Ray: A Distributed Framework for Emerging AI Applications
Abstract: The next generation of AI applications will continuously interact with the environment and learn from these interactions. These applications impose new and demanding systems requirements, both in terms of performance and flexibility. In this paper, we consider these requirements and present Ray---a distributed system to address them. Ray implements a unified interface that can express both task-parallel and actor-based computations, supported by a single dynamic execution engine. To meet the performance requirements, Ray employs a distributed scheduler and a distributed and fault-tolerant store to manage the system's control state. In our experiments, we demonstrate scaling beyond 1.8 million tasks per second and better performance than existing specialized systems for several challenging reinforcement learning applications.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a concise, actionable list of the main knowledge gaps, limitations, and open questions that remain unresolved by the paper.
- Actor failure recovery semantics: The paper states lineage-based recovery for actors but does not detail how actor state is reconstructed (e.g., method replay, checkpoints, or deterministic re-execution), how often to checkpoint, and how to handle non-determinism or external side effects during recovery.
- Exactly-once vs at-least-once execution: For stateful actor methods (which may have side effects), the execution guarantees under failures/retries are not specified, leaving unclear how duplicate or lost updates are avoided.
- Actor mobility and scaling: Actors are fixed to a node and execute serially; there is no support for actor migration, horizontal scaling of a stateful service, or multi-threaded/concurrent actor methods, which can bottleneck serving/training workloads.
- Backpressure and overload control: The system lacks a described mechanism for limiting task submission rates or applying backpressure when the GCS, schedulers, or object stores are overloaded.
- Straggler mitigation and speculative execution: The paper explicitly notes the lack of straggler mitigation; there is no mechanism for speculative task re-execution or prioritization to control tail latencies.
- Scheduling fairness and multi-tenancy: The bottom-up scheduler omits policies for job/user fairness, priority scheduling, quotas, or admission control in shared clusters.
- Deadline- or SLA-aware scheduling: There is no support for latency SLOs (critical for serving) or deadline-based scheduling for mixed workloads.
- Gang scheduling and collectives: The scheduler does not address gang scheduling for tightly-coupled tasks (e.g., allreduce) or optimized placement strategies to minimize communication in collectives.
- Stability of scheduler heuristics: The global scheduler’s simple estimates (queue sizes, average execution/bandwidth via exponential smoothing) are not analyzed for stability, oscillation, or sensitivity to workload non-stationarity.
- GCS scalability under skew and hot keys: While sharded, the GCS behavior under heavy skew (e.g., hot objects, many subscribers to a few keys) and the effectiveness of shard rebalancing or hot-spot mitigation are not evaluated.
- GCS failure modes and recovery: The chain replication design’s failover latency, consistency guarantees under partitions, and recovery behavior for pub-sub streams are unspecified.
- Memory management and object lifecycle: The paper does not describe reference tracking, garbage collection of immutable objects, or prevention of memory pressure cascades when many large objects are produced faster than they can be consumed.
- Object store spill/eviction policy: Only an LRU spill-to-disk policy is mentioned; there is no discussion of distributed spill coordination, spill bandwidth contention, or priority-aware eviction to protect critical data.
- No native support for distributed (sharded) objects: Large tensors/graphs must be manually sharded at the application level; missing are APIs and runtime support for partitioned objects, placement-aware shards, and co-scheduling.
- Data transfer performance limits: Transfers are TCP-based and striped; the paper does not explore RDMA, zero-copy across nodes, NIC offloads, or congestion control for bulk transfers and high-throughput collectives.
- GPU/accelerator memory movement: There is no quantified overhead for transferring data between the Arrow/CPU object store and device memory, nor mechanisms for zero-copy GPU pipelines or device-to-device transfers.
- Heterogeneous resource modeling limitations: Beyond simple resource tags (e.g., GPUs), the paper does not address NUMA locality, multi-GPU gang allocation, TPU/FPGA constraints, or dynamic resource fragmentation.
