- The paper introduces a dual-network self-supervised learning algorithm that eliminates negative samples.
- It employs an online predictor and a slowly updated target network to achieve robust performance on benchmarks such as ImageNet.
- Empirical results show 74.3% top-1 accuracy, demonstrating BYOL’s potential in transfer and semi-supervised learning tasks.
Bootstrap your own latent: A new approach to self-supervised Learning
Introduction to BYOL
"Bootstrap Your Own Latent" (BYOL) is a novel self-supervised learning algorithm designed for image representation learning. Unlike traditional contrastive learning methods that require negative pairs, BYOL leverages two interacting neural networks, the online and target networks, to learn meaningful representations without using negative samples. The method boasts robust learning capabilities, achieving substantial top-1 classification accuracy improvements on benchmarks such as ImageNet, surpassing existing state-of-the-art techniques.
The core mechanism of BYOL involves the online network predicting transformations of an image, while the target network updates itself via a slow-moving average of the online network parameters. The elimination of negative pairs marks a significant paradigm shift in self-supervised learning approaches, with BYOL demonstrating heightened resilience to choices of image augmentation.
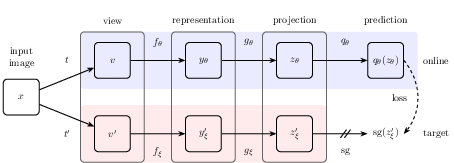
Figure 1: BYOL's architecture. BYOL minimizes a similarity loss between q(z) and sg(z)′, where θ are the trained weights.
Implementation Details
Network Architecture
The BYOL algorithm utilizes two subnetworks: the online and target networks. Both share identical architectures but differ in weight parameters. Each network comprises an encoder, a projector, and, exclusively for the online path, a predictor.
