- The paper presents ProtoPNet, a deep learning model that integrates prototype layers to provide interpretable image classification by mapping learned prototypes to specific image patches.
- The methodology uses a convolutional network for feature extraction, a prototype similarity layer, and convex optimization to ensure transparent decision-making.
- The approach achieves competitive accuracy on bird and car datasets while maintaining interpretability, supporting trust in AI decisions.
This Looks Like That: Deep Learning for Interpretable Image Recognition
The paper "This Looks Like That: Deep Learning for Interpretable Image Recognition" (1806.10574) focuses on developing a deep learning model that provides interpretable image recognition results. The model, called the Prototypical Part Network (ProtoPNet), mirrors human interpretative patterns, using prototypical parts to dissect images for classification. This essay discusses the methodology, implementation, and implications of ProtoPNet, as well as its performance compared to existing solutions in the field.
ProtoPNet Architecture and Methodology
ProtoPNet is designed to offer inherent interpretability by integrating a prototype-based approach into its classification process. The architecture consists of three main components: a convolutional neural network for feature extraction, a prototype layer for similarity measurement, and a linear layer for classification. The prototype layer independently learns prototypical parts for each class, which can be mapped back to specific image patches. Unlike posthoc interpretability methods, ProtoPNet uses these prototypes directly in decision-making, ensuring the explanations are reflective of the model's internal reasoning process.
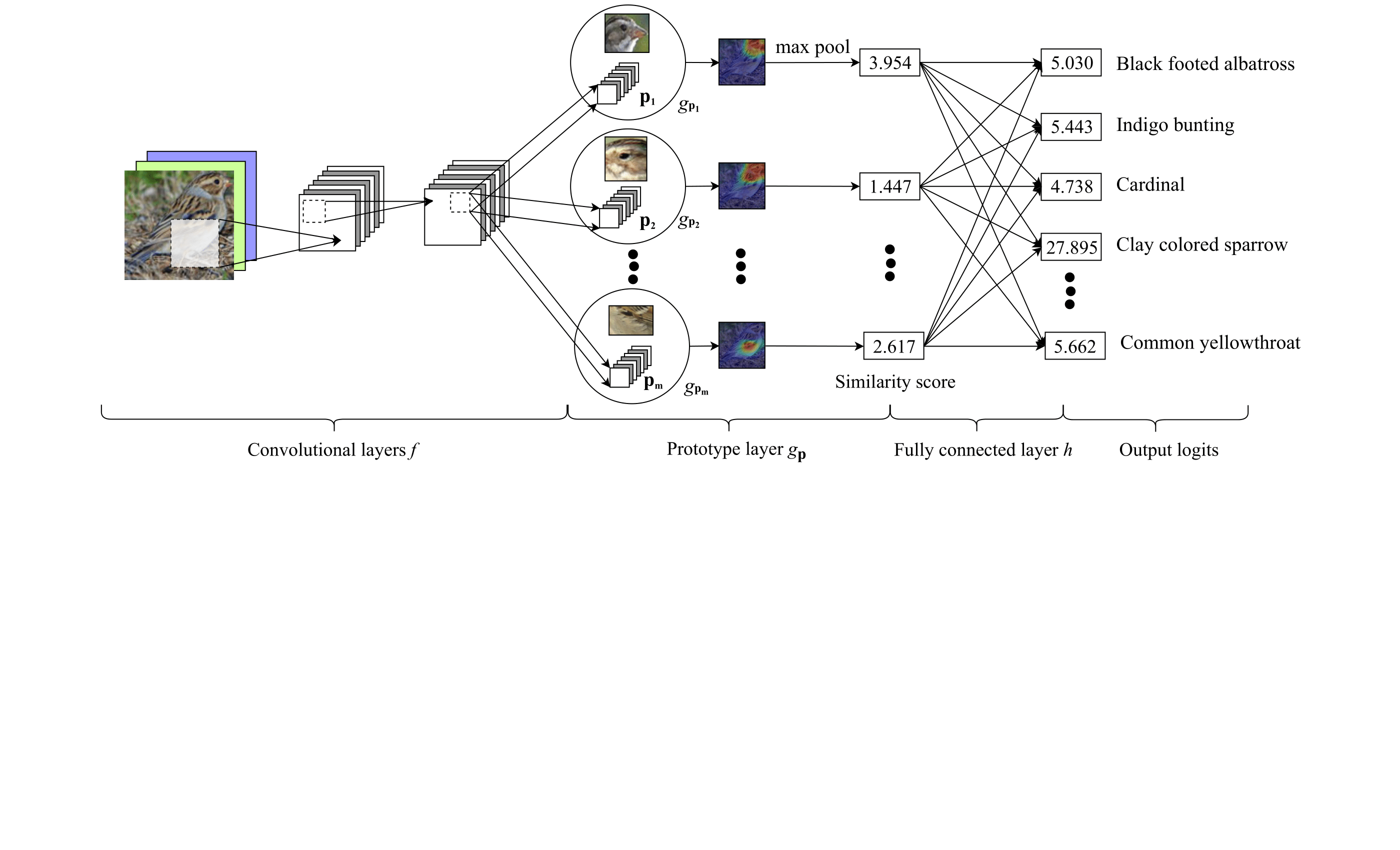
Figure 1: ProtoPNet architecture illustrating the extraction of features, assignment of prototypes, and final classification.
Training and Optimization
Training ProtoPNet involves a three-stage optimization process: stochastic gradient descent on the network layers excluding the final layer, projection of prototypes by mapping them to the closest latent training patches, and a convex optimization of the final linear layer. The prototype projection not only facilitates interpretability but also enables practical visualization by directly associating them with representative image parts.