- Autoscaling and elastic cluster management: The system lacks a built-in autoscaler or elastic policies (scale-up/down) and does not discuss placement changes as cluster size varies.
- Serving-specific latency/tail benchmarks: While claiming millisecond-level latencies, the evaluation does not report end-to-end serving tail latencies under load, cold-start costs (actor instantiation/model load), or jitter in closed-loop control.
- Real-world RL integration and hardware: Experiments focus on AWS and do not evaluate on physical robots, embedded devices, or latency-critical control loops where jitter and worst-case guarantees matter.
- Consistency and determinism in RL pipelines: The paper does not discuss controlling non-determinism (random seeds, floating-point variance) across re-executions to make lineage replay reliable for debugging and recovery.
- Debugging, tracing, and observability tooling: Although the GCS purportedly simplifies tooling, concrete tools, UIs, or APIs for tracing task graphs, profiling hot paths, and diagnosing failures are not presented.
- Security and isolation: There is no discussion of authentication, authorization, network isolation, code sandboxing for user functions, or cross-tenant isolation in shared clusters.
- Resource quotas and accounting: The system omits mechanisms for per-user or per-job quotas, billing/accounting, or enforcement of limits to prevent noisy-neighbor effects.
- Interoperability overheads with DL frameworks: The cost of crossing boundaries between Ray and frameworks (TensorFlow/PyTorch), including (de)serialization and device transfer overheads, is not quantified.
- Cross-language support: The API targets Python; there is no discussion of cross-language execution, data interchange formats beyond Arrow, or multi-language scheduling constraints.
- Fault-tolerant I/O and durable outputs: Objects are reconstructed via lineage, but there is no path for durable, externally-consumable outputs (e.g., checkpoints, logs) across cluster failures beyond ad hoc application logic.
- Deadlock and cyclic dependency detection: The dynamic task graph model does not specify how cyclic dependencies, blocked futures, or driver/worker-induced deadlocks are detected and resolved.
- Actor–object store coherence policies: The interplay between mutable actor state and immutable objects is not formalized; when/what to materialize as objects vs keep in actor memory remains an ad hoc design decision for users.
- Placement-aware API controls: Beyond resource counts, users have limited means to constrain placement (e.g., anti-affinity, rack-awareness, colocation with specific data shards) or to hint at expected data reuse.
- Evaluation of GCS and scheduler latency/tails: The microbenchmarks report peak throughput, but do not provide p99/p999 control-plane latencies (task submission, lookup, pub-sub delivery) under high load.
- Network topology awareness: Scheduling and data movement do not account for rack-level locality or cross-AZ/region deployments, risking suboptimal placement and higher transfer costs.
- Formal semantics of control edges: The semantics and ordering guarantees of “control edges” for nested remote calls are not specified in the presence of failures, retries, and concurrent invocations.
- Handling of external side effects in tasks: Tasks are assumed side-effect free, but the system does not enforce or detect violations (e.g., I/O, external services), which can undermine lineage-based recovery.
- API ergonomics for complex RL workflows: While an example is provided, patterns for common RL components (experience buffers, parameter servers, distributed sampling) and reusable libraries are not systematized within the API.
- Cost modeling and tuning guidelines: There are no guidelines or tools to help users choose task granularity, actor vs task designs, or checkpoint intervals to balance latency, throughput, and recovery costs.
- Long-term evolution for broader workloads: The paper explicitly does not target full data-parallel analytics (e.g., query optimization), leaving open how Ray will interoperate with or complement such systems in production pipelines.
Practical Applications
Below are practical applications that flow directly from the paper’s findings and system innovations (unified task+actor API, dynamic task graph, sharded global control store, bottom-up distributed scheduler, and in-memory object store). Each item names concrete use cases, target sectors, likely tools/workflows, and key assumptions or dependencies.
Immediate Applications
These can be deployed now with the framework as described.
