- The paper shows that a logarithmic increase in network width permits effective pruning to achieve an ε-approximation of the original network.
- It leverages the SubsetSum problem to connect combinatorial techniques with neural network approximation methods.
- The approach significantly optimizes resources and guides the development of practical, efficient network pruning algorithms.
Optimal Lottery Tickets via SubsetSum: Logarithmic Over-Parameterization is Sufficient
The concept of optimal lottery tickets within the context of neural networks represents a refinement in understanding how sparse and efficient networks can be derived by pruning over-parameterized networks. This paper, titled "Optimal Lottery Tickets via SubsetSum: Logarithmic Over-Parameterization is Sufficient" (2006.07990), presents a substantial theoretical advancement by showing that logarithmic over-parameterization suffices for the approximation of any targeted neural network.
Introductory Concepts and Background
In large-scale machine learning models, the challenge of reducing computational footprint, while maintaining accuracy, is pivotal. Pruning, sparsification, and other optimization techniques have aimed to achieve leaner models that use fewer resources without compromising performance. Prior research established the possibility of pruning networks extensively but often required significant over-parameterization. The strong lottery ticket hypothesis suggested that accurate sparse networks could exist within larger networks, aligning with efforts to minimize training overhead.
The recent work by Malach et al. provided a theoretical footing for the lottery ticket hypothesis but relied on polynomial over-parameterization, marking a gap between theoretical proofs and empirical setups that suggested narrower networks could suffice.
Main Contributions and Theoretical Framework
The paper addresses this discrepancy by establishing that a logarithmic factor denotes sufficient network widening rather than a polynomial factor. This is crucial for the hypothesis's practical application, as it drastically reduces the necessary computational resources for providing accurate approximations via pruning.
The core innovation relies on connecting the problem of approximating random ReLU networks with the classical SubsetSum problem. This linkage allows the authors to leverage existing results in random subset sums to prove that only a logarithmic number of samples are needed to achieve ϵ-approximation of neural network weights.
Theoretical Results
The primary theoretical contribution is encapsulated in the following key theorem:
- Logarithmic Over-Parameterization: For a neural network of width d and depth l, a randomly initialized network that is O(log(dl)) wider and twice as deep can be pruned to approximate the original network with ϵ error.
This result significantly refines the earlier bounds, enabling a more efficient search for lottery tickets and suggesting that lower computational resources can achieve the desired neural network performance.
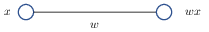
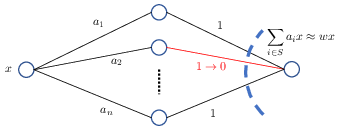
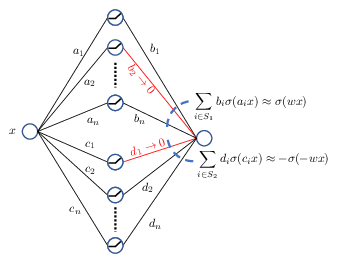
Figure 1: Target weight approximation using SubsetSum methods.
Implementation Details
Implementation gleaned from these theoretical results suggests algorithmic adjustments where networks are initialized with consideration towards uniform distribution sampling. The theoretical bounds have practical implications in reducing initialization configurations, focusing on efficient pruning strategies, and aligning with insights from subset sum problem results.
Further experiments were conducted, affirming the theoretical results by demonstrating that the derived strategies allowed for effective pruning to achieve comparable accuracy in empirical setups.

