- The paper proposes a novel low-rank tensor decomposition approach to reduce computational complexity while fusing multimodal data efficiently.
- It demonstrates that the method outperforms traditional tensor-based fusion techniques in tasks like sentiment analysis, speaker trait, and emotion recognition.
- Experiments show reduced parameter count and faster inference, underscoring the scalability and practical applicability of the approach.
Efficient Low-rank Multimodal Fusion with Modality-Specific Factors
Introduction
This paper addresses the challenge of multimodal fusion in AI, particularly focusing on integrating heterogeneous data from modalities such as audio, visual, and textual inputs. Traditional tensor-based methods for multimodal fusion suffer from exponential increases in computational complexity and memory requirements. The proposed Low-rank Multimodal Fusion (LMF) method utilizes low-rank tensor approximations to reduce computational complexity while maintaining competitive performance across multimodal tasks such as sentiment analysis, speaker trait recognition, and emotion recognition.
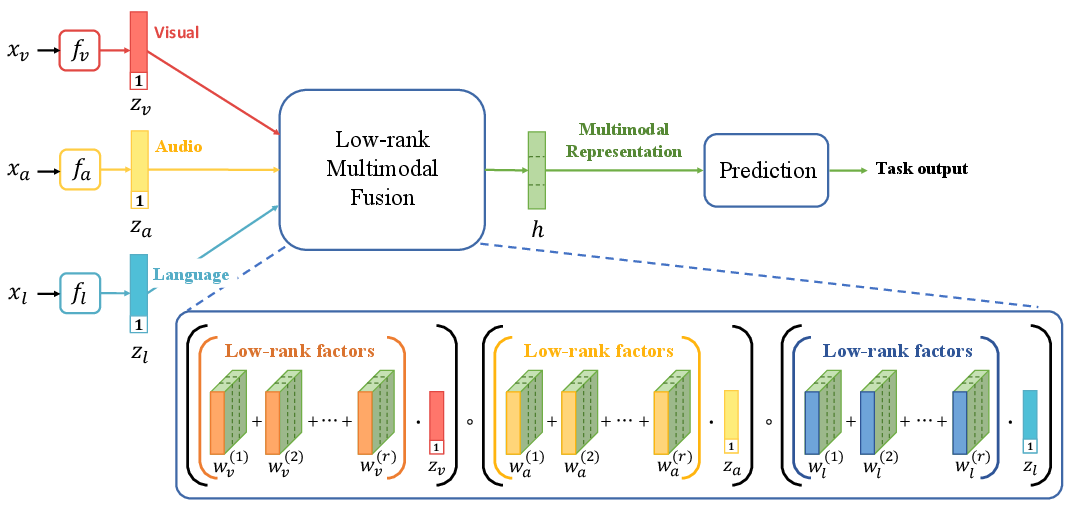
Figure 1: Overview of the Low-rank Multimodal Fusion model structure, illustrating modality-specific factors.
Proposed Methodology
The LMF approach leverages low-rank weight tensor decomposition to efficiently perform multimodal fusion without explicitly forming high-dimensional tensors. The model operates by decomposing the weight tensor associated with the output of fusion tasks into modality-specific low-rank factors. This is achieved by parameterizing the multidimensional tensor as a set of rank-specific modality vectors. The approach reduces the number of parameters, allowing the model to scale linearly with the number of modalities, opposed to the traditional exponential growth.
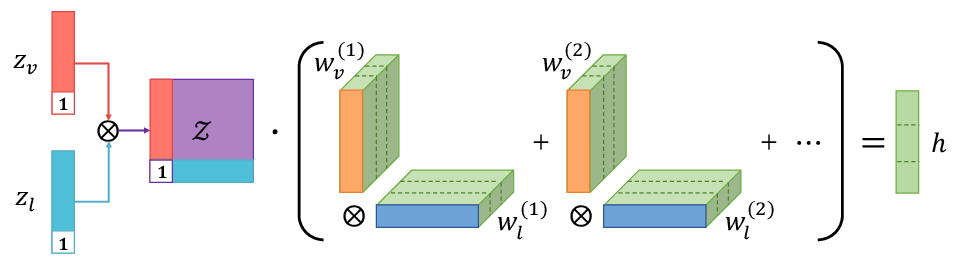
Figure 2: Decomposing weight tensor into low-rank factors.
