- The paper introduces the Multimodal Factorization Model (MFM) that separates shared discriminative factors from modality-specific generative factors.
- It leverages a Bayesian network with encoder-decoder structures and Wasserstein approximations to jointly optimize generative and discriminative objectives.
- Experimental results on datasets like MNIST+SVHN and real-world multimodal time series demonstrate superior accuracy and resilience to missing modalities compared to baseline models.
Learning Factorized Multimodal Representations
Introduction
The study of multimodal machine learning focuses on developing models capable of leveraging multiple sources of data, such as text, images, and audio. "Learning Factorized Multimodal Representations" introduces the Multimodal Factorization Model (MFM), which robustly handles both intra and cross-modal interactions while remaining resilient to noisy and missing modalities. The proposed model excels by partitioning multimodal data into discriminative factors shared across modalities and modality-specific generative factors, using a joint generative-discriminative learning objective.
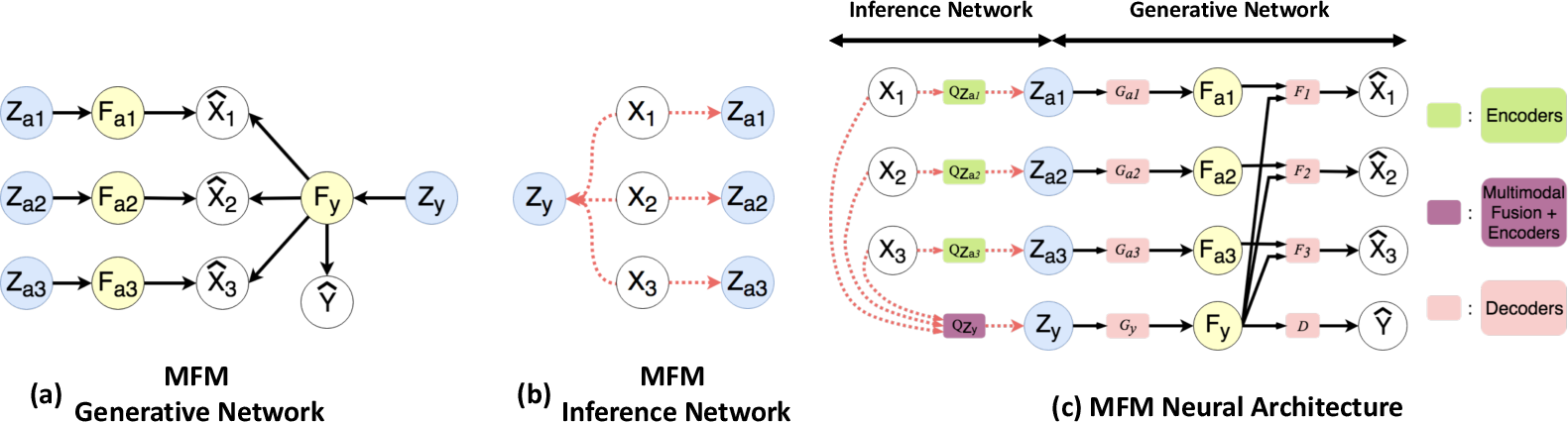
Figure 1: Illustration of the proposed Multimodal Factorization Model with three modalities.
Multimodal Factorization Model
Model Architecture
MFM assumes a Bayesian network that uses conditional independence to separate shared discriminative components from modality-specific generative components. Generative and discriminative components jointly handle inference, with encoder-decoder structures organized to maximize the distributional similarity between observed and generated data using Wasserstein distance approximations.
Implementation Details
The model leverages a neural architecture that uses nonlinear transformations within its encoder Q(Z∣X1:M,Y) and deterministic functions for its decoder modules. The optimization objective balances generative reconstruction loss with discriminative label prediction efficiency, ensuring performance robustness even with partial modality availability.