- Unified RL pipelines for research and product prototyping
- Sectors: Software/AI infrastructure, Academia, Robotics, Gaming
- Use case: Build end-to-end reinforcement learning workflows that tightly couple simulation, distributed training (SGD/parameter server/allreduce), and low-latency policy serving in a single system.
- Tools/workflows: Python-based pipelines integrating OpenAI Gym/DM Control/MuJoCo with TensorFlow/PyTorch; experiment scripts using futures, ray.wait, and actors for simulators and parameter servers; lineage-backed replay for failure recovery.
- Assumptions/dependencies: Access to CPU/GPU clusters; integration with external DL frameworks; model management (versioning, canarying) may still require external serving systems.
- Massive parallel simulation farms for policy evaluation
- Sectors: Robotics, Gaming, Autonomous systems, Operations Research
- Use case: Execute millions of short, heterogeneous simulations (e.g., rollouts, Monte Carlo tree search) with millisecond latencies, leveraging task locality for large state inputs.
- Tools/workflows: Actor-wrapped third-party simulators; task-parallel post-processing on simulation outputs via shared object store; autoscaled clusters.
- Assumptions/dependencies: Simulator licensing/runtime availability; sufficient network bandwidth and memory to keep hot objects in RAM; immutable object design.
- Distributed deep RL training with parameter servers or allreduce
- Sectors: Software/AI infrastructure, Robotics, Gaming
- Use case: Implement parameter servers as actors or custom allreduce using tasks/futures for policy/value network training.
- Tools/workflows: Actor-based parameter server classes; task pipelines that batch gradients and update policies; GPU-aware resource annotations in the scheduler.
- Assumptions/dependencies: Stable GPU nodes; external DL libraries; careful batching to amortize serialization where appropriate.
- Low-latency policy serving for interactive control
- Sectors: Robotics, Industrial automation, Gaming
- Use case: Serve policies with millisecond-level inference latencies, using actors for stateful models and tasks for stateless inference.
- Tools/workflows: Dedicated serving actors pinned to GPUs/CPUs; locality-aware placement of pre/post-processing tasks; object-store-based zero-copy within node.
- Assumptions/dependencies: Production deployment needs surrounding tooling (A/B testing, model versioning); strict real-time guarantees may require further hardening.
- Large-scale hyperparameter sweeps and ablation studies
- Sectors: Academia, Industry R&D
- Use case: Launch thousands to millions of fine-grained experiments (e.g., different seeds, hyperparameters) with lineage-based reproducibility and failure recovery.
- Tools/workflows: Task graphs representing trials; ray.wait to exploit early results; dashboards built from GCS metadata for monitoring.
- Assumptions/dependencies: Experiment tracking outside the core (e.g., logging stores); budget for compute.
- Offline RL and sequential decision policy evaluation from logs
- Sectors: E-commerce, Ads, Recommender systems
- Use case: Simulate counterfactual trajectories (when simulators exist or are learned) and train policies with distributed SGD; batch inference for evaluation.
- Tools/workflows: Task-based data preprocessing; actor-based learned simulators; distributed evaluation harnesses.
- Assumptions/dependencies: Availability and validity of simulators or learned environment models; data governance.
- Scalable experimentation in academic courses and labs
- Sectors: Education, Academia
- Use case: Students and researchers run distributed RL labs and projects “pip install”-ready on small clusters or cloud credits.
- Tools/workflows: Prebuilt training/simulation scripts; shared cluster with quotas; object-store-backed datasets for zero-copy within node.
- Assumptions/dependencies: Cluster access; basic DevOps for sandboxing.
- Dynamic microservice-style orchestration for ML-heavy workflows
- Sectors: Software/AI infrastructure
- Use case: Orchestrate heterogeneous, fine-grained tasks (feature extraction, model scoring, post-processing) with dynamic dependencies that evolve at runtime.