- Encoder: The implementation typically uses a ResNet architecture, with representations extracted from the final average pooling layer.
- Projector and Predictor: Multi-layer perceptrons (MLP) housing linear layers with activations like ReLU. The predictor ensures non-collapsed feature learning, playing a critical role in maintaining informational diversity between networks.
Training Parameters
BYOL trains using stochastic gradient descent and employs techniques such as LARS optimization and cosine learning rate decay. It utilizes a global weight decay while excluding biases and batch normalization parameters from both LARS adaptation and decay. The parameter τ is adjusted throughout training to ensure stable target network updates, gradually approaching 1.
Training typically occurs over large batch sizes (e.g., 4096 on TPU), although BYOL's robustness translates to effective performance across reduced batch sizes, combating challenges faced by conventional approaches in similar settings.
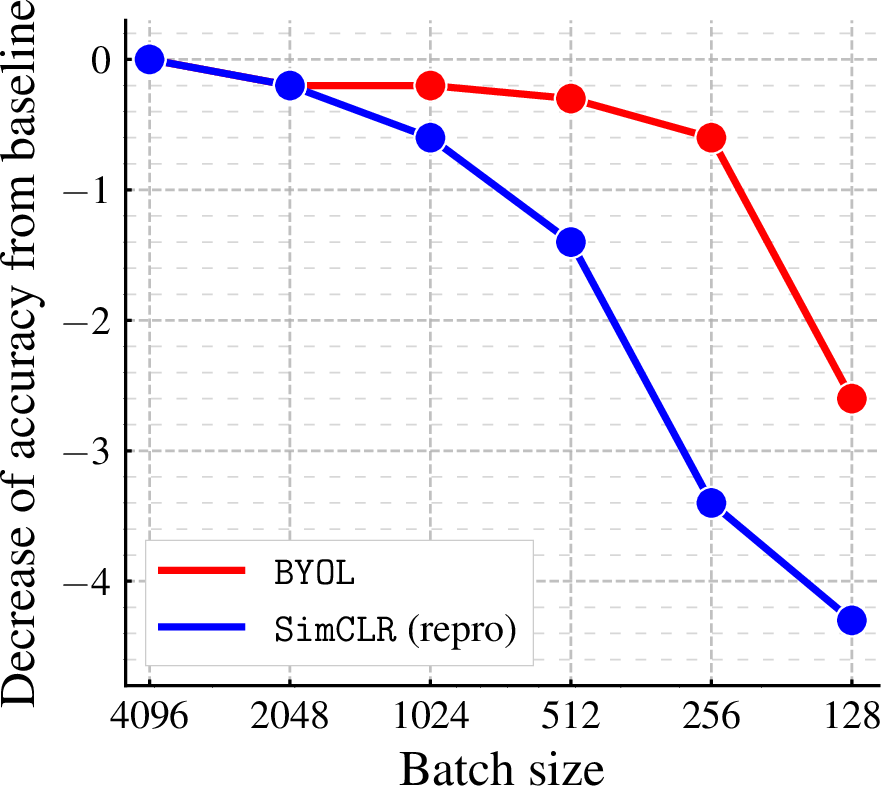
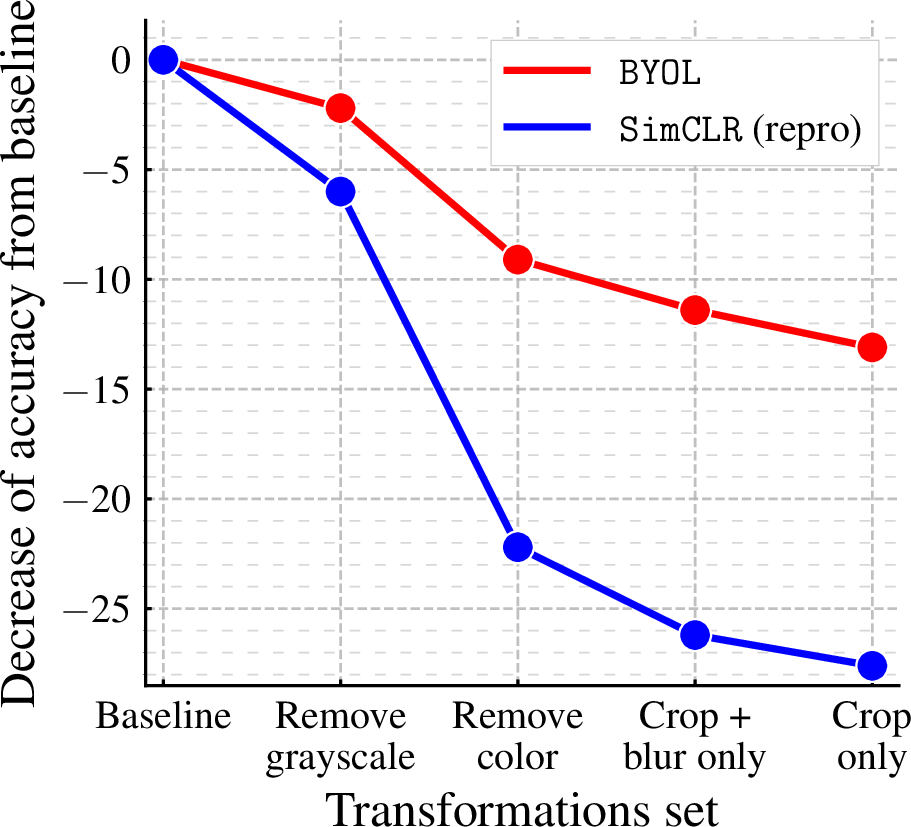
Figure 2: Impact of batch size on BYOL's resilience, showing less dependency compared with contrastive methods.
Empirical Evaluation
BYOL is tested across several benchmarks:
- ImageNet: Achieves 74.3% top-1 accuracy using a ResNet-50, outperforming previous unsupervised methods.
- Semi-supervised Learning: Demonstrates superior performance with subsets of labeled data, closing the gap between self-supervised and fully supervised methodologies.
- Transfer Learning Tasks: BYOL's representations generalize effectively across diverse datasets including CIFAR, SUN397, and VOC.