Efficient Fusion Computation
An essential component of LMF is the exploitation of the inherent parallel structure between the low-rank decomposed weights and the input tensors. This parallel decomposition facilitates efficient computations through multilinear transformations, circumventing the need to compute the outer product tensor explicitly. The final output computation employs element-wise operations to aggregate modality-specific projections, significantly reducing computational overhead.
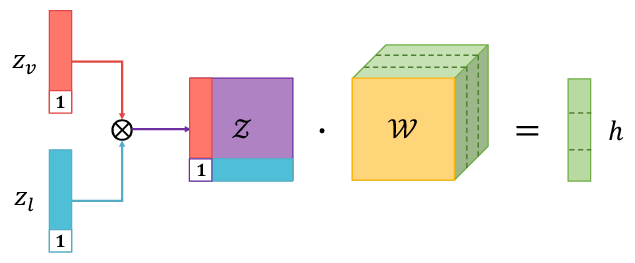
Figure 3: Tensor fusion via tensor outer product.
Experimental Analysis
The experimental setup benchmarks LMF against state-of-the-art models across tasks using large multimodal datasets such as CMU-MOSI for sentiment analysis, POM for speaker trait recognition, and IEMOCAP for emotion identification. The results demonstrate the LMF’s capability to outperform traditional tensor-based fusion methods like Tensor Fusion Network (TFN) both in accuracy and computational efficiency.
LMF exhibits lower mean absolute error (MAE) and higher Pearson correlation coefficients, indicating robust predictive performance. Additionally, experimentation across varied rank settings shows that LMF maintains stable performance with lower ranks, mitigating overfitting risks while achieving substantial computational savings.
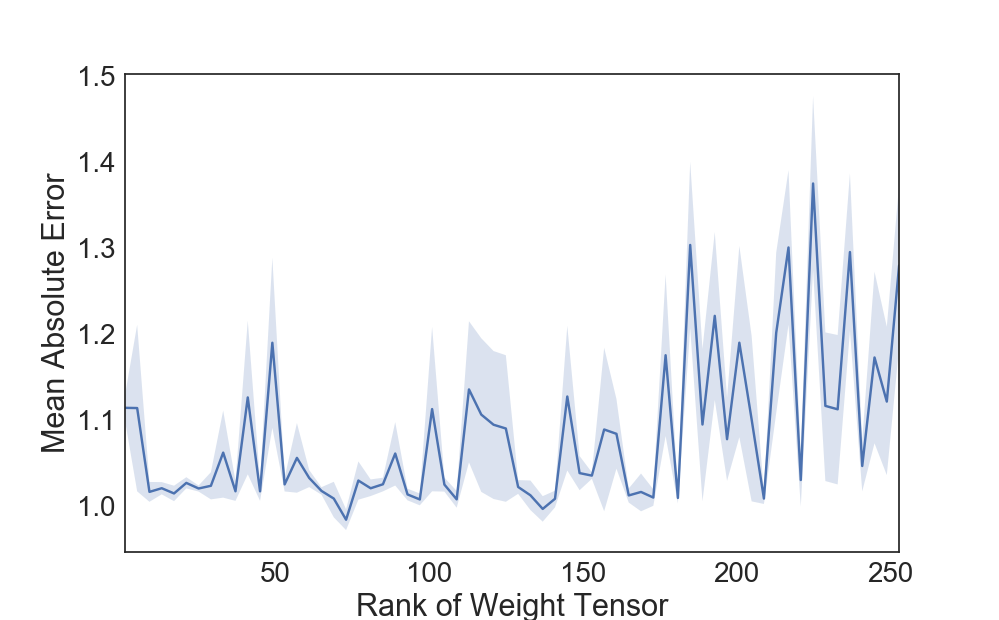
Figure 4: The Impact of different rank settings on Model Performance.
Computational Efficiency
The theoretical complexity of LMF is significantly reduced to O(dy×r×∑m=1Mdm) compared to O(dy∏m=1Mdm) in traditional tensor methods. Empirical results confirm that LMF utilizes an order of magnitude fewer parameters than TFN and achieves faster inference times, validated by performance benchmarking on NVIDIA GPUs.
Conclusion
The LMF model demonstrates that multimodal fusion can be performed efficiently by leveraging low-rank tensor approximations, thereby scaling linearly with the number of input modalities. This advancement offers a compelling alternative to traditional tensor-based methods, suggesting future directions towards integrating low-rank tensors in broader AI domains like attention mechanisms. The reduction in computational complexity positions LMF as a promising approach in scenarios involving multimodal data integration, enabling seamless and efficient deployment in real-world applications.