- Tools/workflows: Task DAGs with nested remote calls; actor-based stateful microservices (e.g., cached embedding services).
- Assumptions/dependencies: Not a full general-purpose data-parallel replacement (e.g., lacks SQL/query optimization); complement with existing data systems.
- Financial strategy backtesting and RL policy training
- Sectors: Finance
- Use case: Run large numbers of historical simulations and train RL policies for execution, inventory, or allocation using parallel rollouts and distributed training.
- Tools/workflows: Actor-wrapped market simulators; task-parallel scenario generation; wait-for-first-k evaluation to prune poor strategies early.
- Assumptions/dependencies: Market simulators and compliance constraints; careful latency control if moving to live serving.
- Operations and scheduling research via simulation-based RL
- Sectors: Cloud/Datacenter Ops, Manufacturing
- Use case: Train and evaluate schedulers/dispatchers (e.g., job scheduling, buffer management) via parallel simulation and policy improvement loops.
- Tools/workflows: Actor-based environment emulators; task-based rollout/evaluation at scale; bottom-up scheduler for locality and throughput.
- Assumptions/dependencies: Fidelity of simulators to real systems; safety review before deployment.
- Reproducible debugging and profiling of distributed experiments
- Sectors: Software/AI infrastructure, Academia
- Use case: Use the global control store’s lineage and pub-sub to build debugging/profiling/visualization tools that track task dependencies and timings.
- Tools/workflows: Experiment dashboards; lineage re-execution for post-mortem analysis; performance heatmaps across nodes.
- Assumptions/dependencies: Building thin visualization layers on GCS metadata; log retention policies.
Long-Term Applications
These require additional research, scaling, or productization (e.g., safety, regulatory, or ecosystem tooling).
- City-scale traffic signal control and mobility optimization via multi-agent RL
- Sectors: Public policy, Transportation, Smart cities
- Potential: Use massive, fine-grained simulations and dynamic task graphs to train and evaluate multi-intersection controllers; deploy with low-latency serving.
- Dependencies: High-fidelity traffic simulators; robust sim-to-real transfer; governance and safety validation.
- Smart grid and demand response control
- Sectors: Energy
- Potential: Coordinate millions of devices (DERs, EV charging) with learned policies trained in distributed, heterogeneous simulations.
- Dependencies: Digital twins for grid segments; strict reliability constraints; secure, real-time deployment infrastructure.
- Personalized healthcare treatment policies and clinical decision support
- Sectors: Healthcare
- Potential: Offline RL on longitudinal health data paired with patient simulators for counterfactual evaluation; clinician-in-the-loop serving.
- Dependencies: Validated patient simulators; privacy and regulatory compliance; rigorous safety/efficacy trials.
- Autonomous vehicle and robotics fleet learning at scale
- Sectors: Robotics, Automotive
- Potential: Continual learning pipelines that integrate massive simulation (closed-loop), distributed training, and controlled rollout to fleets.
- Dependencies: Rich simulators and domain randomization; real-time constraints and safety cases; strong MLOps and monitoring.
- Adaptive tutoring and curriculum optimization
- Sectors: Education
- Potential: Train policies for personalized lesson sequencing using simulated learners or learned environment models; evaluate at scale.
- Dependencies: Valid learner models; fairness and privacy safeguards; integration with LMS platforms.
- Real-time bidding and budget pacing policies with low-latency serving
- Sectors: Advertising/Marketing
- Potential: Joint simulation+training of bidding strategies with millisecond decision serving leveraging the actor model.
- Dependencies: Production-grade serving guarantees; compliance with auction rules and privacy; robust monitoring.
- Large-scale agent-based policy labs for economic and epidemiological interventions
- Sectors: Public policy, Economics, Public health
- Potential: Explore interventions through distributed simulations with dynamic task graphs; train decision policies or evaluate rule-based policies.
- Dependencies: Validated agent-based models; interdisciplinary review; transparent assumptions for policy trust.