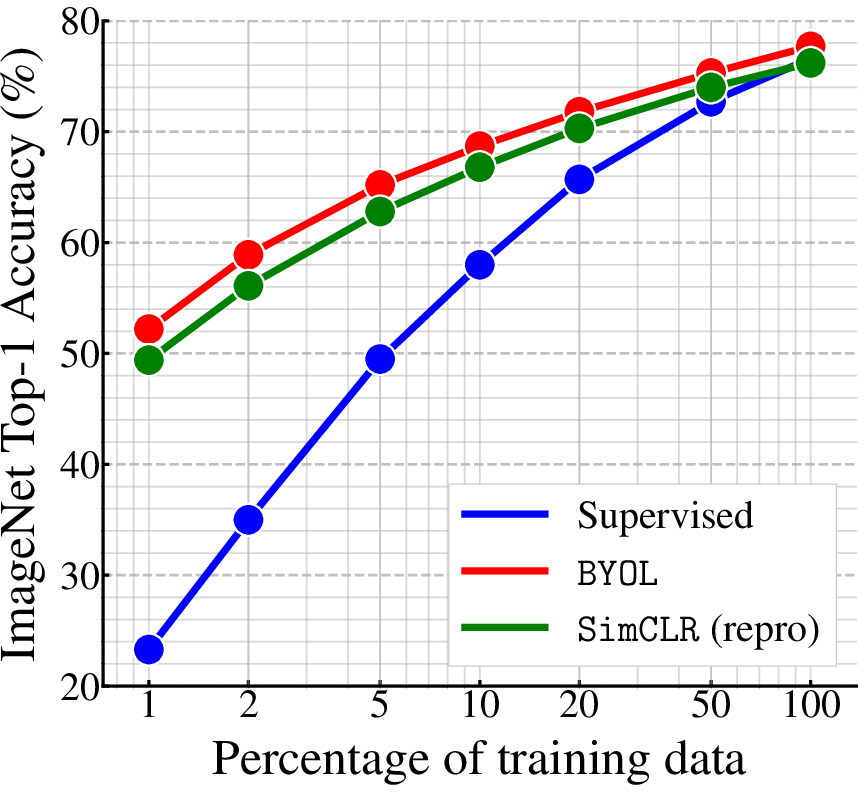
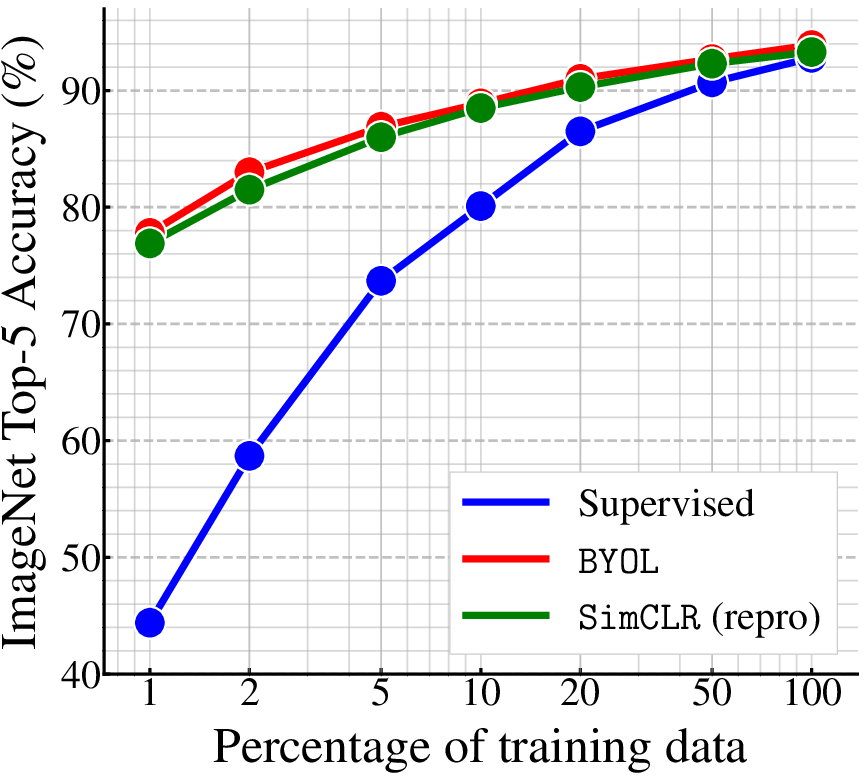
Figure 3: Top-1 accuracy across various architectures when evaluated on ImageNet.
BYOL exhibits profound transfer capability, seamlessly adapting learned representations to tasks such as semantic segmentation, object detection, and depth estimation, further validated by robust performance metrics across datasets like NYU v2 Depth and VOC2012.
