- The paper introduces a novel approach that integrates 3D cuboid object detection with monocular SLAM to improve mapping accuracy in diverse environments.
- The paper employs multi-view proposal generation and geometric scoring to refine 3D object detection, demonstrating superior performance on datasets like KITTI and SUN RGBD.
- The paper leverages object landmarks within bundle adjustment to reduce scale drift and enhance scene understanding, even in dynamic settings.
Overview of "CubeSLAM: Monocular 3D Object SLAM"
The paper "CubeSLAM: Monocular 3D Object SLAM" introduces a method for monocular 3D cuboid object detection and simultaneous localization and mapping (SLAM) in both static and dynamic environments. The integration of single image 3D object detection with multi-view object SLAM allows improvements in both tasks by leveraging each other's outputs. The approach does not require prior object models, making it versatile across different environments, particularly where monocular cameras are preferred due to their affordability and compact size.
Single Image 3D Object Detection
The primary goal of the single image detection algorithm is to generate high-quality 3D cuboid proposals from 2D bounding boxes obtained from converging lines known as vanishing points. This involves the following stages:
- Proposal Generation:
- Based on 2D bounding boxes, multiple 3D cuboid proposals are generated using sampled vanishing points and a scoring function that aligns proposals with image edges.
- The approach focuses on using geometric constraints to derive 3D position and orientation from the 2D perspective view.
- Proposal Scoring:
- Proposals are evaluated using cost functions that include measures like edge alignment to image features and geometric consistency.
- High accuracy is achieved by filtering the proposals through these constraints, ensuring alignment with edges detected in the image.
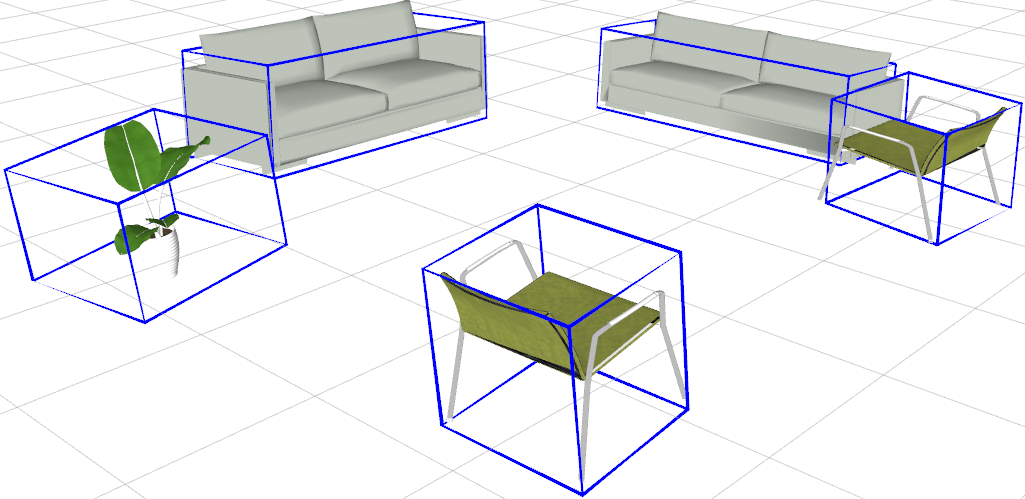
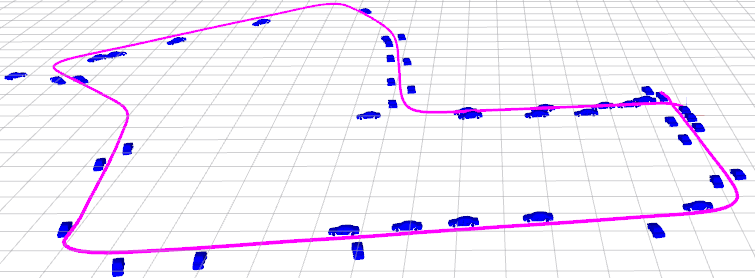
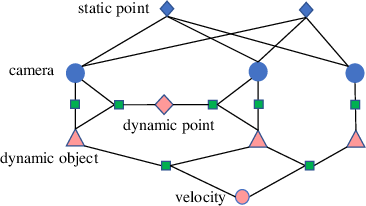
Figure 1: Cuboid proposals generation from 2D object box. If vanishing points and one corner are estimated, the other seven corners can also be computed analytically.
Object SLAM in Static Environments
In the SLAM process, object detection outputs are integrated into the bundle adjustment (BA) optimization framework. The BA jointly optimizes camera poses, 3D points, and object positions:
- Measurement Models:
- Measurements between cameras and objects as well as between objects and points are defined to enhance the mapping accuracy.
- Objects provide additional constraints that help in reducing the scale drift inherent in monocular SLAM systems.
- Data Association:
- Effective tracking and association of detected objects across multiple frames are achieved using feature-based correspondences.
