- The paper introduces a novel kWTA mechanism for inducing sparse representations in RL, reducing catastrophic interference in control tasks.
- It demonstrates improved convergence and stability by leveraging lateral inhibition, as evidenced in tasks like Puddle-world and Mountain-car.
- The approach provides a robust framework, suggesting future integration with deep and hierarchical reinforcement learning systems.
Learning Sparse Representations in Reinforcement Learning
Introduction
The paper "Learning sparse representations in reinforcement learning" addresses a significant challenge in the field of Reinforcement Learning (RL), specifically the inefficacy of traditional Temporal Difference (TD) learning paired with neural networks in tackling some simple control tasks. This work posits that the presence of lateral inhibition in neural architectures is crucial for forming sparse distributed representations, which mitigate issues such as catastrophic interference while enhancing generalization capabilities.
Reinforcement Learning and Sparse Representations
The central focus of reinforcement learning is to enable an agent to maximize cumulative rewards through sequential decision-making in an interactive environment. Traditional TD learning techniques have demonstrated efficacy in various control tasks; however, their scalability is hindered by the burgeoning state spaces—commonly referred to as the curse of dimensionality.
Sparse representations, characterized by lateral inhibition, are posited to enable the successful learning of value functions by creating distinct patterns of activity that avoid overlap in function approximations. This paper draws theoretical connections between this biological feature and its algorithmic counterpart within a neural network context, employing the k-Winners-Take-All (kWTA) mechanism.
Methods for Incorporating Sparse Representations
Lateral Inhibition
