- The paper introduces a CycleGAN-based method with GC loss to improve edge accuracy in MR-to-CT image synthesis.
- It shows that increasing training data and using GC loss significantly improve MAE, PSNR, and mutual information metrics.
- The approach enhances segmentation performance for musculoskeletal structures, advancing modality-independent imaging.
Cross-Modality Image Synthesis Using CycleGAN
Introduction
The paper "Cross-modality image synthesis from unpaired data using CycleGAN: Effects of gradient consistency loss and training data size" explores the enhancement of MR-to-CT synthesis by integrating Gradient Consistency (GC) loss into CycleGAN to hone the precision of boundaries. The primary objective is MR-to-CT synthesis, which could help improve the delineation of bone and muscle boundaries. MRI offers superior soft tissue contrast, while CT excels in visualizing bone structures, rendering it crucial for orthopedic procedures. This synthesis aids in achieving modality-independent segmentation, eliminating the manual tracing required for MRI.
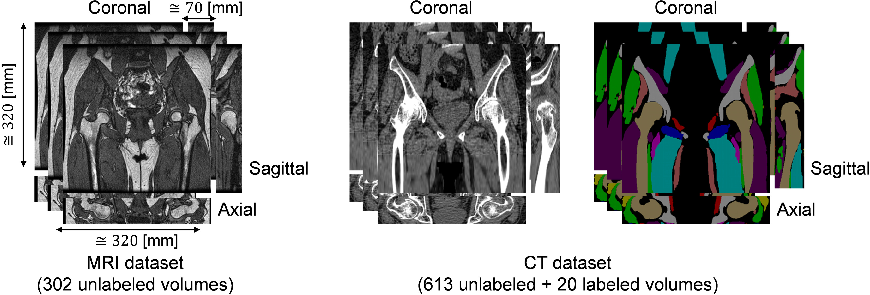
Figure 1: Training datasets used in this study. MRI dataset consists of 302 unlabeled volumes and CT dataset consists of 613 unlabeled and 20 labeled volumes.
Methodology
Dataset Composition
The research utilized datasets comprising 302 MRI volumes and 613 CT volumes, with a foundational preparation involving N4ITK intensity correction to standardize imaging. The MRI volumes offered insights into musculoskeletal structures, while CT volumes provided clarity on bone architecture. Examining the effects of training data size and GC loss were pivotal to the study.
CycleGAN and Gradient Consistency Loss
The CycleGAN framework effectively processes unpaired data by leveraging cycle consistency losses. The integration of GC loss specifically aims to enhance edge alignment. This study's methodology followed Zhu et al.'s CycleGAN adaptation, tailored with GC loss to refine boundary precision.
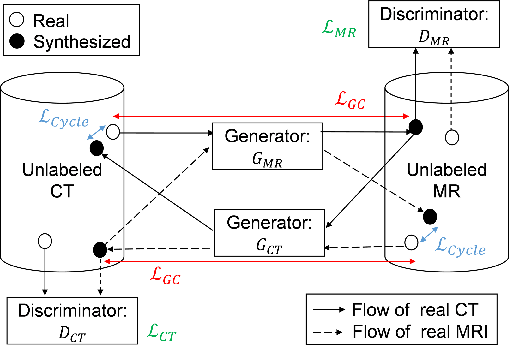
Figure 2: Workflow of the proposed method. GCT and GMR are generator networks that translate MR to CT images, and CT to MR images, respectively.
Experimentation and Results
Image Synthesis Evaluation
The first experiment analyzed the impact of training data volume and GC loss inclusion on synthesized image accuracy. Metrics like Mean Absolute Error (MAE) and Peak-Signal-to-Noise Ratio (PSNR) were employed to gauge synthesis accuracy. The findings revealed that increasing training data size and incorporating GC loss improved MAE and PSNR values.
