- The paper demonstrates that attention weights often fail to reliably indicate crucial input components in complex neural architectures.
- It employs an erasure-based methodology and compares alternative schemes, including gradient-based rankings, to evaluate interpretability.
- The findings highlight the need for more robust interpretation techniques to better understand decision-making in NLP models.
Is Attention Interpretable?
The paper "Is Attention Interpretable?" investigates the use of attention mechanisms in neural network models, particularly in the context of text classification tasks, challenging the commonly held assumption that attention weights provide a reliable means of interpreting model decisions.
Introduction
Attention mechanisms have gained traction in NLP for improved performance across various tasks, ranging from machine translation to language modeling. They function by calculating nonnegative weights over input components, producing a weighted summation that aids in decision-making. The assumption is that attention weights can elucidate the importance of specific components to model outputs. However, this paper argues that attention weights are not necessarily faithful indicators of importance, particularly in complex neural architectures.
Methods
The authors evaluate the interpretability of attention by analyzing text classification models with varying architectures. The importance of input components is assessed by systematically zeroing out attention weights and observing the changes in model predictions. This approach is inspired by the concept of erasure-based analysis where intermediate representations are nullified to test their impact on the end decision.
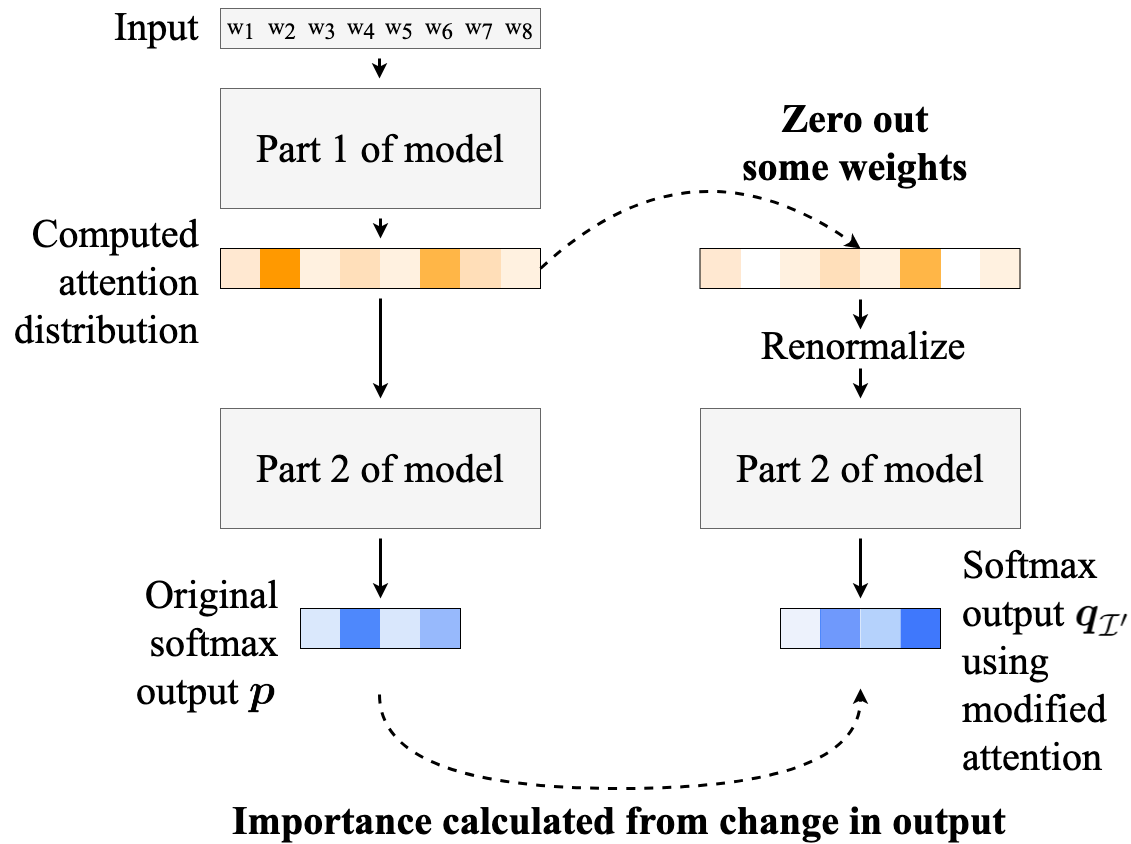
Figure 1: Our method for calculating the importance of representations corresponding to zeroed-out attention weights, in a hypothetical setting with four output classes.
Experimental Setup
The study involves text classification models trained on datasets such as Yahoo Answers and Yelp reviews, utilizing hierarchical attention networks (HAN) and flat attention networks (FLAN), among others. Attention weights are tested against alternative importance ranking schemes: random, gradient-based, and gradient-attention-product based rankings. This diversification allows the evaluation of attention's relative efficacy in signaling input component importance.
