- The paper introduces DLRM, a deep learning framework that combines embeddings with MLPs to process sparse data and enhance recommendation accuracy.
- The model employs a sophisticated parallelism strategy by integrating model and data parallelism to handle large-scale, high-dimensional data efficiently.
- Experimental results on the Criteo dataset show DLRM outperforming the Deep and Cross Network benchmark in training and validation accuracies.
Deep Learning Recommendation Model for Personalization and Recommendation Systems
This essay provides a detailed examination of the "Deep Learning Recommendation Model for Personalization and Recommendation Systems" explored in the paper. The model, referred to as DLRM, is a state-of-the-art deep learning framework specifically tailored for tackling tasks related to personalization and recommendation in large-scale systems.
Model Design and Architecture
The architecture of DLRM is designed with consideration of both historical and modern approaches to recommendation systems. At its core, the model integrates embeddings for categorical features and a multilayer perceptron (MLP) for dense features. This hybrid approach allows DLRM to efficiently process sparse input data commonly found in recommendation systems.
Key Components
- Embeddings: Utilized for mapping categorical data into dense vectors, enabling the effective handling of high-cardinality features.
- Matrix Factorization: Provides the foundation for the interaction of features in latent space, crucial for capturing relationships between users and items.
- Factorization Machines (FM): Used to incorporate second-order interactions, enhancing the model's ability to handle sparse data without excessive computational overhead.