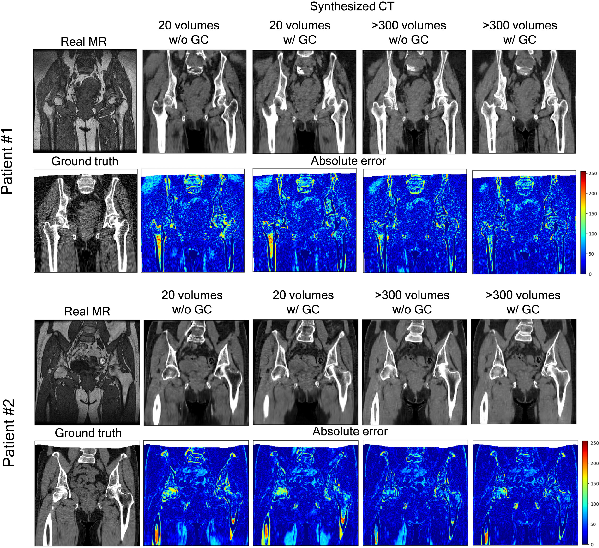
Figure 3: Representative results of the absolute error between the ground truth paired CT and synthesized CT from two patients.
In a subsequent experiment, Mutual Information (MI) was evaluated to study synthesis quality in unpaired settings. The GC loss significantly improved MI between synthesized CT and MRI, indicating better edge preservation and consistency in the synthesized images.
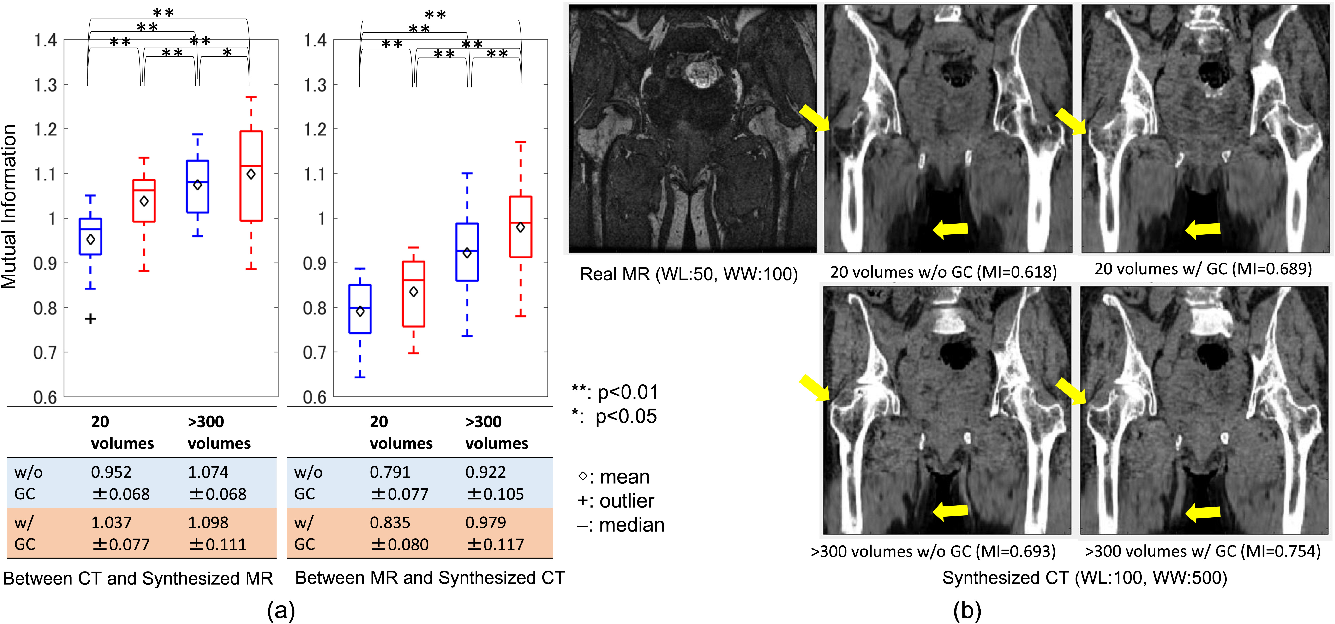
Figure 4: Evaluation of similarity between the real and synthesized volumes. (a) quantitative comparison of mutual information on different training data size with and without the gradient-consistency loss.
