- The paper presents a GPU-accelerated simulation framework that dramatically speeds up training for deep RL tasks using a single GPU and CPU core.
- The methodology leverages NVIDIA's Flex to simulate up to 750 agents with near-linear scalability, achieving about 60K frames per second and mean frame times below 0.02 ms.
- Experimental results demonstrate efficient scaling in both single and multi-GPU settings, enabling faster learning for complex locomotion and navigation tasks.
GPU-Accelerated Robotic Simulation for Distributed Reinforcement Learning
The paper "GPU-Accelerated Robotic Simulation for Distributed Reinforcement Learning" (1810.05762) proposes a novel approach to handling the simulation demands of Deep Reinforcement Learning (Deep RL) in continuous control tasks by leveraging GPU acceleration. Historically, RL environments have relied heavily on CPU resources, but this work introduces a method that utilizes the parallelism of GPUs to enhance the simulation and training speed of RL agents, particularly in locomotion tasks.
GPU-Accelerated Simulation Framework
The framework developed in this research uses NVIDIA's Flex, a GPU-based physics engine that facilitates the concurrent simulation of hundreds to thousands of robots. This GPU-accelerated simulation significantly reduces the time required to train agents on complex tasks compared to traditional CPU-based methods, which often require extensive compute resources.



Figure 1: GPU-Accelerated RL Simulation showcasing the ability to simulate complex tasks efficiently with minimal hardware resources.
The paper demonstrates the application of this framework to several tasks, including those based on well-known benchmarks like OpenAI's Gym and more complex variations requiring agents to recover from falls and navigate complex terrains. Using just a single GPU and CPU core, the researchers report achieving notable speed-ups: humanoid running tasks can be trained in under 20 minutes—a substantial improvement over previous methods that could take hours or required large CPU clusters.
Simulation Speed and Scalability
The scalability of the GPU-accelerated simulation is a focal point of this work. The researchers present data indicating that their method can handle an increasing number of concurrently simulated agents with minimal degradation in performance, ensuring that the simulations remain efficient.
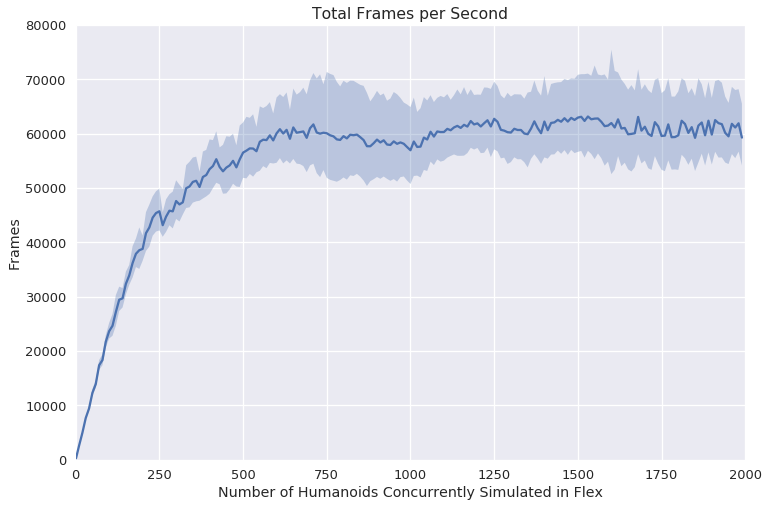
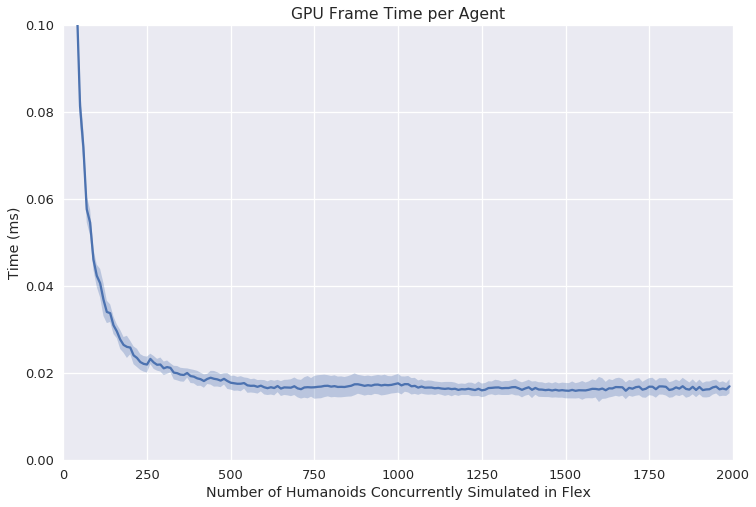
Figure 2: GPU Simulation Speed showing the near-linear scalability of simulation tasks up to 750 agents.
