- The paper reveals that membership inference attacks can exploit ML model overfitting to leak sensitive training data.
- It utilizes shadow model training and supervised learning to emulate target model behavior for effective attack model construction.
- Experimental evaluations on commercial APIs highlight vulnerabilities, prompting defenses like output restriction, regularization, and differential privacy.
Membership Inference Attacks Against Machine Learning Models
Membership inference attacks exploit the vulnerability of machine learning models to deduce whether a specific data record was part of the training dataset. This paper provides a comprehensive exploration of such attacks, particularly in the black-box setting, and their application against commercial machine learning-as-a-service platforms like Google and Amazon.
Attack Methodology
The core of the membership inference attack lies in the adversarial use of machine learning itself. An attack model is trained to identify whether a target model's behavior on a certain input indicates that the input was part of its training dataset. Advanced techniques such as shadow model training and various data synthesis methods form the backbone of such attacks.
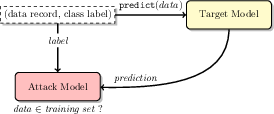
Figure 1: Membership inference attack in the black-box setting. The attacker queries the target model to infer if a record was part of the training dataset.
Shadow Models and Attack Model Training
Shadow models are replicas of the target model, trained independently with known datasets to simulate the target model's behavior. The attack model is then trained on the observed behavior of these shadow models. This process involves querying shadow models with both their training data (labeled as "in") and a separate test dataset (labeled as "out").
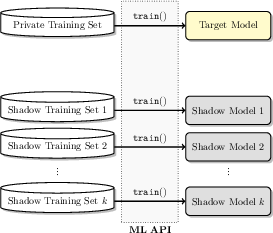
Figure 2: Training shadow models using disjoint datasets to mimic target model behavior.
The attack model is refined through supervised learning on this dataset, allowing it to infer membership with high accuracy in the target model's training dataset.
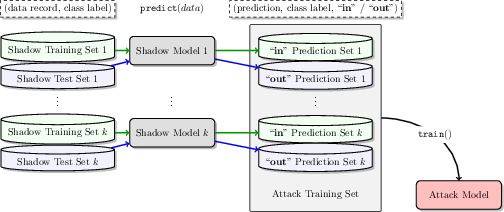
Figure 3: Training the attack model using the labeled dataset created from shadow models' outputs.
Experimental Evaluation
The efficacy of membership inference attacks was demonstrated on several real-world datasets using both neural networks and cloud-based services. The attack yielded considerable success, with precision and recall verifying its reliability. For instance, models trained with commercial platforms like Google's and Amazon's APIs showed significant leakage of training data.
Factors Affecting Attack Success
The attack's success is contingent on several factors:
- Overfitting: Models that are not well-generalized tend to leak more information.
- Model Structure: Different model architectures exhibit varying degrees of information retention from their training data.
- Training Data Diversity: The heterogeneity of data within each class influences the attack's precision.
Mitigation Strategies
Several defense mechanisms were evaluated to curb membership inference:
- Restricting Output Information: Limiting the prediction output to top-k class probabilities can reduce leakage risk.
- Regularization: Regularization during model training reduces overfitting, thus mitigating potential data leakage.
- Differential Privacy: Implementing differential privacy frameworks helps ensure the indistinguishability of individual data records in the training set.
Conclusion
Membership inference attacks underscore the privacy vulnerabilities inherent in machine learning models, especially in situations where access is solely black-box. Addressing these vulnerabilities requires robust model training practices that prioritize data privacy while maintaining predictive accuracy. This research paves the way for refining privacy-preserving techniques and enhancing the security profile of machine learning applications, especially in scenarios involving sensitive data like healthcare records.