- Multilayer Perceptrons (MLP): Two MLPs are included—one for initial feature processing and another for final prediction refinement.
These components collectively facilitate the accurate prediction of recommendation outcomes.
Parallelism Strategy
DLRM's architecture necessitates sophisticated parallelism methods due to its complexity and size. The model implements a combination of model and data parallelism:
- Model Parallelism is applied to distribute embedding tables across devices to overcome memory limitations.
- Data Parallelism is employed for MLPs to maximize compute efficiency through concurrent processing across multiple devices.
The intricate balance of these strategies is non-trivial and requires customized implementations beyond standard library support in frameworks like PyTorch and Caffe2.
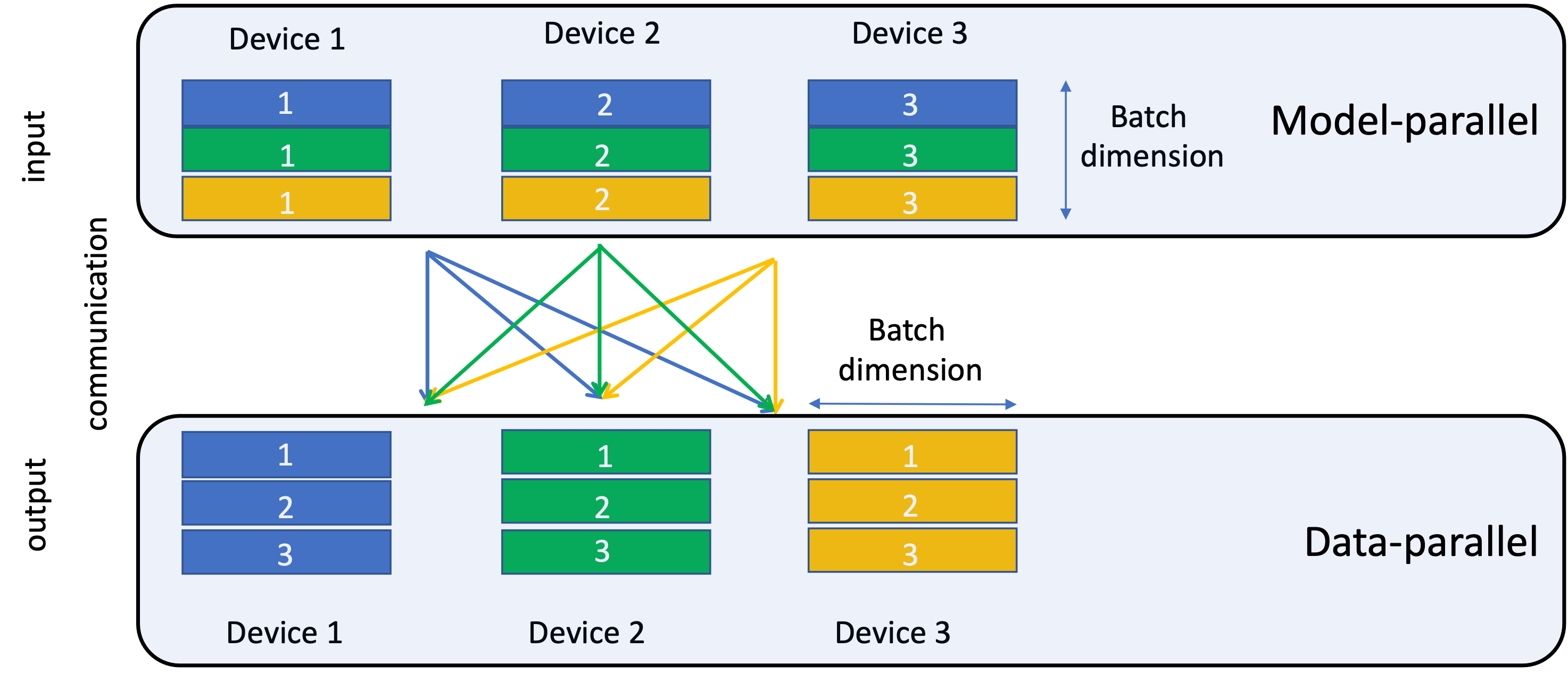
Figure 1: Butterfly shuffle for the all-to-all (personalized) communication.
Experimental Evaluation
DLRM's performance was evaluated using the Criteo Ad Kaggle data set, where it was benchmarked against the Deep and Cross Network (DCN). Results indicate that DLRM achieves slightly superior training and validation accuracies compared to DCN without extensive hyperparameter tuning.
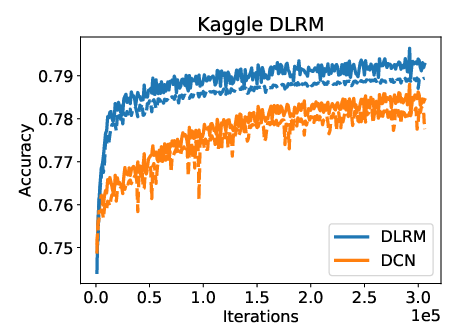
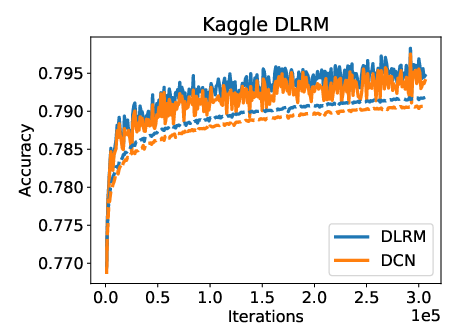
Figure 2: Comparison of training (solid) and validation (dashed) accuracies of DLRM and DCN.
The model was also profiled on a single device to analyze the computational demands of its components. Tests on both CPU and GPU architectures revealed insights into the time distribution across embedding lookups and fully connected layers. The GPU execution demonstrated substantial speedup, highlighting the model's scalability potential.