Lateral inhibition serves to create competition among neurons, ensuring that only a minority exhibit high levels of activation at any one time. This is vital for generating sparse representations. Sparse representations benefit from limited overlap, enhancing pattern separation, and error minimization during RL. The kWTA mechanism efficiently implements lateral inhibition by updating only the top k neurons' activations.
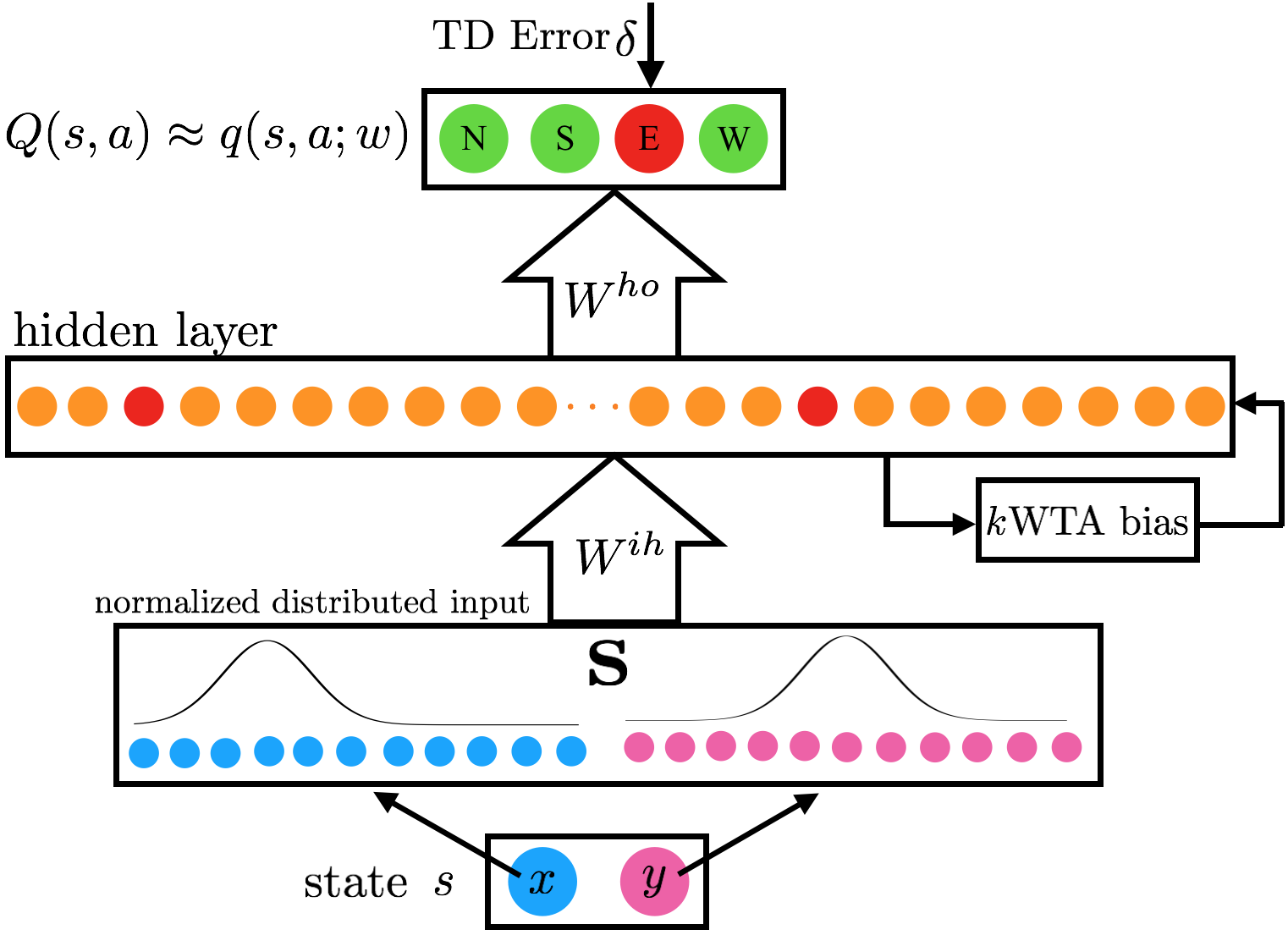
Figure 1: The kWTA neural network architecture: a backpropagation network with a single layer equipped with the k-Winner-Take-All mechanism.
k-Winners-Take-All (kWTA) Mechanism
Implemented in a neural network with one hidden layer, the kWTA mechanism restricts activation to a set fraction of units, ensuring the network learns sparse conjunctive codes. A typical configuration allows for around 10% of the hidden units to be active—balancing sparsity with the need for overlap necessary for generalization.
Experiments and Results
The authors evaluate this sparse representation learning approach using traditional control tasks: Puddle-world, Mountain-car, and Acrobot. The performance of the proposed kWTA network is compared against conventional neural architectures.
Puddle-World Task
The Puddle-world task revealed that the kWTA network forms superior value function approximations than standard architectures. The avoidance of interference in sparse networks resulted in more reliable policy learning and stable convergence of estimated value functions.
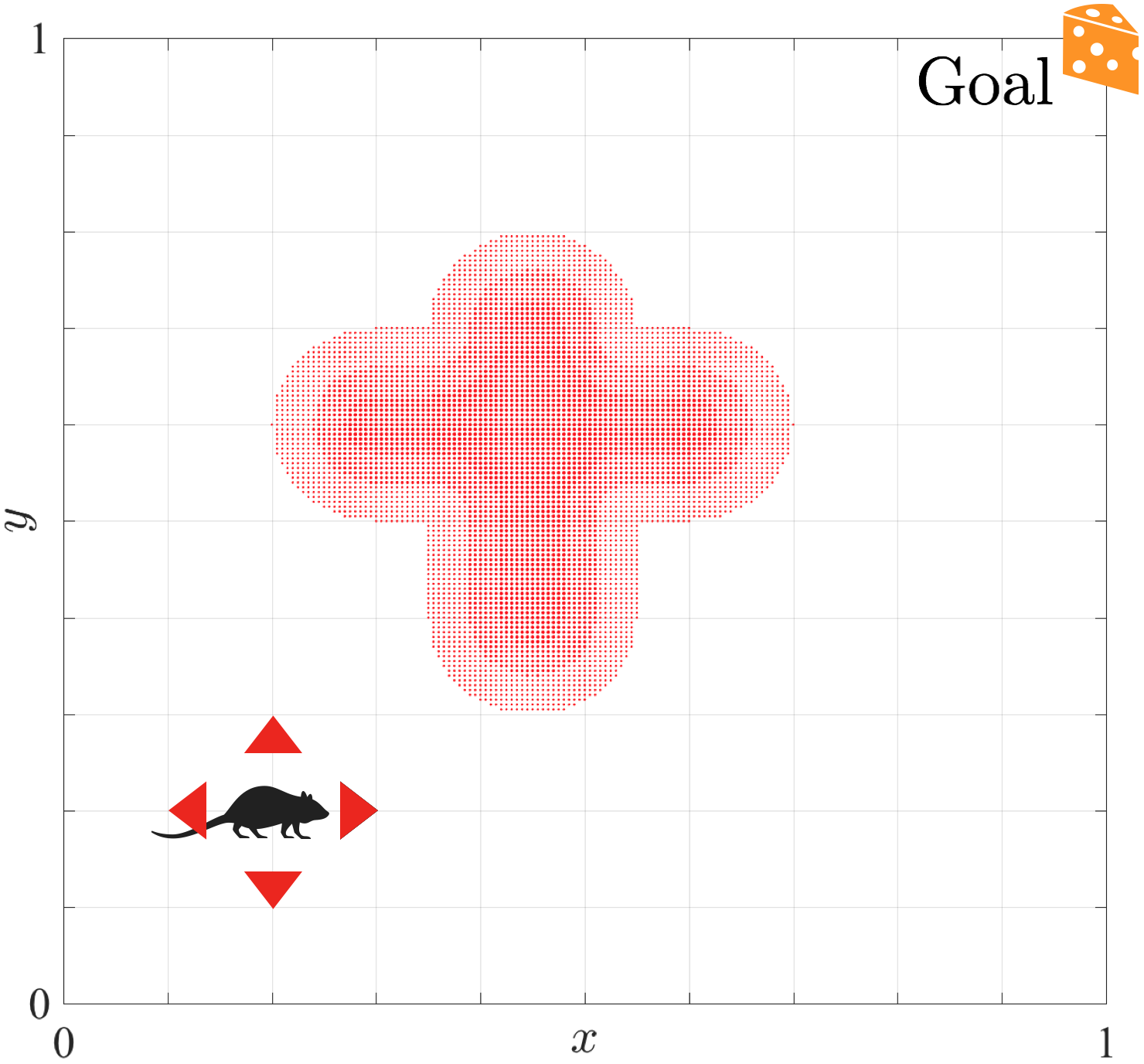
Figure 2: The agent in puddle-world task attempts to reach the goal location (fixed in the Northeast corner) in the least time steps by avoiding the puddle.
Mountain-Car Task
In the Mountain-car task, the kWTA network demonstrated faster convergence and better navigation strategy compared to regular networks. Sparse representation helped in capturing the task's intricate dynamics, reducing time steps needed to reach the goal.
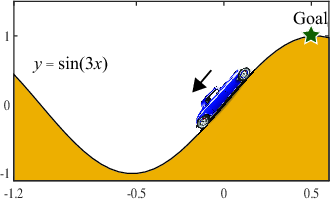
