- The paper introduces recurrent neural networks and explains how backpropagation through time (BPTT) enables effective sequence learning.
- The paper shows that LSTM and GRU architectures mitigate vanishing gradients, ensuring robust training over extended sequences.
- The paper examines advanced models like bidirectional RNNs, encoder-decoder frameworks, and attention mechanisms to improve sequence transduction.
An Academic Overview of "Recurrent Neural Networks (RNNs): A gentle Introduction and Overview"
Recurrent Neural Networks: An Introduction
Recurrent Neural Networks (RNNs) are a class of neural network architectures with widespread applications in sequence modeling, including tasks such as language modeling, speech recognition, and video tagging. Unlike Feedforward Neural Networks (FNNs), RNNs incorporate cycles that allow information to persist across time steps, enabling them to process sequences and retain historical information. This intramodal recursive nature is illustrated in the high-level schematic representation of RNNs and FNNs (Figure 1).
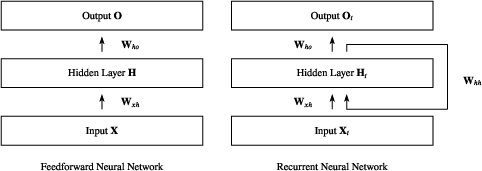
Figure 1: Visualization of differences between Feedforward NNs and Recurrent NNs—in RNNs, information is cycled back, enabling sequence modeling.
Backpropagation Through Time (BPTT)
The adaptation of backpropagation to RNNs, known as Backpropagation Through Time (BPTT), involves unfolding the RNN across time steps to effectively calculate gradients. This allows for adjusting weights through a defined loss function, which aggregates the discrepancies over time steps, controlled by a sequential feedback loop. The paper details the mathematical instantiation of gradient calculations for weight matrices involved in RNN operations and addresses numerical stability issues encountered during long sequences, such as vanishing or exploding gradients.
Addressing Challenges: LSTMs and GRUs
RNNs suffer from issues like vanishing gradients, impeding effective training over long sequences. The Long Short-Term Memory (LSTM) architecture remedies this by introducing gated mechanisms—input, forget, and output gates—to regulate information flow, thereby maintaining gradient magnitude across extended sequences. The formal equations governing LSTM operations include gate activations, memory cell updates, and hidden state computations. Complementary to LSTMs, Gated Recurrent Units (GRUs) offer a simplified architecture, merging certain gates while achieving comparable performance.
Advanced Architectures: Bidirectional RNNs and Deep RNNs
Enhancements to the RNN architecture include Bidirectional RNNs (BRNNs), which utilize separate layers processing sequences in forward and reverse temporal order, thereby encapsulating contextual information from both directions (Figure 2). Deep RNN architectures further extend capabilities by stacking multiple RNN layers, enabling higher-level abstract feature learning over sequences.
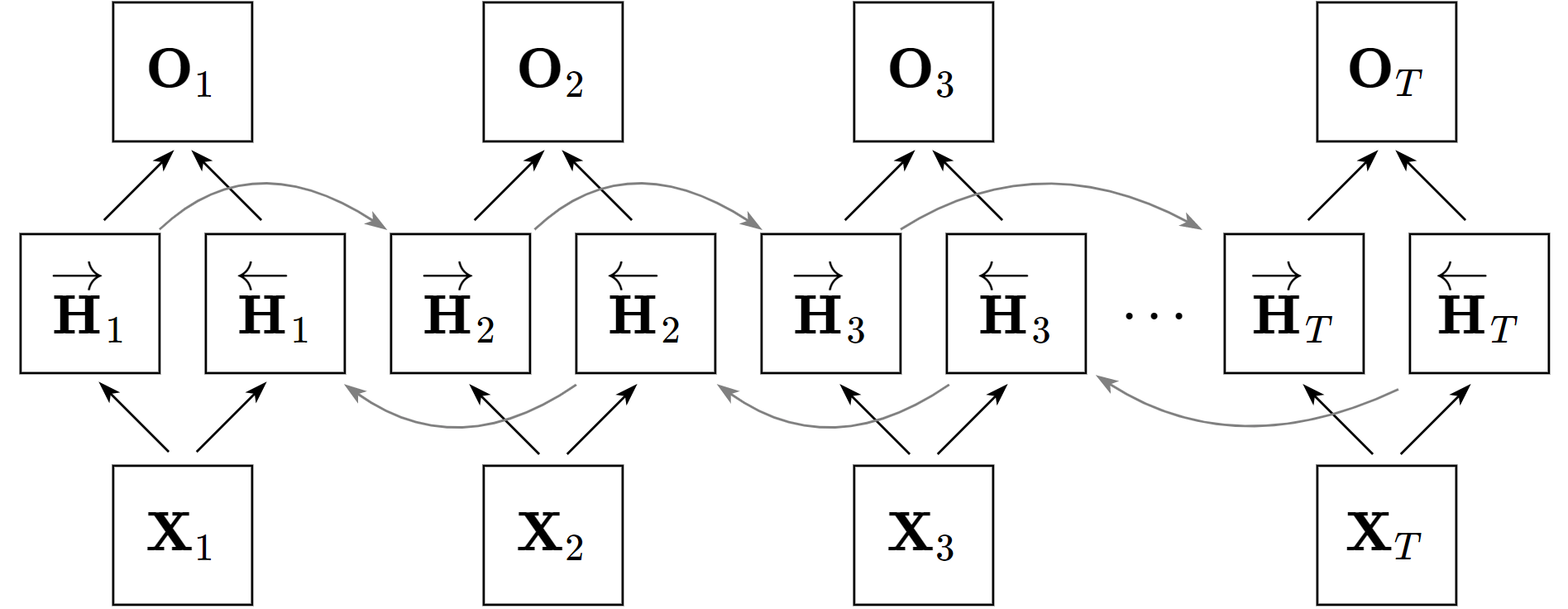
Figure 2: Architecture of a bidirectional recurrent neural network, which processes input sequences in both forward and backward directions.
Encoder-Decoder Models and Seq2Seq
The Encoder-Decoder paradigm, foundational to sequence transduction models, leverages RNNs for mapping input sequences to output sequences of potentially varying lengths. Sequence to Sequence (seq2seq) models enhance translation tasks by constructing an intermediate fixed-length vector state as input for subsequent decoding. However, traditional seq2seq models face bottlenecks with extended sequences due to information compression in the encoder's final state, resolved by integrating attention mechanisms.
Attention mechanisms advance seq2seq models by dynamically focusing on relevant source input segments during decoding, effectively bypassing the encoder bottleneck. This is further elevated in Transformer architectures, which dispense with recurrence altogether, using self-attention and multi-head attention to parallelize encoding-decoding processes, achieving state-of-the-art performance in machine translation and various NLP tasks (Figure 3).

Figure 3: Encoder-Decoder Architecture Overview with an alternated attention mechanism.
Pointer Networks
Pointer Networks innovate on seq2seq and attention models by addressing discrete combinatorial optimization problems, where outputs are pointers to input positions. This adaptation expands the applicability of neural networks to solve computationally complex tasks like the Traveling Salesman Problem and other graph-centric challenges.
Conclusion
This paper encapsulates the diverse methodologies and issues central to RNN architectures and their evolution towards sophisticated hybrid models like LSTMs, GRUs, Bidirectional, Deep RNNs, and Transformers. While theoretical understanding provides groundwork, practical application considerations are essential for contextual deployment in industry and research landscapes. Continuous advancement in architectures ensures these models maintain relevance and efficacy in increasingly complex AI challenges.