The paper reports that simulations attain a peak performance of around 60K frames per second for a task involving 750 humanoids, and the best mean frame time per agent is less than 0.02 ms. This efficiency contrasts sharply with CPU-based approaches, where timing often scales poorly as more agents are introduced due to increasing overheads.
Experimental Results
The experimental validation encompasses various settings, including single and multi-GPU configurations, to showcase the flexibility and robustness of the framework. The tasks chosen for evaluation include:
- Basic locomotion
- Complex terrain navigation
The researchers adopted Proximal Policy Optimization (PPO) as the learning algorithm, ensuring consistency in benchmarks while evaluating learning efficiency across different numbers of concurrent simulations.
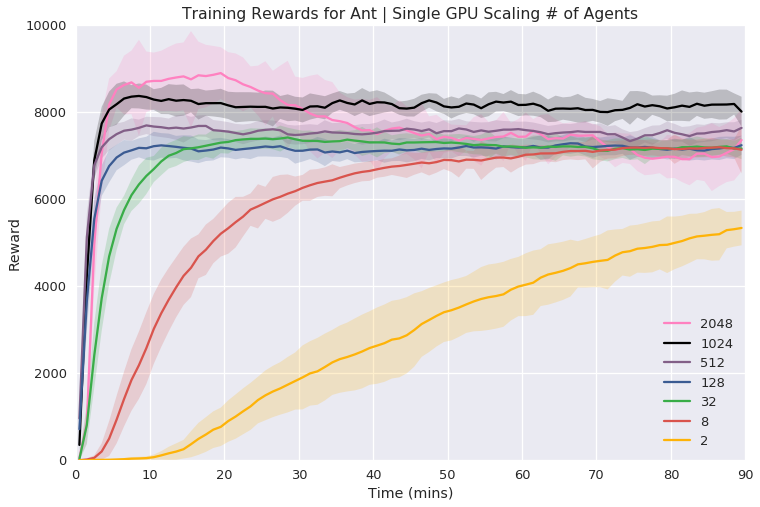
