- The paper introduces an adversarial framework combining a temporal generator and a motion discriminator to accurately predict 3D human pose and shape.
- VIBE leverages GRU-based networks and self-attention mechanisms to integrate temporal data for realistic and smooth motion estimation.
- Experimental results on datasets like 3DPW and MPI-INF-3DHP demonstrate significant improvements in accuracy and temporal consistency over existing methods.
VIBE: Video Inference for Human Body Pose and Shape Estimation
Introduction
The paper "VIBE: Video Inference for Human Body Pose and Shape Estimation" introduces a novel approach to estimating 3D human poses and shapes from video sequences. Traditional single-image methods often produce unnatural motion sequences due to the lack of ground-truth 3D motion data. The paper proposes VIBE, which leverages an existing large-scale motion capture dataset, AMASS, in conjunction with adversarial learning techniques to improve the realism and accuracy of human motion estimations from monocular videos.
Methodology
VIBE employs an adversarial learning framework that discriminates between real human motions and those generated by temporal pose and shape networks. The architecture of VIBE consists of two key components: a temporal generator and a motion discriminator. The temporal generator predicts pose and shape parameters using a sequence of frames, guided by a CNN pretrained on single-image pose estimation. This process is enhanced by a motion discriminator that exploits a dataset of real human motions to refine the network’s outputs.

Figure 1: VIBE architecture. VIBE estimates SMPL body model parameters for each frame in a video sequence using a temporal generation network, which is trained together with a motion discriminator. The discriminator has access to a large corpus of human motions in SMPL format.
The temporal generator is based on GRU layers, facilitating the integration of information from previous frames to resolve ambiguities in the current frame. A key innovation is the use of a motion discriminator that evaluates the validity of motion sequences. The discriminator is equipped with a self-attention mechanism that emphasizes significant frames, enhancing the model's ability to learn realistic temporal dependencies.
Experiments and Results
VIBE is benchmarked against state-of-the-art methods on several datasets, including 3DPW and MPI-INF-3DHP. The results demonstrate that VIBE outperforms existing frame-based and temporal methods on in-the-wild datasets, achieving significant improvements in MPJPE, PVE, and other metrics. The inclusion of an attention mechanism in the motion discriminator is shown to offer advantages over static pooling methods.
A notable finding is that while the method achieves competitive smoothness (as measured by acceleration error), it does so without sacrificing accuracy in the pose estimations. This balance is achieved by the adversarial setup, which encourages the generation of temporally coherent sequences.
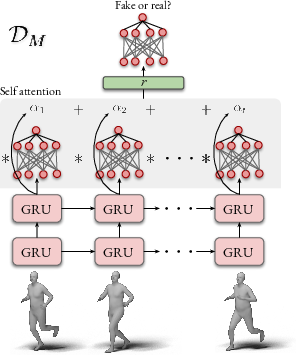
Figure 2: Motion discriminator architecture D consists of GRU layers followed by a self attention layer. D outputs a real/fake probability for each input sequence.
Implications and Future Work
The implications of VIBE are substantial for video-based human motion estimation. By integrating temporal information and adversarial learning, VIBE significantly improves the fidelity and realism of 3D pose estimations from videos. This advancement has ramifications for various applications, including animation, virtual reality, and behavioral analysis.
Future work could explore integrating dense motion cues, utilizing optical flow, and extending the model to handle multi-person scenarios. Additionally, incorporating transformer-based models may further enhance the ability to capture complex temporal dependencies.
Conclusion
VIBE marks a significant step forward in video-based 3D human pose estimation by leveraging adversarial learning and temporal information. This framework not only advances the current capabilities of motion capture from video but also provides a robust platform for further exploration into more sophisticated models of human motion dynamics. The release of code and pretrained models supports transparency and fosters further research in this domain.

Figure 3: Qualitative results of VIBE on challenging in-the-wild sequences. For each video, the top row shows some cropped images, the middle rows show the predicted body mesh from the camera view, and the bottom row shows the predicted mesh from an alternate view point.