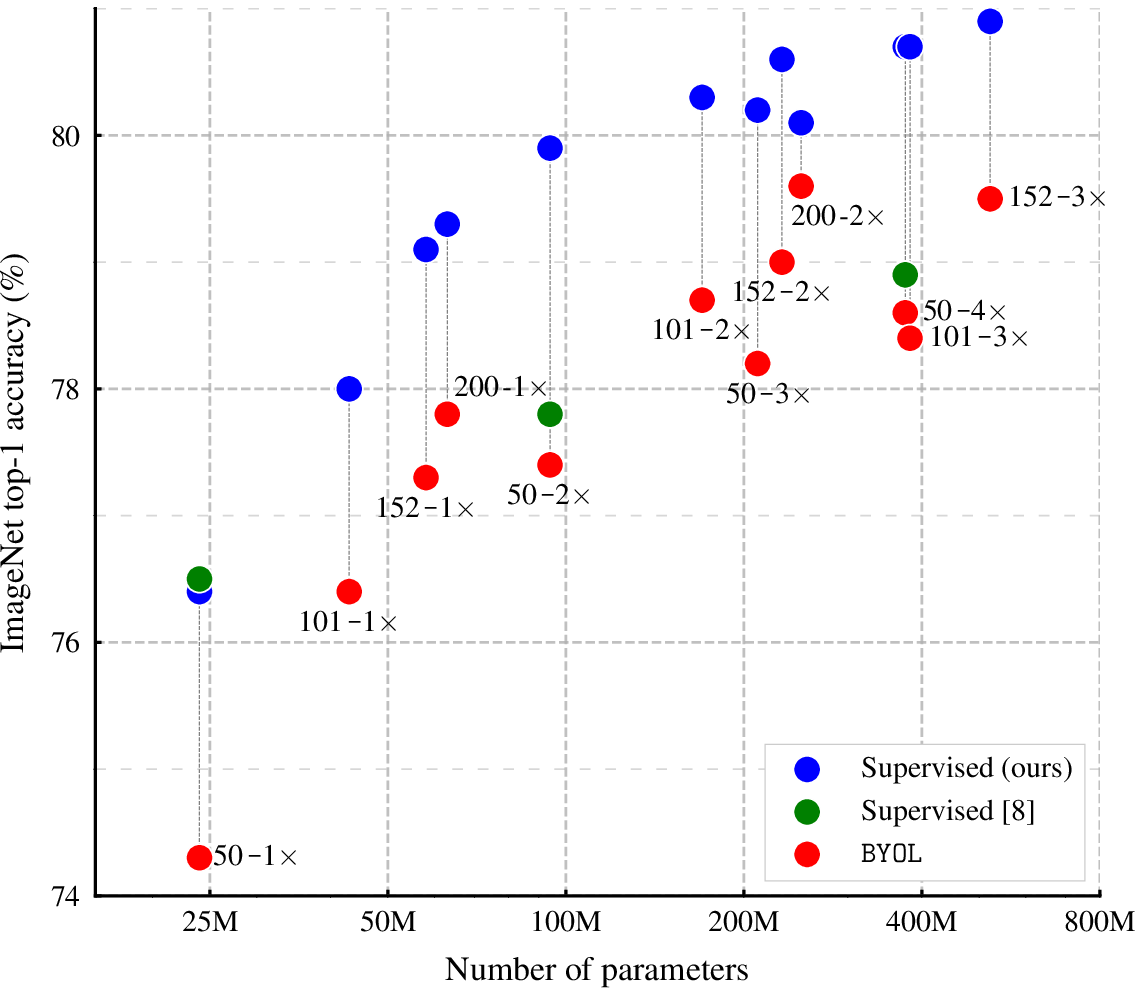
Figure 4: Performance in linear evaluation across different ResNet architectures, indicating BYOL’s adaptability.
Future Work and Implications
BYOL shifts away from contrastive approaches, sparking conversations on optimal augmentation strategies essential for broader modalities beyond images, such as audio and video. Its success encourages the exploration of augmentation automation, which holds potential for cross-disciplinary applications.
The robustness and scalability offered by BYOL posit it as a keystone for advancements in self-supervised learning, paving the way for new avenues in unsupervised sensory learning, all while sidestepping the pitfalls of negative sample dependency.
Conclusion
BYOL marks a notable chapter in self-supervised learning, championing stability and achieving impressive benchmarks through a simplistic yet powerful architecture. Its unique approach facilitates more efficient and universal representation learning, unlocking pathways for the integration of self-supervised techniques across varied data types and application domains.
The removal of negative pairs in representation learning widens BYOL's applicability, making it a cornerstone model for future innovations within the field of AI-driven perception systems.