Figure 3: The goal is to drive an underpowered car up a steep hill. The agent received -1 reward for each time step until it reached the goal, at which point it received 0 reward.
Acrobot Task
For the Acrobot task, which is inherently more complex, the kWTA network alone effectively learned the control policy, while other network architectures struggled. This indicates the robustness of the sparse strategy in coping with control challenges where function approximators traditionally fail.
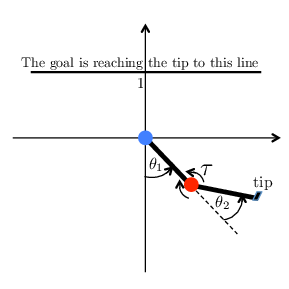
Figure 4: The goal is to swing the tip ("feet") above the horizontal by the length of the lower "leg" link. The agent receives -1 reward until it reaches the goal, at which point it receives 0 reward.
Discussion and Future Work
The findings provide substantial evidence that sparse representations, facilitated by lateral inhibition mechanisms like kWTA, significantly enhance the learning capabilities of RL algorithms. This characteristic is particularly useful in environments with expansive state spaces, where function approximators otherwise face catastrophic interference.
Future work may extend the applicability of sparse learning strategies through Hierarchical Reinforcement Learning (HRL) frameworks or integration with deep reinforcement learning networks. By incorporating kWTA mechanisms, these systems can potentially learn efficiently over broad and complex environments, paving the way for applications in both synthetic and real-world tasks.
Conclusion
This paper contributes to the discourse on reinforcement learning by demonstrating that biologically inspired mechanisms such as lateral inhibition can substantially enhance representation learning. The incorporation of kWTA in neural networks for sparse conjunctive codes shows promising improvements in solving previously challenging control tasks, setting a strong precedent for further exploration of biologically plausible learning in AI systems.