- Industrial automation and process control
- Sectors: Manufacturing, Logistics
- Potential: Closed-loop RL for process tuning trained on high-throughput simulation; hybrid actor/task serving on the edge.
- Dependencies: OT/IT integration; certification and fail-safe mechanisms; latency/jitter management.
- Serverless and fine-grained cloud computing inspired by bottom-up scheduling
- Sectors: Cloud/DevOps
- Potential: Next-gen serverless platforms incorporating Ray’s bottom-up scheduler and sharded control store to support data-aware microtasks.
- Dependencies: Cloud provider integration; isolation and multi-tenancy; billing and quota controls.
- Digital twins for design optimization and predictive maintenance
- Sectors: Aerospace, Automotive, Energy, Industrial
- Potential: Orchestrate parameter sweeps, surrogate model training, and control policy learning across complex simulators as dynamic task graphs.
- Dependencies: High-fidelity twins; coupling with CAD/CAE pipelines; data governance.
- Federated and edge-distributed RL
- Sectors: IoT, Mobile, Edge AI
- Potential: Extend actor/task abstractions and GCS concepts to intermittently connected edge devices for on-device RL and aggregation.
- Dependencies: Communication-efficient updates; privacy-preserving protocols; robust synchronization under churn.
Notes on feasibility across applications:
- Performance assumptions: Achieving the cited >1M tasks/sec and millisecond latencies assumes adequate cluster sizing, network throughput, and memory for in-memory object stores.
- Programming assumptions: Stateless tasks must be idempotent with immutable objects; stateful actors need explicit checkpointing when strong recovery semantics are required.
- Ecosystem dependencies: For production model management and enterprise needs (versioning, audit, routing), integration with specialized serving/model management systems remains advisable.
- Simulator availability: Many high-impact applications depend on accurate, scalable simulators or learned environment models; their absence or low fidelity narrows what can be done immediately.
Glossary
- actor: A stateful computational entity whose methods run serially on the same state. "An actor represents a stateful computation."
- actor handle: A reference to a specific actor that can be passed around to invoke its methods remotely. "A {\em handle} to an actor can be passed to other actors or tasks"
- actor method: A remotely invocable procedure that executes on an actor’s internal state. "Actor method invocations are also represented as nodes in the computation graph."
- allreduce: A collective communication operation that aggregates values (e.g., gradients) across workers and distributes the result. "Distributed SGD typically relies on an allreduce aggregation step or a parameter server"
- Apache Arrow: A columnar, in-memory data format designed for zero-copy data interchange. "As a data format, we use Apache Arrow~\cite{arrow}."
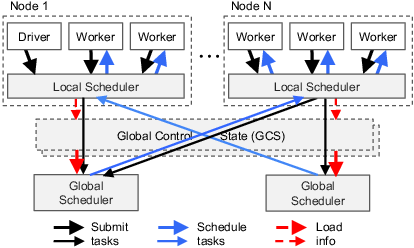
- bottom-up scheduler: A two-level scheduling approach that tries to place tasks locally first before escalating to a global scheduler. "we call it a {\em bottom-up scheduler}."
- bulk-synchronous parallel: A parallel computation model that proceeds in synchronized phases across workers. "Bulk-synchronous parallel systems such as MapReduce~\cite{mapreduce}, Apache Spark~\cite{spark-nsdi12}, and Dryad~\cite{dryad}"
- chain replication: A replication technique that arranges replicas in a chain to provide strong consistency and fault tolerance. "per-shard chain replication~\cite{chain-replication} to provide fault tolerance."
- closed-loop control: A control scenario where actions are taken based on feedback from the environment. "interactive closed-loop and open-loop control scenarios."
- computation graph: A directed graph of tasks and data dependencies that represents the execution of a program. "Actor method invocations are also represented as nodes in the computation graph."
