- The paper presents a novel encoding method that transforms point clouds into a structured pseudo-image with PointNet for enhanced efficiency.
- It leverages a backbone with 2D convolutions and an SSD detection head to achieve superior KITTI benchmark performance in both BEV and 3D detection.
- The approach delivers real-time object detection with improved accuracy and speed, underscoring its potential for autonomous navigation applications.
PointPillars: Fast Encoders for Object Detection from Point Clouds
Introduction
The paper "PointPillars: Fast Encoders for Object Detection from Point Clouds" addresses a crucial aspect of autonomous vehicles (AVs) and other robotics applications: efficient and accurate object detection from lidar point clouds. The authors propose a novel encoding method, PointPillars, which leverages PointNet to transform point clouds into a structured format suitable for convolutional detection architectures and significantly improves both speed and performance in comparison to existing methods. The proposed system achieves impressive results on the KITTI benchmarks with notably faster inference times.
Network Architecture
The PointPillars architecture is composed of three primary components: the Pillar Feature Network, a Backbone, and an SSD Detection Head.
- Pillar Feature Network: This module partitions the input point cloud into vertical pillars and utilizes PointNet to extract high-dimensional features from each pillar. The transformation into a pseudo-image allows for the application of efficient 2D CNNs.
- Backbone: The backbone processes the pseudo-image through a series of top-down blocks followed by upsampling and feature concatenation, forming a high-level feature map. The design is similar to the backbone architecture found in VoxelNet but operates solely with 2D convolutions for enhanced efficiency.
- SSD Detection Head: Utilizing the SSD setup, the detection head predicts orientated 3D bounding boxes, providing end-to-end learning capability for the network.
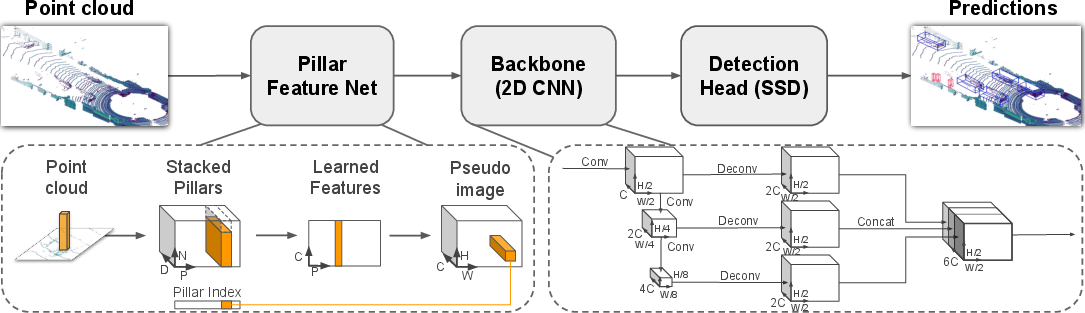
Figure 1: Network overview. The main components of the network are a Pillar Feature Network, Backbone, and SSD Detection Head.
Experimental Results
The proposed system was extensively evaluated on the KITTI dataset, achieving top-tier performance in bird's-eye view (BEV) and 3D detection tasks for various object classes. It was demonstrated that PointPillars outperforms existing lidar and multi-modal methods in terms of mean average precision (mAP) while operating at significantly increased speeds.
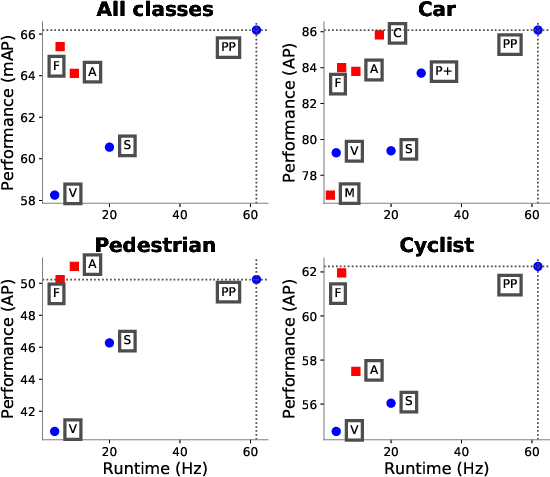
Figure 2: Bird's eye view performance vs speed for our proposed PointPillars method on the KITTI test set.
Qualitative analysis of the results highlighted that PointPillars maintains accurate object detection in complex urban environments with robust performance across a range of difficulties. The visualization showcases tight and correctly oriented bounding boxes despite the challenges posed by occlusion and varying object sizes.

Figure 3: Qualitative analysis of KITTI results illustrating 3D bounding boxes detected within lidar point clouds.
Comparative Analysis
An in-depth comparison reveals that PointPillars exceeds the performance of prior methods, achieving consistent improvements in classification accuracy and runtime. Encoders that rely on learned feature representations, such as PointPillars, demonstrate clear superiority over those with fixed encodings, especially when resolution parameters are enlarged.
Real-Time Inference and Optimization
The PointPillars architecture supports real-time inference with a notable improvement in speed, attributable to the efficient use of 2D convolutions and the optimized deployment of network components on the GPU using NVIDIA TensorRT. The paper describes a series of design choices and optimizations contributing to this performance boost.
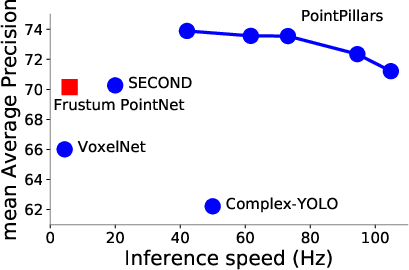
Figure 4: BEV detection performance (mAP) vs speed (Hz) on the KITTI val set.
Conclusion
PointPillars represents a significant advancement in 3D lidar-based object detection by coupling enhanced detection precision with unprecedented inference speed. The end-to-end learnability of the network, devoid of complex 3D convolutions, promises ease of adaptability and extensibility for various real-world autonomous navigation applications. Future work could explore extensions of this methodology to concurrent sensor modalities or integration within larger AV systems.
The paper and its findings establish a robust framework for furthering object detection capabilities in robotic systems, underscoring the merit of tailored, efficient network designs in high-dimensional, real-time settings.