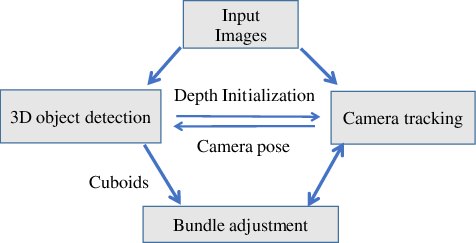
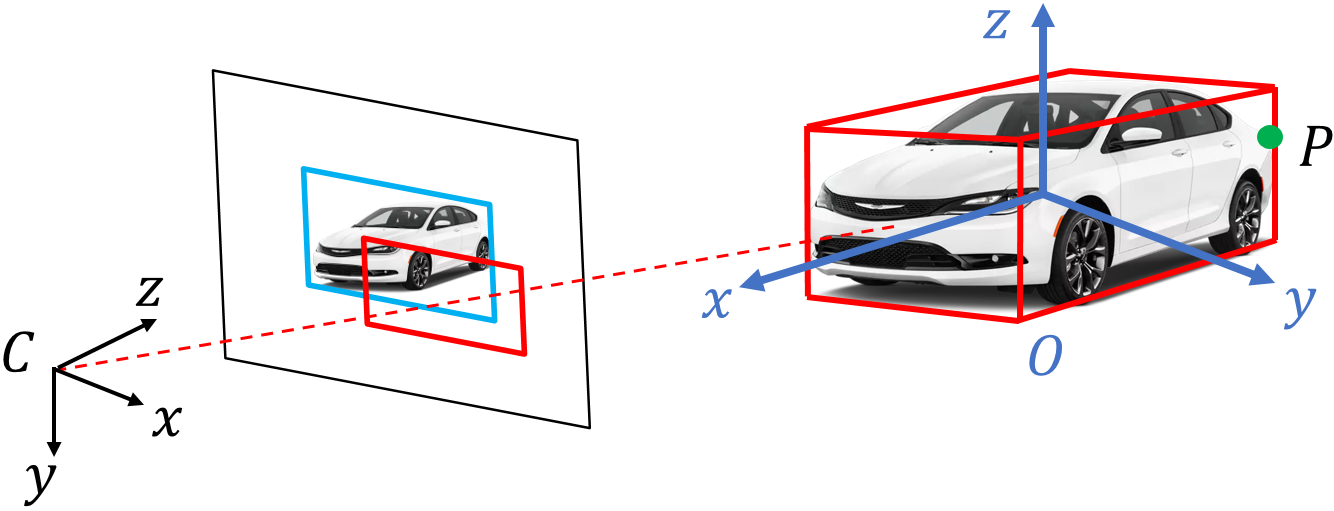
Figure 2: Our object SLAM pipeline. Single view object detection provides cuboid landmark and depth initialization for SLAM while SLAM can estimate camera pose for more accurate object detection.
Dynamic Object SLAM
In dynamic environments, the system extends the static framework to accommodate moving objects:
- Dynamic Object Tracking:
- The framework models the motion of dynamic objects using a combination of rigid body dynamics and motion models to ensure the accurate estimation of both camera and object trajectory.
- Optimization:
The paper's experimental results indicate:
- Superior 3D object detection accuracy in datasets like SUN RGBD and KITTI when compared to competing approaches.
- Improved camera pose estimation accuracy, surpassing monocular SLAM baselines on public benchmarks such as the KITTI odometry dataset.
- Effective handling of both static and dynamic objects, demonstrating the system's robustness across various environmental conditions.
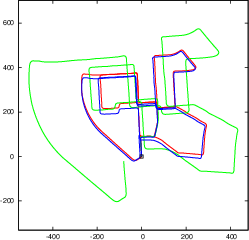
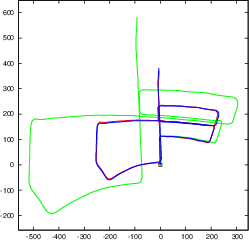
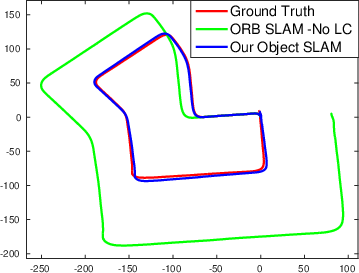
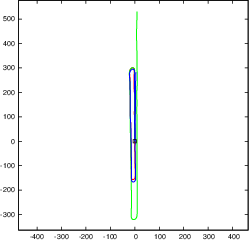

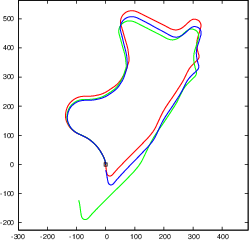
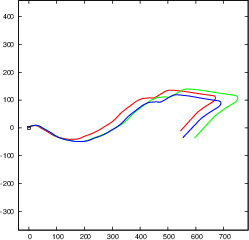
Figure 4: Our object SLAM on KITTI odometry benchmark without loop closure detection and constant ground height assumption. Objects can reduce monocular scale drift and improve pose estimation accuracy.
Conclusion
The study convincingly demonstrates the advantages of integrating object detection with SLAM, emphasizing the reciprocal benefits where object-based landmarks provide essential constraints for pose estimation. This work moves towards more complete scene understanding by utilizing geometric and semantic information collaboratively, paving the way for enhanced robotic perception tasks in diverse applications such as autonomous driving and augmented reality. Future directions include incorporating dense mapping techniques and more comprehensive scene understanding capabilities into the CubeSLAM framework.