- The paper introduces a hierarchical encoder-decoder model that integrates ASR outputs with probabilistic, confidence-weighted label mapping for SOAP note classification.
- The paper demonstrates that bi-LSTM based contextualization significantly improves macro F1 scores and robustness in speaker identification and SOAP labeling.
- The paper establishes a reproducible pipeline for clinical dialogue processing, emphasizing the practical importance of context-aware architectures in medical NLP.
Automated Classification of Medical Conversations for SOAP Note Generation
Introduction
The development of robust NLP frameworks for clinical dialogue understanding remains a critical challenge as medical conversations between clinicians and patients are lexically diverse, contextually rich, and often error-prone due to the necessity of ASR. "Towards an Automated SOAP Note: Classifying Utterances from Medical Conversations" (2007.08749) systematically addresses foundational NLU tasks essential for endpoint clinical note generation: utterance classification according to the canonical SOAP (Subjective, Objective, Assessment, Plan) framework and speaker diarization. The research reports comprehensive benchmarks and proposes both architectural and data pipeline advances specifically targeting the integration of ASR outputs, establishing new quantitative standards for the domain.
Dataset and Annotation Alignment
A proprietary dataset comprising 8,130 manually annotated doctor-patient conversations, including both human and ASR transcripts as well as gold-standard SOAP mappings, underpins the study. An essential methodological contribution is the probabilistic alignment of human-level utterance/annotation granularity onto ASR output, accounting for high ASR WER and diarization artifacts. This mapping leverages recursive substring alignment and DP to enable probabilistic, confidence-weighted label propagation from human references to potentially noisy ASR-derived utterances.
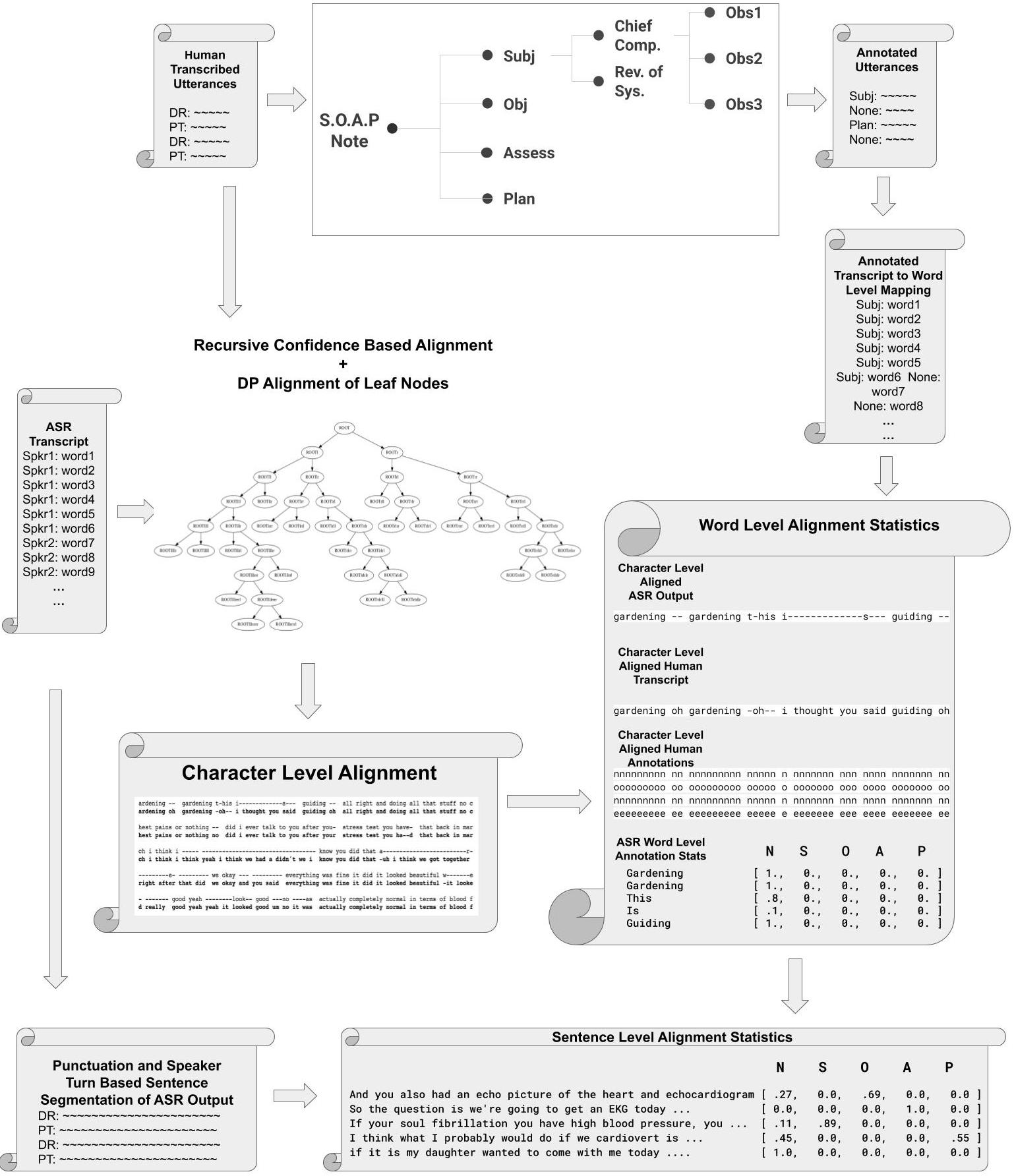
Figure 1: Probabilistic approach for mapping human-annotated SOAP and speaker labels to ASR-generated text spans, incorporating alignment confidence.