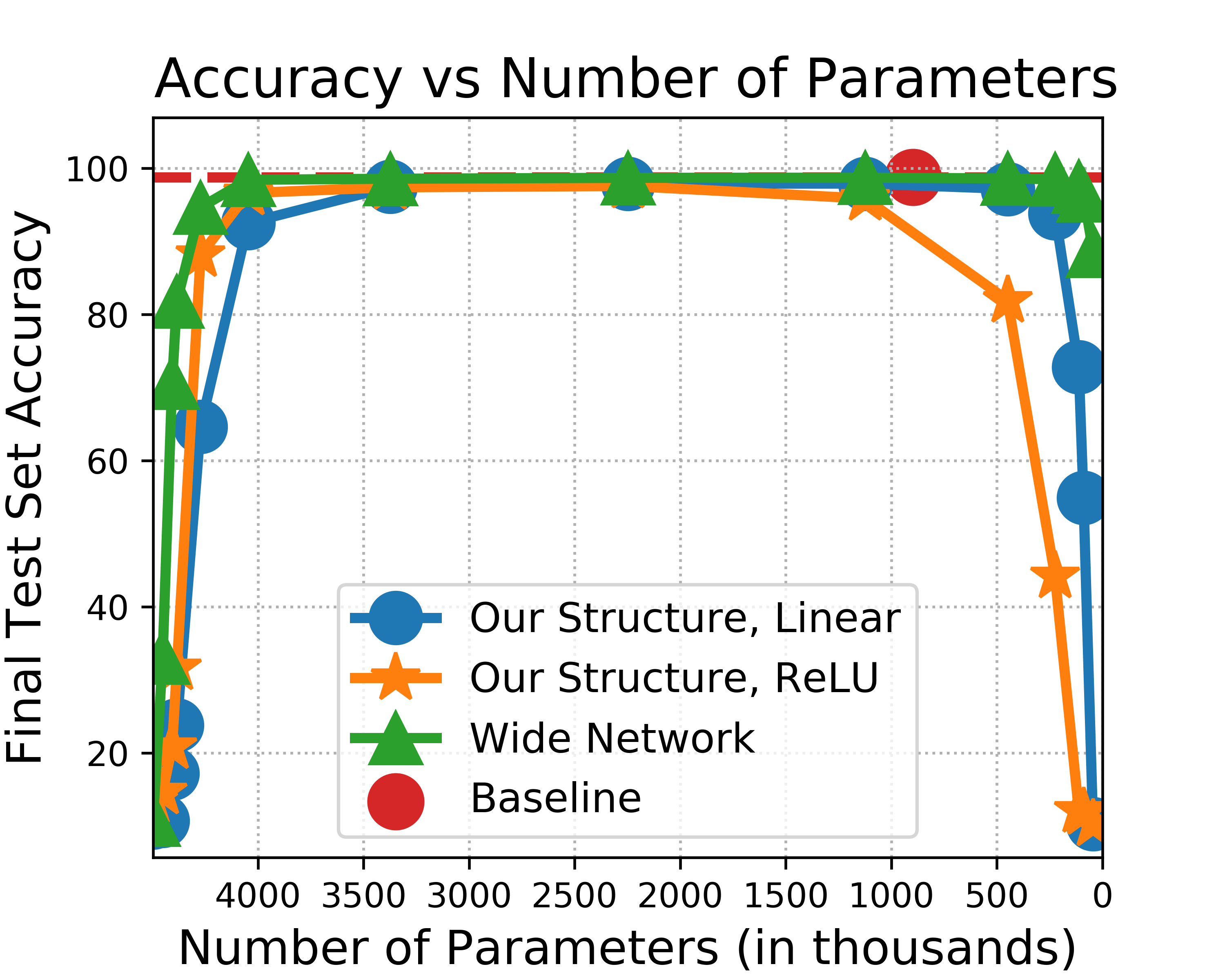
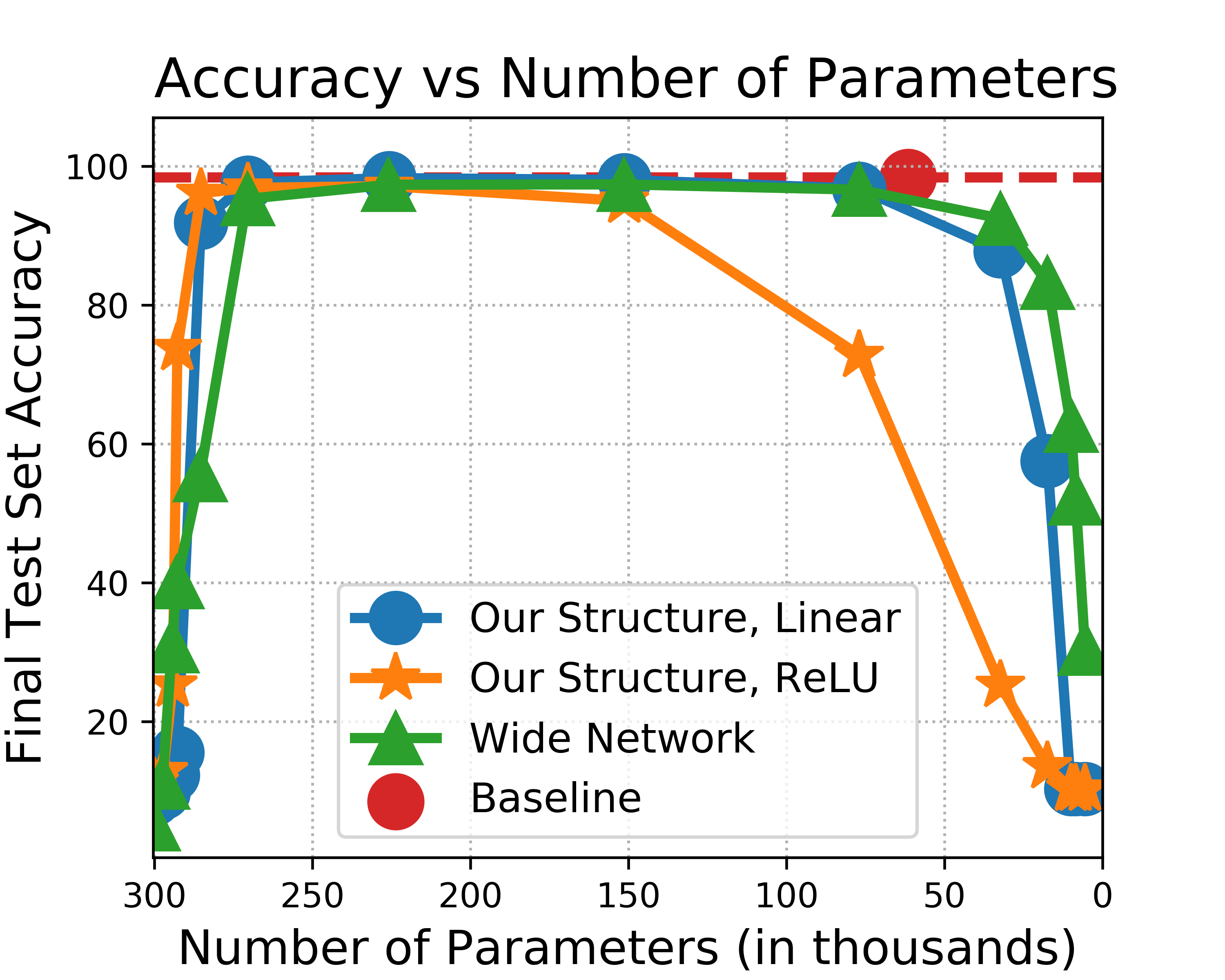
Figure 2: Two-Layer Fully Connected Network with efficient pruning.
Future Implications
The ramifications of this paper are two-fold:
- Resource Optimization: The logarithmic over-parameterization drastically cuts down the resources needed for training networks that maintain high accuracy, facilitating environmentally friendly and cost-effective AI applications.
- Algorithmic Refinements: Future research can focus on honing the pruning algorithms based on these insights, enhancing robustness while leveraging structurally sparse mechanisms.
Conclusion
This paper substantiates a significant theoretical progression in artificial neural network optimization. By proving that logarithmic over-parameterization suffices, it positions the lottery ticket hypothesis as a feasible strategy for practical AI deployments, implying a tangible shift in how large-scale models may be constructed and optimized in resource-constrained environments.