- The paper introduces a method combining structured pruning and 8-bit quantization to significantly compress LSTM-based speech enhancement models for hearing aids.
- It employs skip RNN cells to dynamically reduce computational load while preserving high-quality audio, meeting strict hardware constraints.
- Evaluations demonstrate comparable SDR scores and perceptual quality, ensuring low-latency and energy-efficient performance on constrained devices.
TinyLSTMs: Efficient Neural Speech Enhancement for Hearing Aids
Introduction
The paper "TinyLSTMs: Efficient Neural Speech Enhancement for Hearing Aids" addresses the critical challenge of deploying speech enhancement (SE) algorithms within the constraints of hearing aids (HAs). These devices necessitate models with minimal computational and storage requirements due to their limited hardware capabilities, namely reduced memory capacity and power constraints of microcontroller units (MCUs). Modern SE systems rely on RNNs, especially long short-term memory (LSTM) networks, for effective noise suppression. The research outlines how model compression, specifically pruning and integer quantization, can bridge the gap to create efficient neural networks that are feasible for deployment on HAs. The results highlight a substantial reduction in model size and operations, with negligible loss in perceptual quality, enabling real-world application in HAs.
Model Constraints and Methodology
The HA form factor necessitates several hardware constraints: compute complexity must not exceed 1.55 million operations per second to achieve the desired sub-10ms latency; model size must be under 0.5 MB due to flash memory constraints; and working memory is limited by the device SRAM to 320 KB. The authors introduce a methodology focused on pruning and quantization to generate compressed RNN SE models that adhere to these requirements.
- Pruning: By employing structured pruning, weights in the LSTM and fully connected (FC) layers were organized in groups, allowing for efficient removal without incurring performance degradation. A novel aspect of this approach is the direct learning of pruning thresholds, reducing the need for computationally intensive hyperparameter searches.
- Quantization: The research implements training-aware quantization of weights and activations to 8 bits. This approach ensures the model is robust to quantization noise while maintaining integer arithmetic, which is less power-intensive than floating point operations.
- Skip RNNs: Skip RNN cells are introduced to further decrease computational load by allowing state updates to be skipped dynamically, conditioned on input signal characteristics, thus reducing the operational demand on the MCU.
The TinyLSTMs were evaluated using both objective measures and subjective perceptual tests. In terms of objective metrics, models achieved comparable SDR scores to existing large-scale systems while adhering to the HA constraints, particularly excelling in computational latency and energy efficiency.
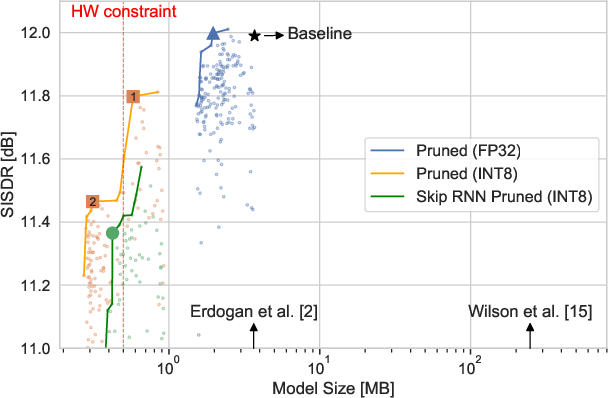
Figure 1: MS vs. SISDR. Each point represents a model checkpoint and lines represent a Pareto front.
Subjective evaluation was conducted to assess the auditory quality of the enhanced audio compared to the baseline models. Listeners showed a consistent preference for processed audio, confirming that the compressions did not compromise perceptual quality.
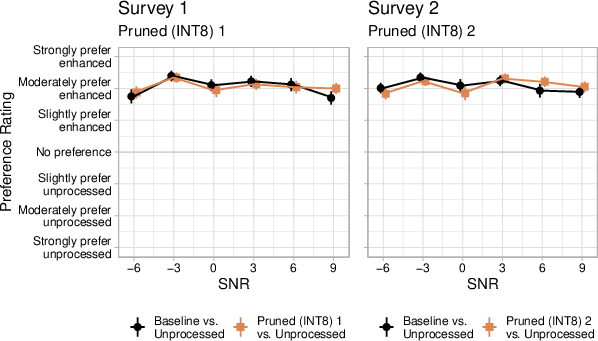
Figure 2: Preference of perceptual study participants for enhanced audio vs. unprocessed audio for both uncompressed and pruned models across input SNR's.
Implications and Future Work
This paper provides a blueprint for designing efficient SE models deployable on resource-constrained hardware. The investigations into pruning methods and quantization processes offer a pathway for future enhancements in low-power, high-efficiency neural networks. The successful application and optimization of LSTMs for HA devices suggest potential extrapolation to other portable devices requiring low-latency speech enhancement, such as mobile phones or IoT devices.
Conclusion
The TinyLSTMs method delineates a robust framework for achieving efficient speech enhancement applicable to hearing aids, balancing resource constraints with computational demands. The significant reduction in model size and operations without perceptual quality loss demonstrates the viability of deploying advanced neural networks on limited hardware. This approach paves the way for further research into optimizing neural architectures for low-power, real-time applications in wearable and portable devices.

