- The paper introduces a hybrid approach combining static analysis with a novel neural network to generate valid, context-aware code suggestions.
- It employs subtoken encoding with GRU-based architectures and a projection layer to minimize prediction latency and manage out-of-vocabulary tokens.
- Evaluation reveals state-of-the-art top-1/top-5 accuracy and effective repetition detection, ensuring interactive performance within IDE constraints.
Sequence Model Design for Code Completion
This paper addresses the challenges of integrating LMs into modern integrated development environments (IDEs) for code completion. It focuses on meeting practical constraints such as generating valid code, providing instantaneous suggestions, and maintaining a small model size suitable for local developer workstations. The authors introduce a hybrid approach that combines static analysis with a novel neural network architecture to achieve state-of-the-art accuracy while adhering to these constraints.
Background and Motivation
Code completion is a crucial feature in modern IDEs, offering correctness checking, typing assistance, and API search [muaruaÈoiuempirical]. While static analysis-based suggestions guarantee validity, they often lack relevance [Bruch:2009:LEI:1595696.1595728]. LMs can improve relevance by exploiting the naturalness of source code [Hindle:2012:NS:2337223.2337322, Nguyen:2015:GSL:2818754.2818858], but integrating them into IDEs poses several challenges.
One key challenge is latency; suggestions must appear within 100ms to be perceived as instantaneous [Miller:1968:RTM:1476589.1476628, Nielsen:1993:UE:529793]. This constraint limits LM size and the amount of pre- and post-processing. Model size is another concern, as large neural networks can exceed developer machines' memory and disk capacity [DBLP:journals/corr/JozefowiczVSSW16]. Furthermore, code completion should always produce compilable code, a guarantee that LMs alone cannot provide.
Model Architecture and Design
The proposed model combines the strengths of static analysis and LMs to address the aforementioned challenges. It leverages static analysis to enumerate valid keywords and in-scope identifiers, while the LM provides a probability distribution over these suggestions. The model employs a hybrid character-level input representation with token-level output to handle out-of-vocabulary (OOV) tokens and minimize prediction latency.
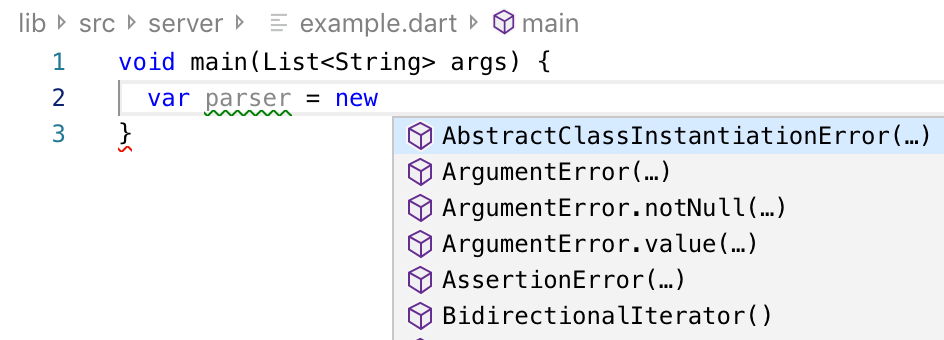
Figure 1: Completion suggestions before ML ranking, showcasing the state of suggestions before the model is applied.
A key innovation is the inclusion of a local repetition detection mechanism, inspired by pointer networks [DBLP:journals/corr/BhoopchandRBR16]. This component predicts whether the next token repeats one from the input sequence, allowing the model to assign probability to OOV tokens, which are common in source code due to the prevalence of identifier names.
To further enhance the model's ability to represent new words, the input sequences are encoded using subtoken encoding, breaking identifier names into morphemes based on camelCase and snake_case conventions. This approach allows the model to relate lexemes such as "ResourceProvider" and "FileResourceProvider."
The RNN architecture utilizes Gated Recurrent Unit (GRU) cells [DBLP:journals/corr/ChoMGBSB14] and a projection layer [DBLP:journals/corr/SakSB14] to reduce computational cost and prediction latency. The projection layer, placed between the hidden layer and the softmax output, significantly reduces the number of network parameters, which is crucial for large vocabularies.
