- The paper demonstrates that vanilla deep RL methods often generalize better than specialized algorithms across various training conditions.
- It proposes a benchmark comprising six environments, each with Deterministic, Random, and Extreme variants, to systematically evaluate generalization.
- Findings emphasize that incorporating environmental stochasticity during training significantly improves interpolation abilities in deep RL models.
Assessing Generalization in Deep Reinforcement Learning
Introduction
The paper "Assessing Generalization in Deep Reinforcement Learning" (1810.12282) addresses a significant limitation in deep reinforcement learning (RL): the ability of an agent to generalize beyond its training environment. While deep RL has showcased impressive results in various tasks, agents typically overfit to their training environments, thereby exhibiting poor performance in novel settings. The lack of a standardized benchmark for evaluating such generalization issues prompts this study, which provides a new framework and empirical insights into the capabilities of different RL algorithms to generalize.
Problem Statement and Methodology
The aim of the paper is to systematically evaluate the generalization of deep RL algorithms. The authors emphasize two generalization modes: in-distribution, where test environments resemble those seen during training, and out-of-distribution, where test environments diverge from the training data. They propose a diverse set of environments and a standard protocol designed to highlight strengths and weaknesses in existing algorithms' generalization abilities.
The framework consists of six environments, three classical control problems, and three MuJoCo-based tasks, each with three versions: Deterministic (D), Random (R), and Extreme (E). These variations help analyze how algorithms perform under different types of environmental perturbations. The study contrasts vanilla deep RL algorithms (A2C, PPO) with specialized schemes that claim to enhance generalization (EPOpt, RL2).
Experimentation and Results
The paper's experiments reveal several key findings. Interestingly, vanilla algorithms such as A2C and PPO often outperformed more complex strategies like EPOpt and RL2 across various metrics of generalization. Specifically, these simple algorithms showed notable interpolation abilities when agents were trained on diverse but related environmental configurations.
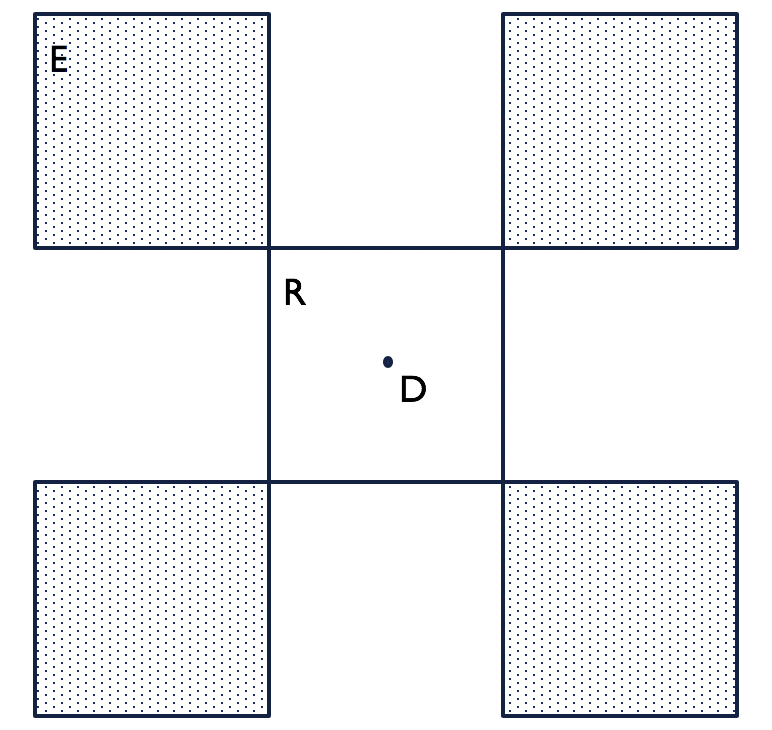
Figure 1: Schematic of the three versions of an environment.
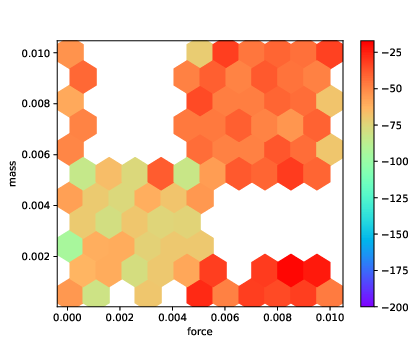
Figure 2: MountainCar: heatmap of the rewards achieved by A2C with the FF architecture on DR and DE. The axes are the two environment parameters varied in R and E.
In contrast, EPOpt demonstrated some degree of success in a subset of scenarios, particularly when combined with PPO and used in environments requiring continuous actions. RL2, however, struggled with training stability and data efficiency, often failing to deliver better generalization, which challenges prior claims about its adaptability.