Segmentation Results
To assess segmentation performance, 2D U-net architecture was leveraged, analyzing four musculoskeletal structures. The synthesis facilitated effective segmentation, with GC loss contributing to improved DICE coefficients across pelvic, femur, and muscle regions.
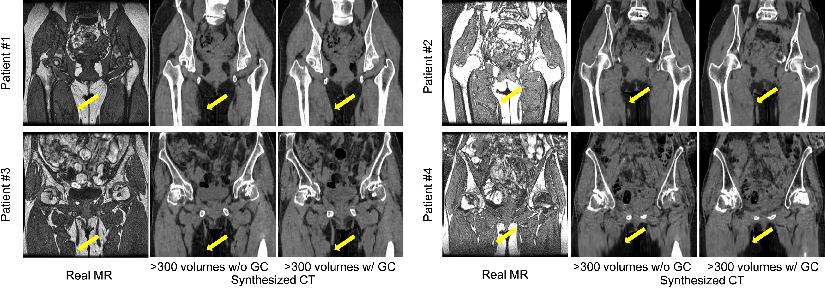
Figure 5: Representative results of translation from real MR to synthesized CT of four patients with and without the gradient consistency loss.
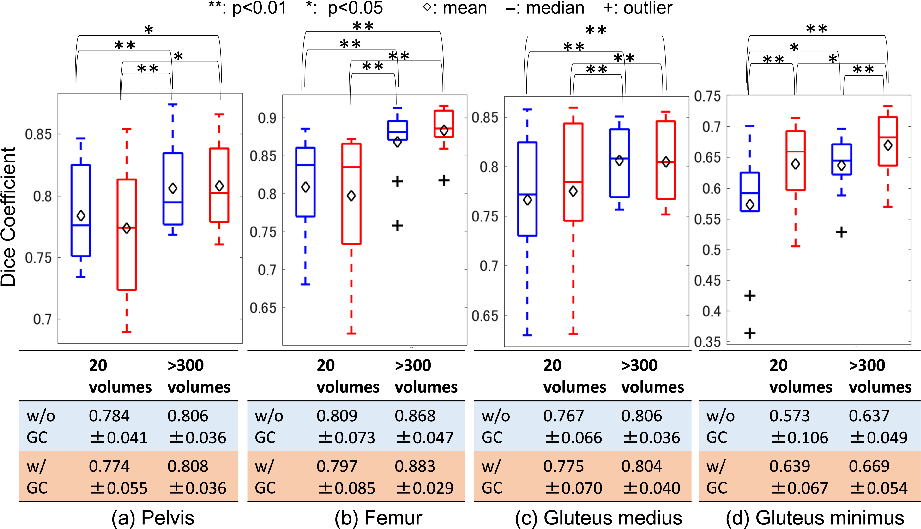
Figure 6: Evaluation of segmentation accuracy on different training data size in CycleGAN with and without the gradient-consistency loss.
Discussion
This study's findings underscore the efficacy of GC loss in refining CycleGAN's synthesis capabilities, particularly in edge accuracy. The improvements noted with increased training data volumes further validate the necessity of robust datasets in cross-modality synthesis tasks. Despite the promising results, limitations persist, notably exclusions of patients with implants, which are common in the target population. Future research may explore the integration of image synthesis and segmentation networks for enhanced modality-independent segmentation accuracy.
Conclusion
The research provides valuable insights into optimizing MR-to-CT image synthesis through CycleGAN with GC loss, emphasizing data volume significance. The implications extend into realms of modality-independent segmentation, potentially transforming musculoskeletal imaging and diagnostic practices. Further exploration into hybrid models combining synthesis and segmentation could yield superior results, enhancing practical healthcare applications.