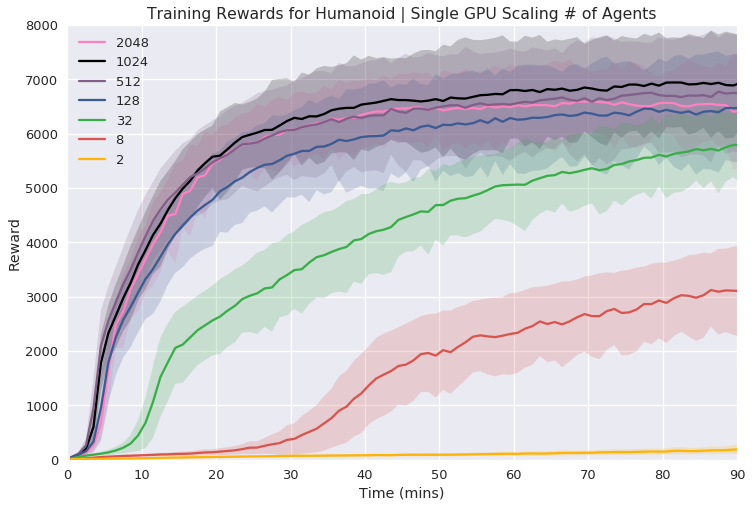
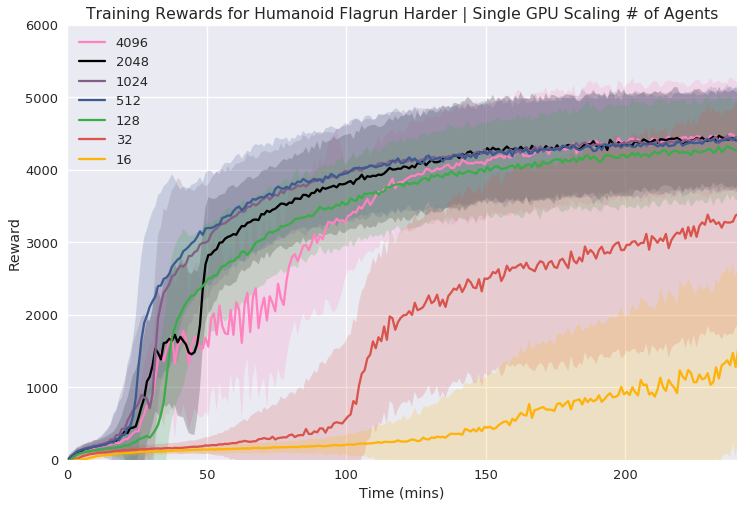
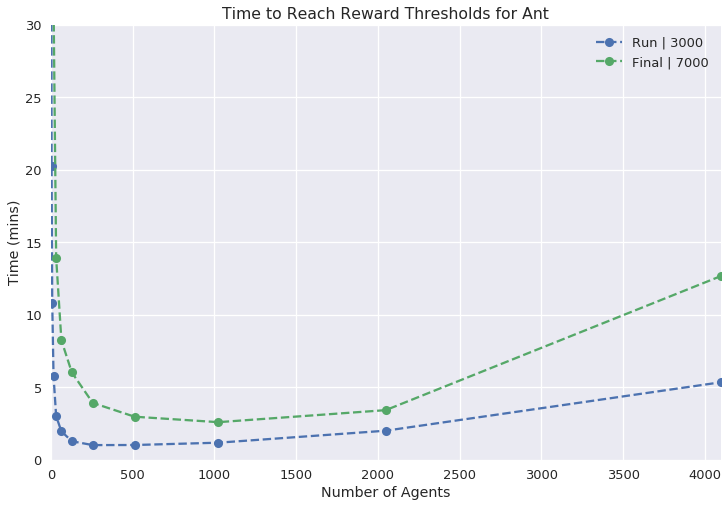
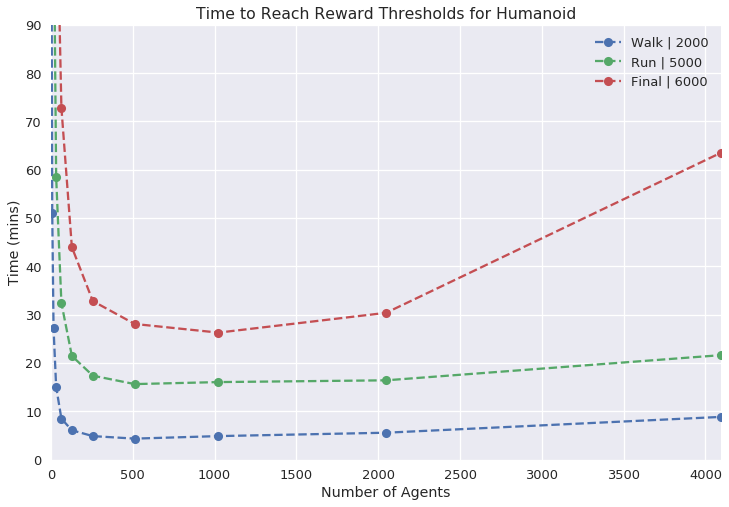
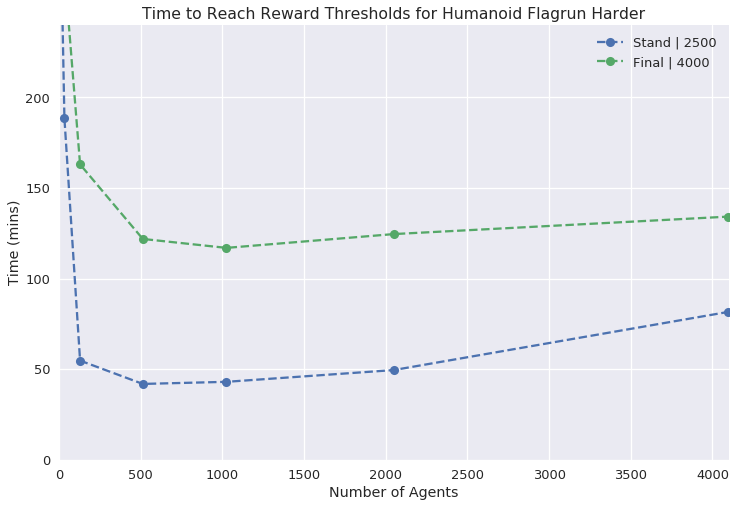
Figure 3: Single GPU Experiments illustrating the reward curves and necessary wall time for various tasks with increasing agent counts.
In single GPU settings, the researchers systematically varied the number of agents to find an optimal balance between simulation complexity and learning time, demonstrating efficient learning within a relatively short wall time.
Multi-GPU Scaling
The study extends the simulation framework to multi-GPU environments, further validating its scalability potential. The results suggest that the benefits of distributing simulations across multiple GPUs become apparent in more complex tasks, where traditional single-threaded simulations would be prohibitively slow.