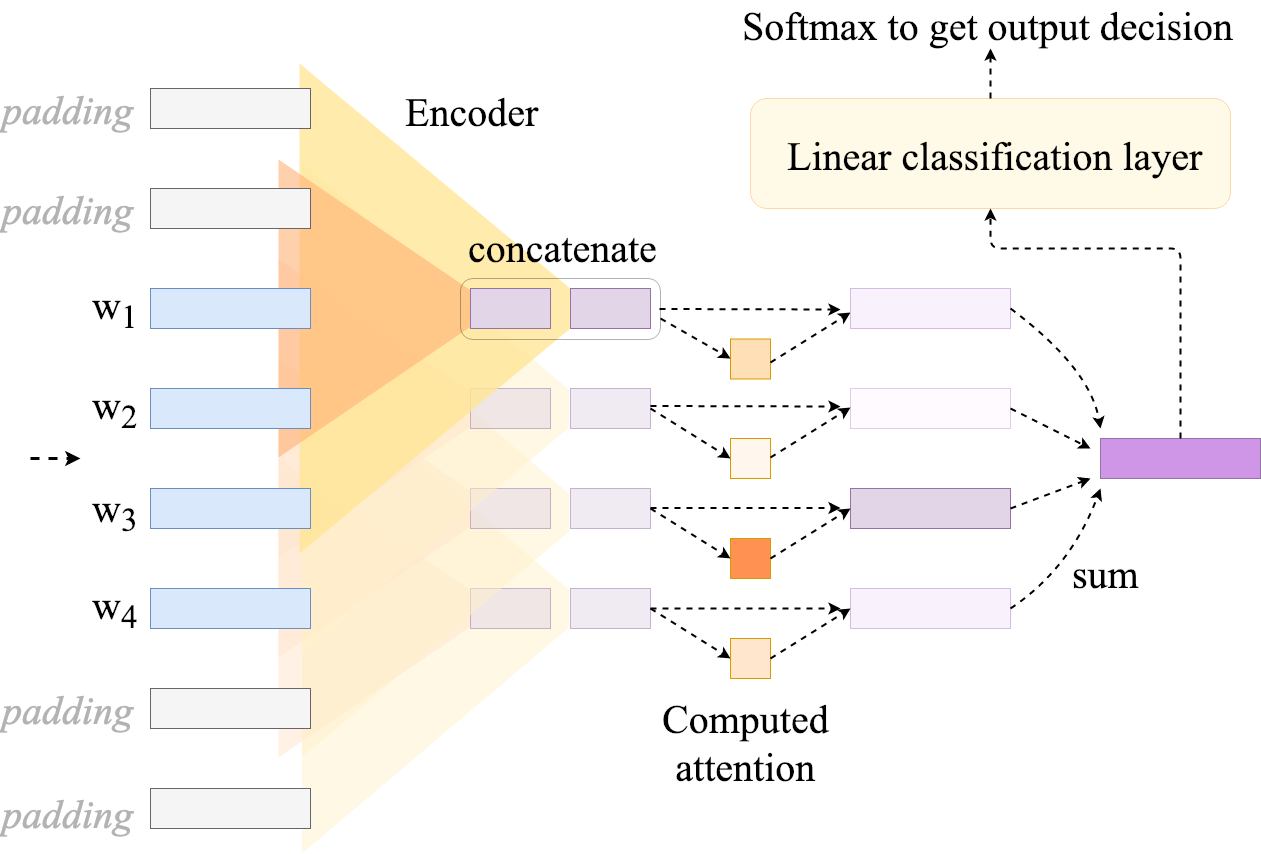
Figure 2: Flat attention network (FLAN) demonstrating a convolutional encoder. Each contextualized word representation is the concatenation of two sizes of convolutions: one applied over the input representation and its two neighbors to either side, and the other applied over the input representation and its single neighbor to either side.
Results
The results show that while attention weights often correlate with importance, they frequently fail to pinpoint the minimal subsets of input components necessary for decision flips, indicating a lack of reliability in explaining model decisions. Gradient-based rankings regularly identified smaller sets necessary to flip decisions, suggesting that attention weights alone may not capture component importance accurately in complex text inputs. Furthermore, decision flips often occur after a large number of components are removed, raising transparency concerns.
