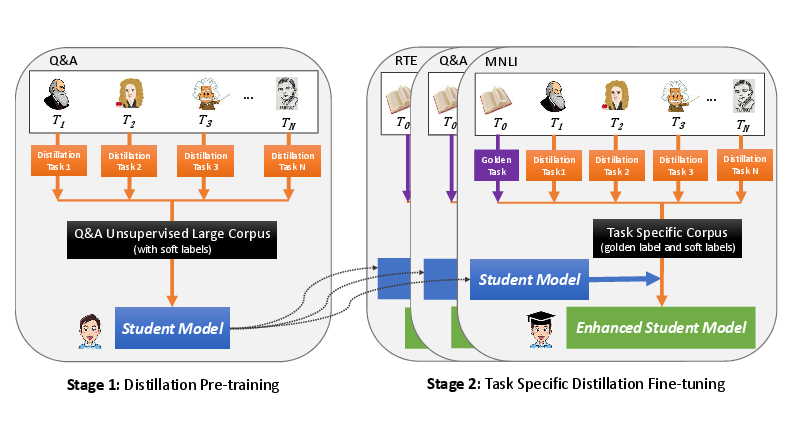
- The paper presents a two-stage multi-teacher knowledge distillation framework that first pre-trains and then fine-tunes a student model for web question answering.
- It leverages large-scale unlabeled data and multiple teacher models to transfer robust representations, achieving comparable performance with fewer parameters.
- Experimental results show notable improvements in accuracy, inference speed, and memory efficiency compared to traditional distillation approaches.
Model Compression with Two-stage Multi-teacher Knowledge Distillation for Web Question Answering System
Introduction
The paper focuses on enhancing the efficiency of deploying large pre-trained models like BERT and GPT in real-world question answering (QA) systems, which is challenged by their considerable parameter sizes and slow inference speeds. It introduces the Two-stage Multi-teacher Knowledge Distillation (TMKD) approach aimed at creating a smaller, faster student model that maintains performance comparable to the original teacher models.
Two-stage Distillation Framework
Stage 1: Distillation Pre-training
The TMKD approach begins with a pre-training phase using a novel Q&A distillation task, leveraging large-scale unlabeled datasets from commercial web search engines. This stage uses multiple teacher models to produce pseudo supervision for the student model, thereby enabling the student to learn robust representations before task-specific fine-tuning.
Stage 2: Task-specific Fine-tuning
In this phase, the pre-trained student model is fine-tuned using labeled data specific to downstream tasks, such as Web Q&A, MNLI, SNLI. Multi-teacher knowledge distillation is employed, where the student model learns from multiple teacher models simultaneously to mitigate overfitting bias and enhance generalization.
- Approach: Integrate ground truth and soft scores from multiple teacher models, enabling "early calibration" of biases and achieving better student model accuracy.
Architecture and Implementation Details
Model Architecture
TMKD utilizes a BERT-based architecture with modifications for multi-teacher input:
- Encoder Layer: Transforms input word pieces into embeddings, which are processed through concatenated question-passage pairs.
- Transformer Layer: Provides contextual embeddings using a bidirectional transformer analogous to BERT.
- Multi-header Layer: Simultaneously learns from ground truth and multiple soft label supervision, guiding the student model's learning process.
- Loss Function: Combines cross-entropy for ground truth labels and mean squared error for soft labels, governed by a weighted parameter α for balanced learning contributions.
Experimental Results
Empirical studies demonstrate significant improvements over baseline methods:
- Accuracy and Speed: TMKD models achieve accuracy on par with ensemble teacher models while drastically reducing the number of parameters and improving inference speed.
- Comparative Analysis: TMKD outperforms 1-o-1, 1-avg-o-1, and m-o-m models in multiple datasets, achieving a superior trade-off between accuracy, inference time, and memory usage.
Ablation Studies
Further exploration highlights the dual impact of the pre-training and fine-tuning stages, showcasing how each contributes to the overall effectiveness of TMKD. The studies confirm the complementary benefits of multi-teacher strategies, both in terms of pre-training and task-specific learning.
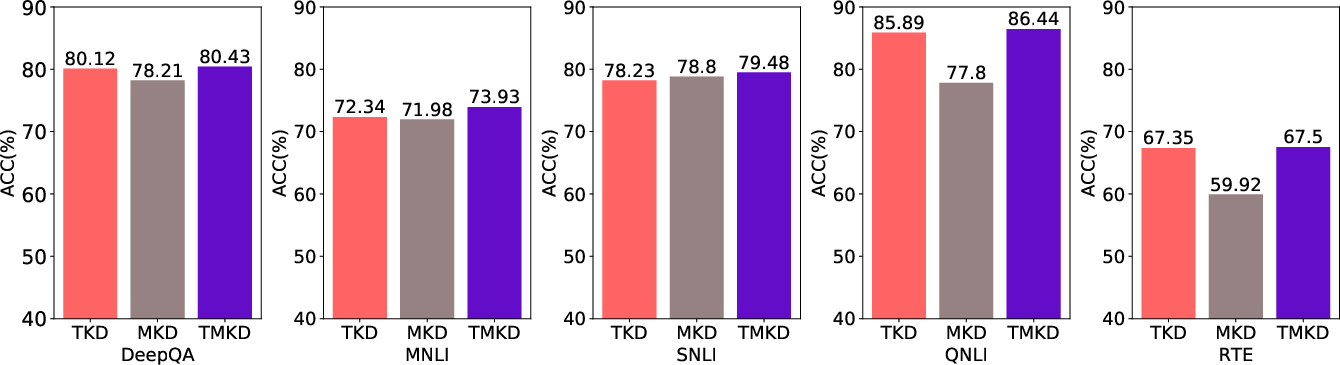
Figure 2: Performance comparison of TKD, MKD, and TMKD on different datasets.
Conclusion
The TMKD approach presents a significant advancement in deploying deep learning models efficiently in practical applications, notably outperforming traditional distillation techniques. By utilizing a comprehensive strategy of large-scale pre-training followed by task-specific distillation, TMKD achieves impressive performance enhancements while optimizing for real-world use cases.
Future directions include extending TMKD to various NLU tasks beyond Q&A and optimizing the selection of teacher models to further enhance student model performance.