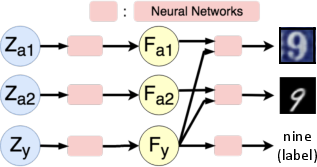
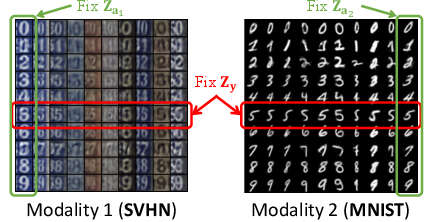
Figure 2: (a) MFM generative network structure/datasets, (b) classification accuracy, (c) conditional generation for digits.
Experimental Studies
Synthetic Image Dataset
The MNIST+SVHN dataset evaluates MFM's capability to manage distinct visual styles and shared labels. The model outperformed unimodal and multimodal baselines in accuracy and versatility, demonstrating superior discriminative and generative performance capabilities across random modality samples.
Real-world Multimodal Time Series
MFM outperformed existing models on six multimodal datasets, achieving state-of-the-art results in speaker traits, sentiment, and emotion recognition. Precise factorization of multimodal data enabled this model to surpass the efficacy of several contemporary frameworks like MFN and BC-LSTM.
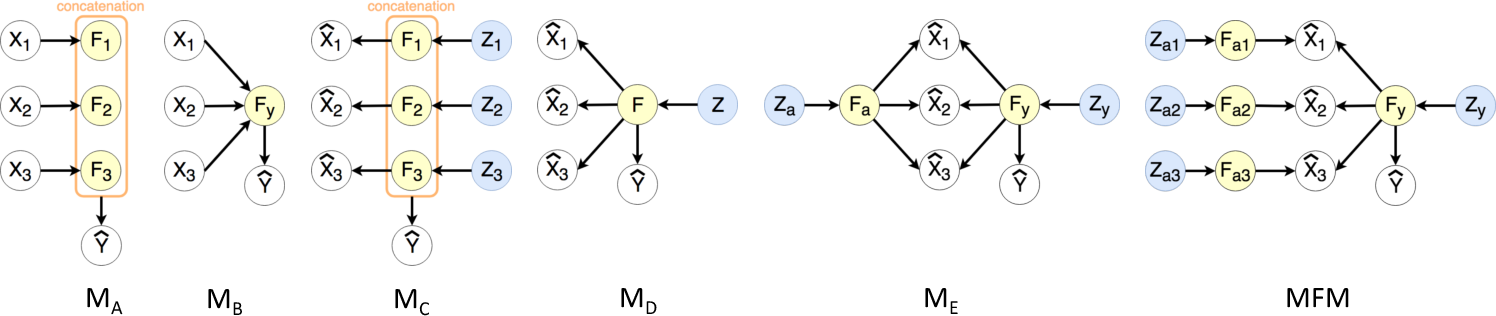
Figure 3: Ablation study results: Impact of omitting design components.
Handling Missing Modalities
Using surrogate inference allowed MFM to infer missing modalities effectively, maintaining robust predictive performance. Empirical tests demonstrated the model's impressive resilience to incomplete data scenarios, notably outperforming purely generative or discriminative approaches on various test sets.
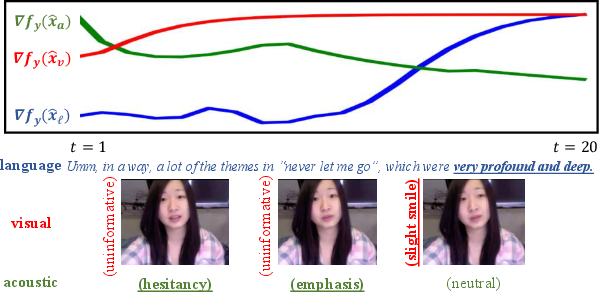
Figure 4: Analysis of multimodal representations using inference methods.
Conclusion
MFM marks a significant advance in multimodal approaches, particularly through its novel factorization method that optimally splits generative and discriminative aspects. The model's improvements in prediction accuracy and modality reconstruction establish it as a leading framework in multimodal learning. Future developments may explore extending MFM for unsupervised and semi-supervised methods, enhancing its utility across broader applications.