This alignment protocol allows the model to exploit both clean and noisy transcripts during supervised training, reflecting the realities of downstream deployment which are bounded by ASR performance. The ASR output is further processed via NLTK-driven sentence segmentation and diarization, resulting in utterance-level probabilistic label distributions for both SOAP and speaker class assignments.
Model Architecture and Training Paradigm
The architectural backbone is a hierarchical, contextualized encoder-decoder. Input utterances are embedded using an ELMo-based pipeline (fine-tuned on the medical corpus), aggregated via both ELMo layer attention and per-word attention. Crucially, utterance context is modeled using a stacked bi-LSTM, capturing inter-utterance dependencies essential for accurate clinical categorization—demonstrably outperforming flat models lacking such contextualization.
The model is trained in a multi-task framework with dual LSTM decoders handling speaker identification and SOAP section classification simultaneously. Losses are weighted by batch-class frequencies and computed using smoothed (probabilistic) targets for ASR-mapped data. Optimization is handled via Adam with scheduled dropout and strict gradient clipping; hyperparameters are chosen through Bayesian optimization routines. Label smoothing on ASR-derived data, distinct from one-hot human targets, directly incorporates alignment confidence into the loss landscape.
Empirical Evaluation
Models are evaluated on both human and ASR transcripts, with and without ASR data present during fine-tuning. Evaluation criteria include accuracy, macro F1, multiclass AUROC, and macro-average AUPRC.
Key numerical results:
- Models with bi-LSTM contextualization yielded absolute macro F1 gains of $6$–7% for SOAP section classification and $7$–11% for speaker classification compared to less hierarchical architectures.
- The best SOAP section classifier achieves a macro F1 of $0.48$ (human transcripts), nearly matching the estimated inter-annotator ceiling (macro F1 of $0.47$).
- Contextualization particularly benefits rare SOAP classes (Objective, Assessment, Plan), with up to 18% improvements in per-class F1.
- Inclusion of ASR data in training provides consistent speaker classification gains on the ASR test set (macro F1 increases up to $0.50$ from $0.42$) but limited improvements for SOAP sections, likely due to overall label uncertainty and inter-annotator variance.
Implications and Theoretical Insights
This study establishes a rigorous, reproducible pipeline for evaluating models at the intersection of ASR and clinical NLU, including realistic label smoothing and robust utterance alignment. The documented performance gains from contextualizing utterances reinforce that medical dialogue processing requires architectures capable of modeling non-local context and speaker/role dependencies that cannot be captured by static or flat BoW representations.
A notable finding is the task-dependence of ASR adaptation benefit. Speaker identification, being less semantically volatile in the face of ASR errors, sees substantial robustness boosts from training on ASR-mapped data. In contrast, SOAP section labeling, which is tightly coupled to specific phrasing and clinical content, shows little further improvement under the current ceiling effect imposed by inter-annotator variability.
Limitations and Future Directions
The largest limitation is direct dependence on the granularity and subjectivity of human annotations. Since assigning evidence utterances to SOAP sections is inherently noisy, further improvements in pure classification metrics may offer diminishing practical returns. Future research should shift focus towards entire note generation and extraction quality as opposed to utterance-wise fidelity.
Architectural extensions could include:
- Integrating multimodal ASR-NLU models to further reduce diarization and segmentation errors.
- Employing large-scale self-supervised pretraining (e.g., transformer-based architectures) to absorb conversational pragmatics and rare event composition.
- Applying multi-evidence reasoning frameworks for aggregation of highly redundant conversational cues, as conversations are generally repetitive and key information is distributed.
Conclusion
This work sets a new empirical baseline for utterance-level clinical note annotation from medical conversations, introducing ASR-adapted, probabilistic label mapping and hierarchical deep learning models that approach human agreement rates for SOAP classification. The results cement the importance of context-aware architectures and provide a robust foundation for subsequent research into end-to-end automated clinical documentation systems. The modular, alignment-based approach to leveraging noisy ASR outputs distinguishes the methodology, favoring practical integration with arbitrary state-of-the-art ASR engines.