployment considerations, will significantly contribute to exploring and addressing respiratory health challenges, particularly in the context of global pandemics like COVID-19.