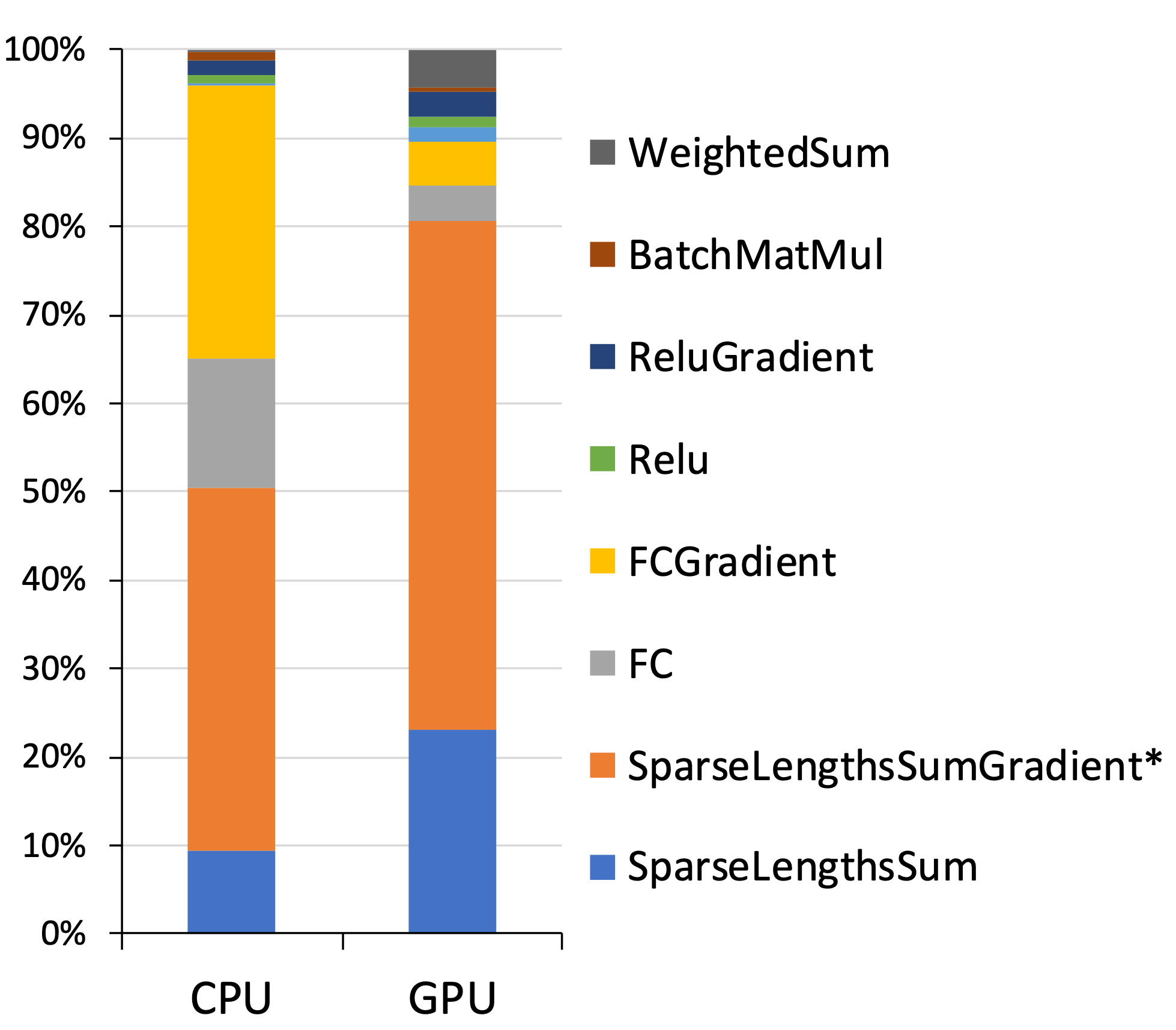
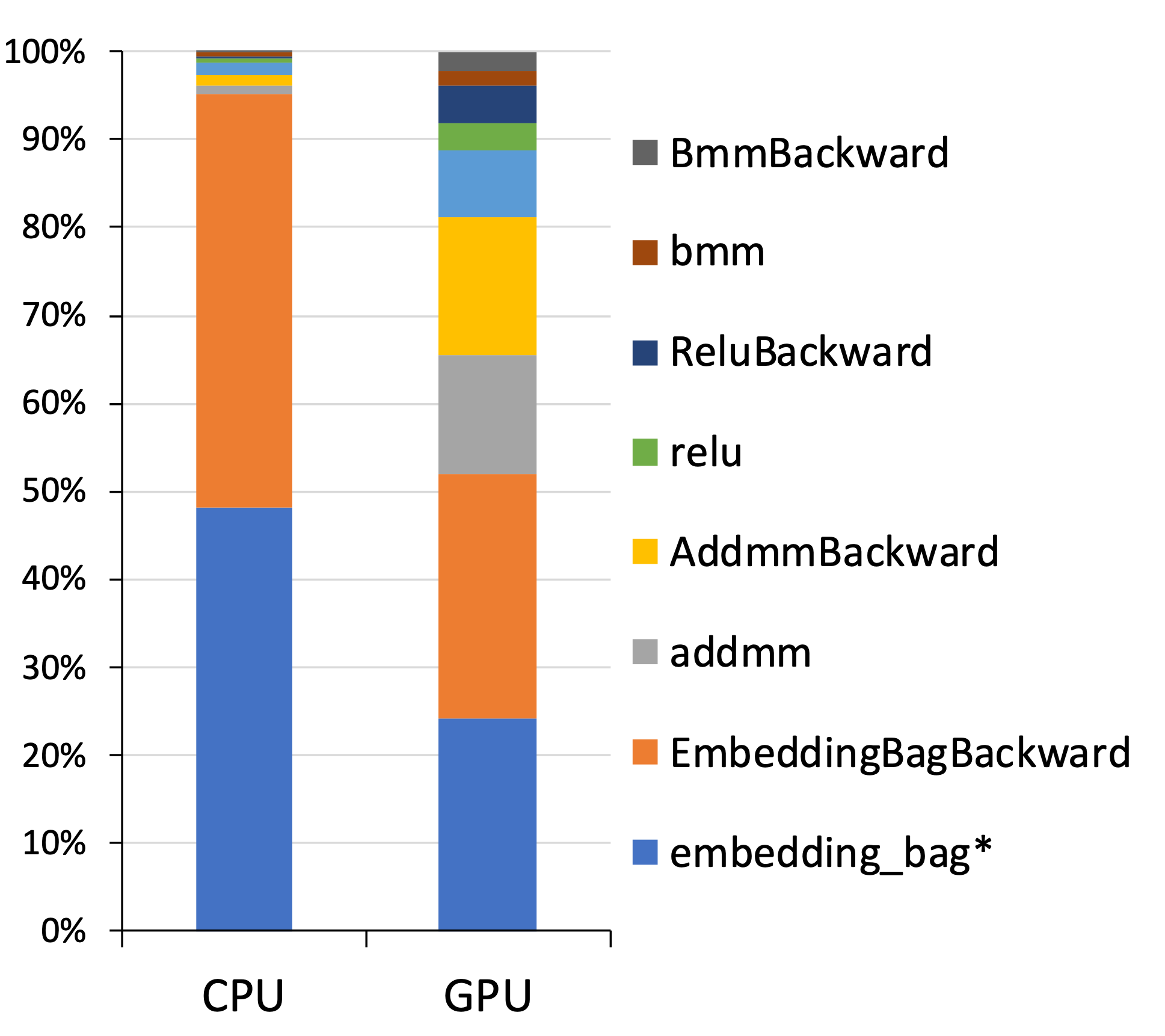
Figure 3: Profiling of a sample DLRM on a single socket/device.
Conclusion
The DLRM represents a significant contribution to the domain of recommendation systems by effectively merging historical methodologies with modern deep learning advancements. This comprehensive design facilitates efficient handling of high-dimensional categorical data, positioning DLRM as a valuable tool for ongoing research and practical applications in large-scale recommendation scenarios. Through its open-source implementation, the model stands poised to influence both academic research and industry practices, enabling further system improvements and benchmarking efforts in the future.