- control edges: Edges in the computation graph that represent invocation dependencies between tasks. "Control edges capture the computation dependencies that result from nested remote functions"
- control plane: The part of a system responsible for coordination and management (as opposed to data movement). "Solid lines are data plane operations and dotted lines are control plane operations."
- control state: System metadata and lineage information used to coordinate and recover computations. "a distributed and fault-tolerant store to manage the system's control state."
- data edges: Edges in the computation graph indicating data dependencies between tasks and objects. "There are also two types of edges: data edges and control edges."
- data locality: Executing tasks near their input data to reduce transfer time. "tasks placed without data locality awareness (as is the case for actor methods)"
- data plane: The part of a system responsible for moving and storing data (as opposed to coordination). "Solid lines are data plane operations and dotted lines are control plane operations."
- data-parallel frameworks: Systems that distribute data across workers to perform parallel operations on partitions. "generic data-parallel frameworks, such as Spark~\cite{spark-nsdi12}"
- dynamic execution: Execution where the order and set of computations can change at runtime based on intermediate results. "applications require dynamic execution, as the order in which computations finish is not always known in advance"
- dynamic task graph computation model: A model where the task graph evolves during execution as new tasks are spawned. "{Ray} implements a dynamic task graph computation model"
- event-driven: A design where components react to events (e.g., messages) rather than polling or threading. "We implement both the local and global schedulers as event-driven, single-threaded processes."
- fault tolerance: The ability of a system to continue operating correctly in the presence of failures. "To achieve scalability and fault tolerance, we propose a system design principle"
- future: A placeholder object representing the result of an asynchronous computation. "Futures can be retrieved using and passed as arguments into other remote functions"
- Global Control Store (GCS): A sharded, fault-tolerant key-value store with pub-sub used to maintain system control state and lineage. "The global control store (GCS) maintains the entire control state of the system"
- heartbeat: A periodic signal used to convey liveness and status information to a scheduler. "The global scheduler gets the queue size at each node and the node resource availability via heartbeats"
- idempotence: A property of computations where repeated execution yields the same result without side effects. "This implies idempotence, which simplifies fault tolerance through function re-execution on failure."
- immutable objects: Data objects that, once created, are not modified, simplifying consistency and recovery. "Remote functions operate on immutable objects and are expected to be stateless and side-effect free"
- in-memory distributed storage: A system that stores task inputs/outputs in memory across nodes for low-latency access. "we implement an in-memory distributed storage system to store the inputs and outputs of every task"
- lineage: Metadata that records how data was produced, enabling recomputation after failures. "we track data lineage to enable reconstruction."
- local scheduler: A per-node scheduler that assigns tasks locally when possible to reduce overhead and latency. "A local scheduler schedules tasks locally unless the node is overloaded"
- LRU policy: Least Recently Used eviction policy for managing memory by discarding the least recently accessed items. "we keep objects entirely in memory and evict them as needed to disk using an LRU policy."
- metadata store: A repository for system metadata such as lineage and object directories. "a metadata store which maintains the computation lineage and a directory for data objects."
- nested remote functions: Remote functions that invoke other remote functions, enabling hierarchical parallelism. "we enable {\em nested remote functions}, meaning that remote functions can invoke other remote functions."
- object locality: Placing tasks where their required objects already reside to minimize data movement. "Support for object locality"
- object metadata: Information about data objects (e.g., locations, sizes) used for scheduling and dispatching. "we store the object metadata in the GCS rather than in the scheduler"
- object store: A per-node, shared-memory store used to keep immutable task inputs and outputs. "On each node, we implement the object store via {\em shared memory}."
- open-loop control: A control scenario where actions are issued without immediate feedback adjustments. "interactive closed-loop and open-loop control scenarios."
- parameter server: A distributed service that maintains and updates model parameters during training. "Distributed SGD typically relies on an allreduce aggregation step or a parameter server~\cite{param-server}."