Case Study: Bird and Car Species Identification
Bird Species Identification
Applying ProtoPNet to the CUB-200-2011 bird dataset, the network demonstrated robustness with an accuracy that is slightly lower than non-interpretable counterparts. The model's interpretability was showcased through visualization of its reasoning process for classifying bird images, where parts of birds strongly activating certain prototypes are highlighted. Through this, it was demonstrated that ProtoPNet could maintain comparable accuracy while offering substantial interpretability.

Figure 2: Image of a clay-colored sparrow with highlighted prototypical parts used to classify the bird's species.
Car Model Identification
In an additional scenario, ProtoPNet was implemented on the Stanford Cars dataset, achieving competitive accuracy with the added advantage of interpretability. The model compares favorably to existing models and maintained a small accuracy trade-off in return for enhanced insights into the decision-making process.
Comparative Analysis and Interpretability
ProtoPNet excels in providing a newly differentiated level of interpretability by linking activated parts of an image to learned generic prototypes. In comparative assessments, this interpretable technique complements existing convolutional architectures such as VGG, ResNet, and DenseNet, with minimal loss in accuracy yet substantial gains in understanding.
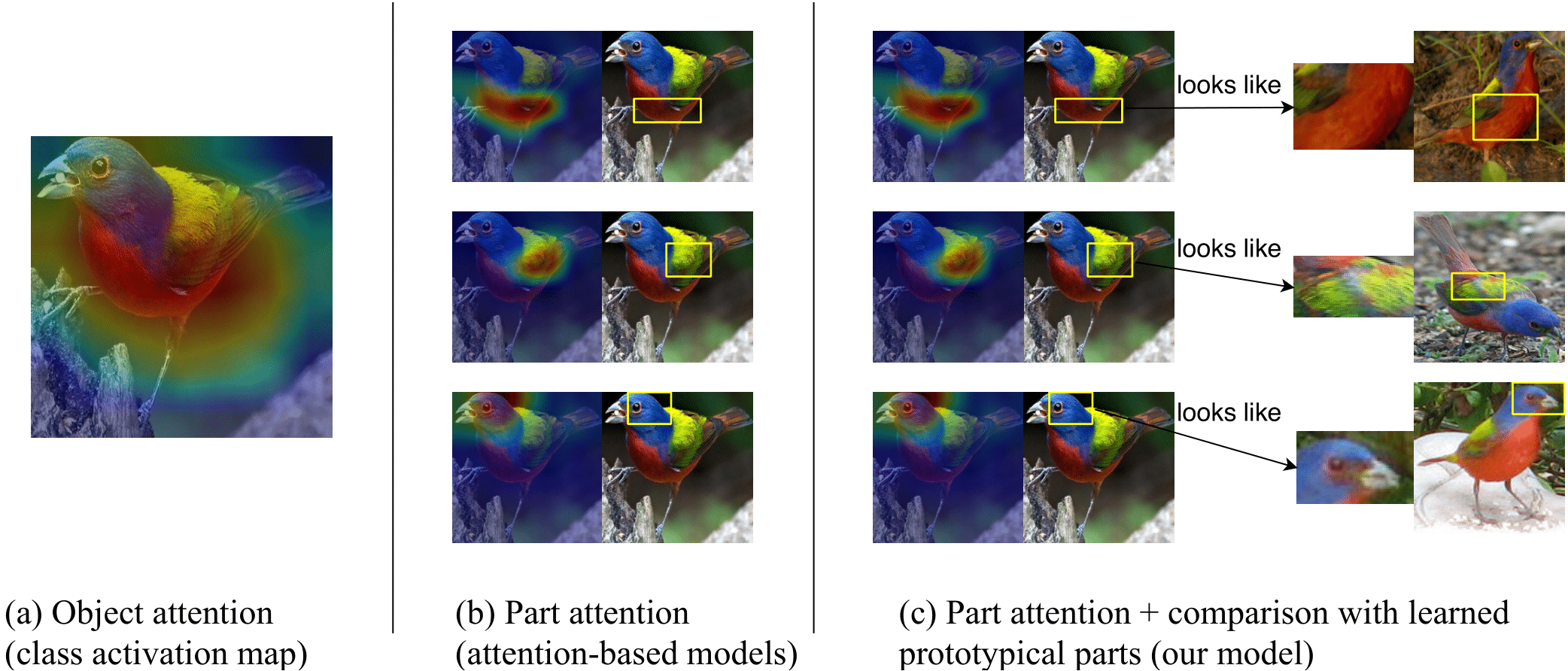
Figure 3: Visual comparison of different types of model interpretability comparing attention maps versus ProtoPNet’s prototype-based explanations.
Implications and Future Directions
The development of ProtoPNet represents an effective step towards aligned human-machine interpretability in AI models. It bolsters trust in AI decisions across applications that require transparent reasoning, such as medical diagnosis and fine-grained image recognition tasks. Future work should focus on refining prototype selection mechanisms and exploring ProtoPNet’s adaptation to other domains beyond image classification, potentially enhancing its robustness and applicability on sequential and non-image datasets.
Conclusion
"This Looks Like That: Deep Learning for Interpretable Image Recognition" introduces a methodologically sound and theoretically justified network that combines deep learning's power with an interpretable and transparent reasoning mechanism inspired by human experience. This work lays a critical foundation for further exploration into interpretable AI models, championing transparency without substantially compromising performance.