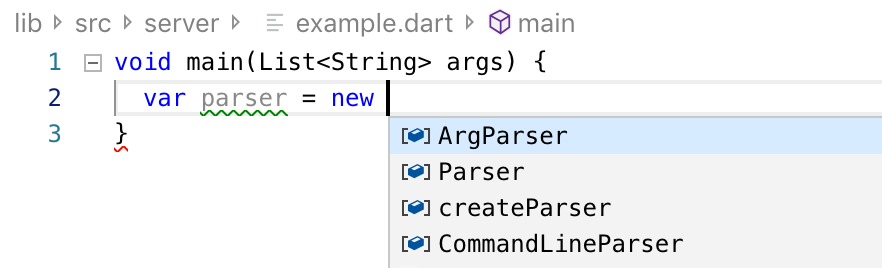
Figure 2: Completion suggestions after ML ranking, illustrating the improved ranking of suggestions after applying the model.
Training and Implementation Details
The model was trained on three distinct corpora of Dart code: an internal repository, open-source GitHub code, and submissions to the Flutter Create contest [flutter]. These datasets provide a diverse range of code styles and domain-specific concepts. The most frequent 100k tokens were selected for the output vocabulary of each corpus-specific RNN model.
Rare tokens were replaced with a special <unk> symbol. For training, each keyword, identifier, or literal was treated as a label for the previous 100 inputs (tokens or partial tokens, depending on the model variant). Duplicate examples were removed to mitigate the impact of code duplication [DBLP:journals/corr/abs-1812-06469]. The models were implemented using TensorFlow Lite, leveraging post-training quantization to reduce network size [DBLP:journals/corr/abs-1712-05877].
Evaluation and Results
The model's performance was evaluated using top-1 and top-5 accuracy metrics on held-out test data. The results demonstrate that the subtoken model outperforms the token model, and accuracy increases with corpus size. The predictive ability of static analysis alone was measured on the internal corpus for baseline comparison, highlighting the significant improvement achieved through language modeling.
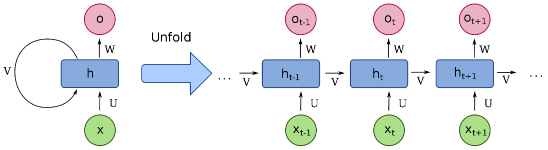
Figure 3: An unfolded recurrent neural network, depicting the basic RNN configuration with input sequence, hidden states, and output.
The authors also measured prediction latency, a critical factor for IDE integration. Before quantization, the average request time was 179ms. After quantization, it was reduced to 109ms, with 75.33% of requests completing in under 110ms. These results suggest that the model size is near the upper limit for maintaining a responsive user experience.
The secondary network for repetition detection achieved 0.9051 precision and 0.9071 recall on test data. This component is crucial for predicting OOV tokens, which are frequently repetitions of tokens within the input sequence.
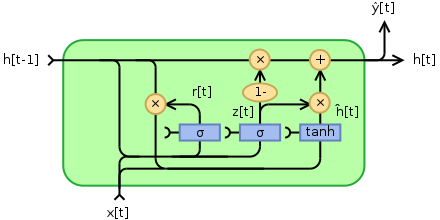
Figure 4: Gated recurrent unit, visualizing the internal structure of a GRU cell with input, previous hidden state, reset gate, update gate, and recurrent activation.
Comparison to Prior Work
The proposed model achieves state-of-the-art accuracy in source code modeling, exceeding the performance of previous approaches on dynamically typed languages [DBLP:journals/corr/BhoopchandRBR16, DBLP:journals/corr/abs-1711-09573]. However, the authors note that direct comparison is challenging due to variations in corpora, token types, and evaluation methodologies across different studies.
Conclusion
The paper presents a practical and effective approach for integrating LMs into code completion systems within modern IDEs. By combining static analysis, a hybrid neural network architecture, and local repetition detection, the model achieves high accuracy while meeting the strict constraints of interactive developer tools. The results demonstrate the potential of this approach to improve the code completion experience and enhance developer productivity. Future work could explore incorporating type and program context information as training signals and investigating smaller output vocabularies of word pieces to generate identifier names not seen during training.