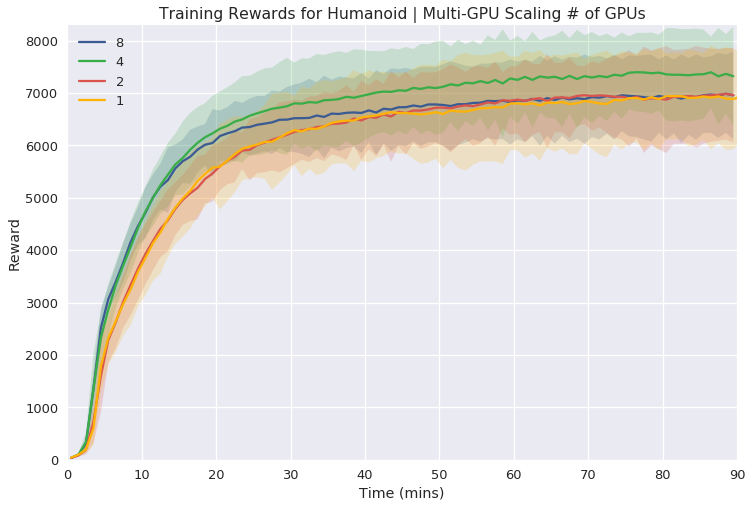
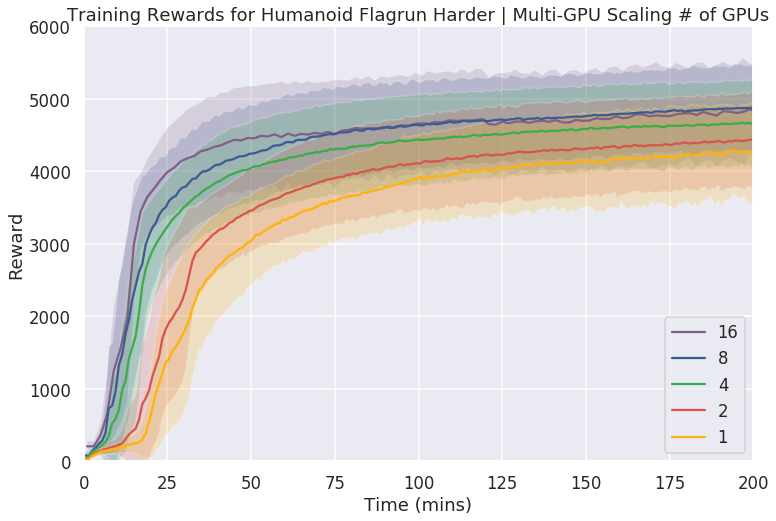
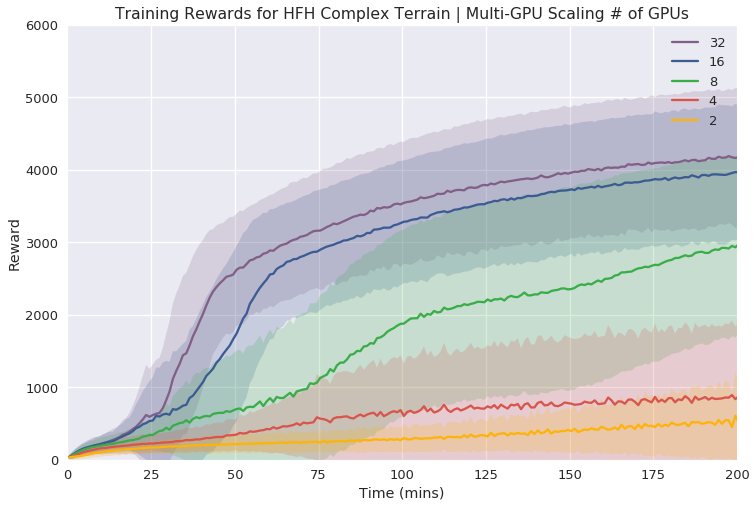
Figure 4: Multi-GPU Simulation and Training showing scalability effects in complex tasks, where benefits are notable with increased GPU count.
The multi-GPU experiments reveal marked improvements in task learning speed, particularly for tasks requiring more sophisticated control dynamics. While simple tasks exhibit diminishing returns with additional GPUs, the framework excels in handling intricate environments that push the limits of what single-node systems can achieve.
Conclusion
The introduction of GPU-accelerated simulations for Deep RL marks a significant advancement in reducing compute costs and training time for complex control tasks. This work paves the way for future developments in RL, particularly in applications requiring large-scale simulations or those constrained by hardware availability. The paper’s proposal to release the simulator to the community could catalyze further research and practical applications, offering a high-performance tool for robotics and beyond. Future work could explore integrating this simulator with vision-based tasks to further benefit from GPU optimization by leveraging direct zero-copy training methods.