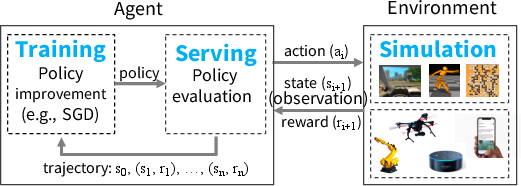
- policy (RL): A mapping from states to actions that an agent follows. "A policy is a mapping from the state of the environment to a choice of action."
- policy evaluation: Estimating how good a given policy is, often by generating trajectories. "To learn a policy, an agent typically employs a two-step process: (1) policy evaluation and (2) {\em policy improvement}."
- policy improvement: Updating a policy to perform better based on evaluation results. "To learn a policy, an agent typically employs a two-step process: (1) policy evaluation and (2) {\em policy improvement}."
- publish-subscribe (pub-sub): A communication pattern where publishers send messages to topics and subscribers receive relevant updates. "At its core, GCS is a key-value store with pub-sub functionality."
- reinforcement learning (RL): A learning paradigm where agents learn to act via trial-and-error in an environment with delayed rewards. "RL deals with learning to operate continuously within an uncertain environment based on delayed and limited feedback"
- replication-based fault tolerance: Ensuring availability by replicating critical state across nodes. "replication-based fault tolerance for the metadata store."
- rollout: Executing a policy in an environment to generate trajectories of experience. "evaluates the policy by invoking {\bf rollout}({\em environment}, {\em policy}) to generate trajectories."
- serialization and deserialization: Converting in-memory objects to/from a byte representation for communication or storage. "which typically requires serialization and deserialization."
- sharding: Partitioning data across multiple storage nodes or shards for scalability. "We use sharding to achieve scale"
- shared memory: Memory mapped for access by multiple processes on a node to avoid copying. "On each node, we implement the object store via {\em shared memory}."
- shared mutable state: State that can be updated and accessed by multiple components, often requiring careful coordination. "and expose shared mutable state to clients, (e.g., a parameter server)."
- stateful computation: Computation that maintains and updates internal state across invocations. "An actor represents a stateful computation."
- stateful edge: A dependency edge that enforces the order of operations sharing actor state. "we add a third type of edge: a stateful edge."
- stateless computation: Computation without persistent internal state across invocations. "Stateless computations can be executed on any node in the system"
- stochastic gradient descent (SGD): An iterative optimization algorithm that updates parameters using random mini-batches. "Training typically involves running stochastic gradient descent (SGD), often in a distributed setting"
- straggler mitigation: Techniques to reduce the impact of slow-running tasks on overall job completion time. "straggler mitigation, query optimization"
- task dispatch: The process of sending tasks to execution locations and retrieving their inputs. "task dispatch, which involves retrieving remote inputs from other nodes."
- task-parallel: A computation model emphasizing parallel execution of independent tasks. "task-parallel computations"
- trajectory (RL): A sequence of states (and rewards) generated by following a policy. "where a trajectory consists of a sequence of (state, reward) tuples"
- two-level hierarchical scheduler: A scheduling architecture with per-node local schedulers and a global scheduler. "we design a two-level hierarchical scheduler consisting of a global scheduler and per-node local schedulers."
- TPU (Tensor Processing Unit): Specialized hardware for accelerating machine learning workloads. "These frameworks often leverage specialized hardware (e.g., GPUs and TPUs), with the goal of reducing training time in a batch setting."
- work stealing: A distributed scheduling technique where idle workers take tasks from busy workers’ queues. "Distributed schedulers such as work stealing~\cite{work-stealing}"
- zero-copy: Data sharing without memory copies, improving performance. "This allows zero-copy data sharing between tasks running on the same node."
- driver: The process that runs the user program and submits tasks. "{\em Driver}: A process executing the user program."
- worker: A stateless process that executes remote functions assigned by the scheduler. "{\em Worker}: A stateless process that executes tasks (remote functions)"
Collections
Sign up for free to add this paper to one or more collections.