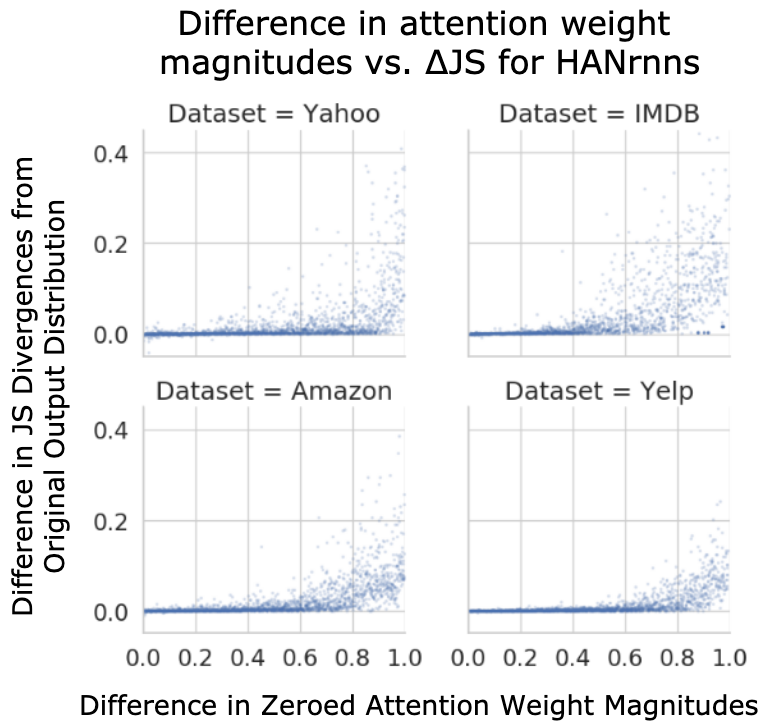
Figure 3: Difference in attention weight magnitudes versus $\Delta\mathrm{JS$ for all datasets and architectures.
Discussion
The findings imply that attention mechanisms' interpretability is highly contextual and may depend on factors such as the scope of input contextualization. Models using bidirectional RNNs tended to diffuse signal across input components, complicating clear interpretations based solely on attention weights. Moreover, alternative ranking schemes outperform attention-based schemes in identifying important components, suggesting that improvements or alternative methods are necessary.
Implications and Future Directions
The study underscores the need for caution when using attention weights as a proxy for interpretability in neural models. It encourages exploration of alternative explanation methods, such as influence functions or feature-aligned models. Future research should focus on expanding interpretability tests to tasks with larger output spaces and exploring the role of contextualization and encoder design in shaping attention's interpretive capacity.
Conclusion
Attention weights are not reliable indicators of model decision importance across all architectures or tasks. While they can provide some insights, they often fail to pinpoint crucial components in complex settings. Attention is not an optimal method of ranking importance, highlighting the need for continued exploration of robust interpretability methods in AI.
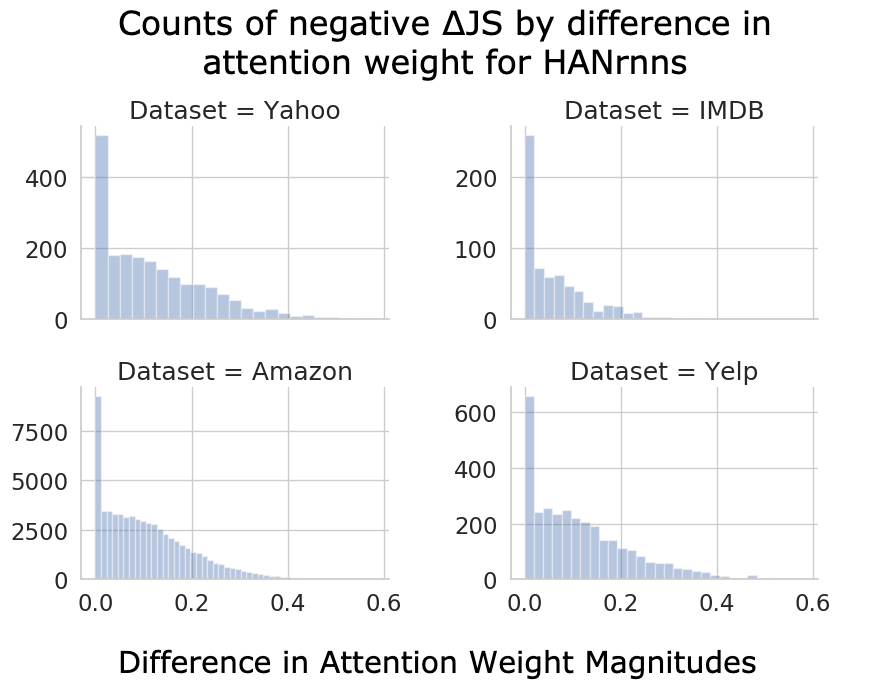
Figure 4: The distribution of fractions of items removed before first decision flips on three model architectures under different ranking schemes.