Discussion
The results underscore an intriguing observation: the addition of environmental stochasticity during training can significantly enhance the baseline generalization capabilities of simple deep RL algorithms. This finding suggests that fundamental adjustments in training practices may offer substantial benefits over intricate algorithmic innovations.
The difficulty encountered by RL2 highlights important challenges in applying adaptive policies that rely heavily on recurrent architectures—issues that may benefit from exploring alternatives such as Temporal Convolution Networks for sequence modeling.
Practical Implications and Future Directions
This empirical assessment of generalization in deep RL proposes a reproducible benchmark that can serve as a catalyst for future research. The study's insights suggest that prioritizing stochastic training environments could be a practical approach to improving an agent's generalization capabilities. Additionally, it advocates for further investigation into model-based RL, which may provide enriched representations of system dynamics that bolster generalization.
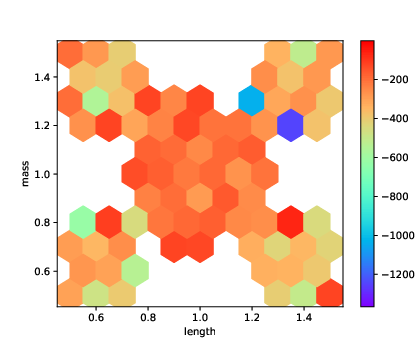
Figure 3: Pendulum: heatmap of the rewards achieved by A2C with the FF architecture on DR and DE. The axes are the two environment parameters varied in R and E.
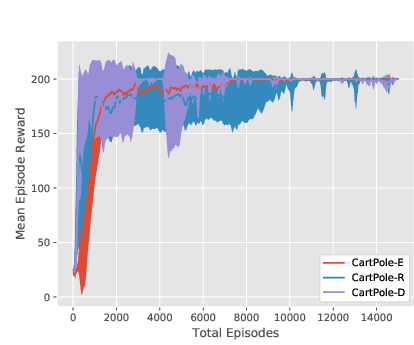
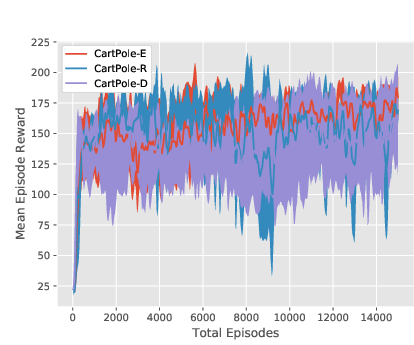
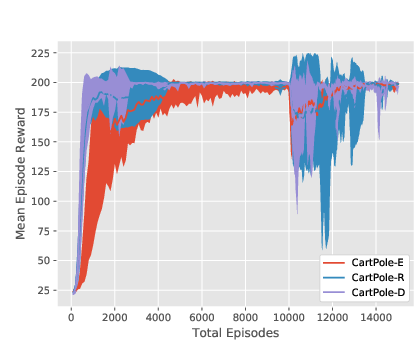
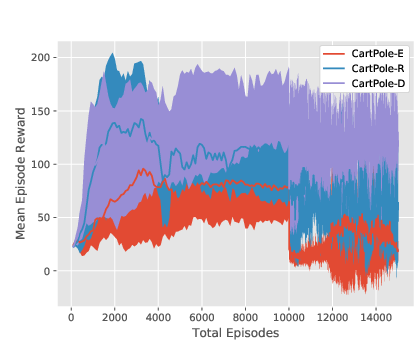
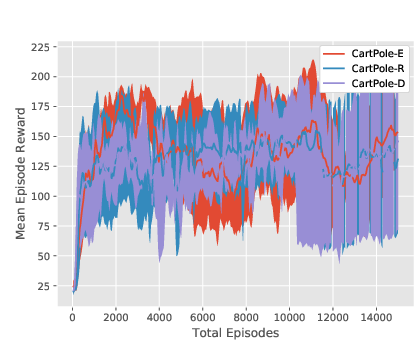
Figure 4: Training curves for the PPO-based algorithms on CartPole, all three environment versions. Note that the decrease in mean episode reward at 10000 episodes in the two EPOpt-PPO plots is due to the fact that it transitions from being computed using all generated episodes (epsilon=1) to only the 10\% with lowest reward (epsilon=0.1).
Conclusion
This study provides a significant contribution to the understanding of generalization in deep RL by demonstrating that "vanilla" approaches can often outperform specialized, complex algorithms in terms of generalization performance. It offers valuable insights into effective training methodologies and highlights new research avenues, emphasizing the importance of standardizing evaluation protocols to facilitate collective progress in the field.