- The paper presents two novel methods, RIAL and DIAL, that empower agents to learn communication protocols in partially observable settings.
- It demonstrates that parameter sharing and gradient propagation significantly enhance coordinated performance in tasks like the Switch Riddle and MNIST games.
- The work highlights how differentiable communication reduces reliance on trial-and-error, offering insights into language evolution in AI systems.
Learning to Communicate with Deep Multi-Agent Reinforcement Learning
Introduction
The paper "Learning to Communicate with Deep Multi-Agent Reinforcement Learning" (1605.06676) addresses the complex problem of enabling multiple agents to sense and act in environments, thereby maximizing shared utility through effective communication protocols. The study introduces two innovative approaches: Reinforced Inter-Agent Learning (RIAL) and Differentiable Inter-Agent Learning (DIAL), which utilize deep neural networks to facilitate end-to-end learning of communication protocols in environments characterized by partial observability.
In the context of deep multi-agent reinforcement learning (MARL), the agents must autonomously develop and agree upon effective communication strategies to solve cooperative tasks. Such tasks impose challenges due to partial observability and the necessity for coordinated communication across agents operating under decentralized execution constraints.
Problem Setting
The paper explores sequential decision-making problems involving multiple agents in partially observable environments. Each agent receives private observations that are only correlated with the underlying Markov state. Communication is facilitated through a discrete limited-bandwidth channel, compelling agents to discover a protocol that sufficiently supports behavior coordination to solve the task.
Centralized learning but decentralized execution is emphasized, making this paradigm relevant for practical applications such as training robotic teams in simulators. The paper also briefly reviews decentralized learning baselines to provide a comprehensive perspective on the MARL setting.
Methods
Reinforced Inter-Agent Learning (RIAL)
RIAL integrates deep Q-learning with a recurrent network to confront partial observability challenges. The method supports independent or shared parameter learning approaches, where the latter reduces the parameter space and speeds up learning significantly. Importantly, execution remains decentralized, maintaining robust performance across diverse observational inputs leading to action differentiation among agents.
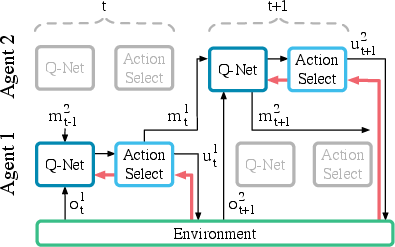
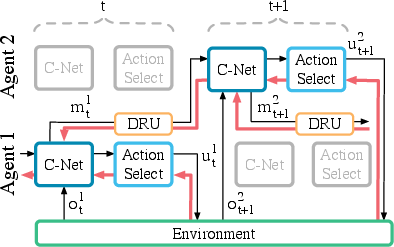
Figure 1: RIAL - RL based communication
Differentiable Inter-Agent Learning (DIAL)
DIAL offers enhanced learning opportunities by leveraging centralised learning, allowing gradients to propagate across agents through communication channels. During learning phases, agents are permitted to exchange real-valued messages, subsequently discretizing these exchanges for actual task execution. This gradient-based communication endows agents with richer feedback, reducing reliance on trial-and-error exploration and facilitating the discovery of effective protocols.
This innovative approach makes DIAL uniquely suitable for scenarios requiring communication across complex environments, advocating its inherent deep learning foundation.
Experiments and Results
The paper provides empirical evaluation of RIAL and DIAL across newly proposed environments and challenges, including the Switch Riddle and MNIST Games—with RIAL and DIAL outperforming baseline methods.
Switch Riddle
The Switch Riddle task demonstrates the capability of agents to coordinate under limited communication windows, with parameter sharing proving critical in achieving optimal performance, especially as agent numbers increase.
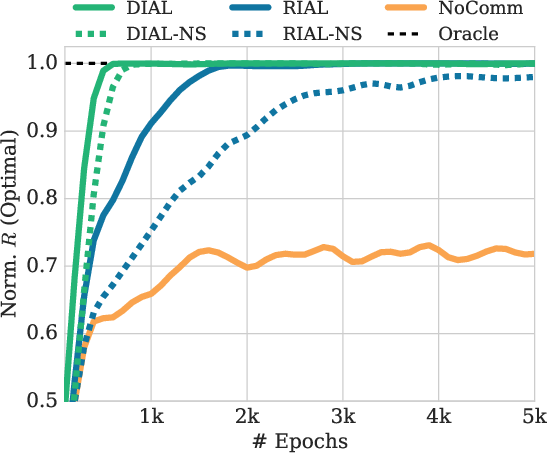
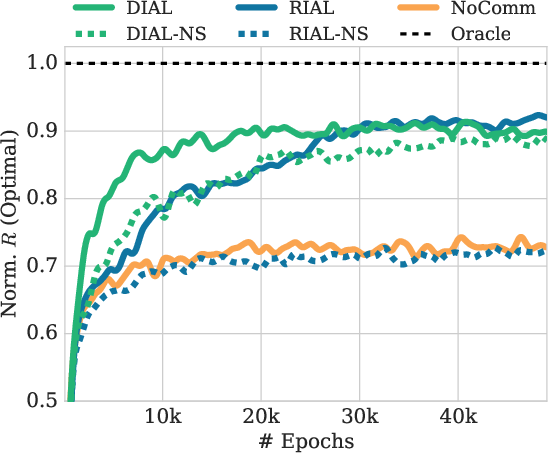
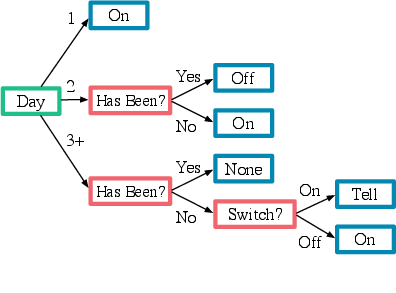
Figure 2: Evaluation of n=3
MNIST Games
The Color-Digit MNIST and Multi-Step MNIST games further validate DIAL's effectiveness, showcasing its superior ability to optimize message content compared to RIAL. The experiments also underline the role of differentiable communication in addressing stochastic reward functions, emphasizing DIAL's advantage in multi-step information integration.
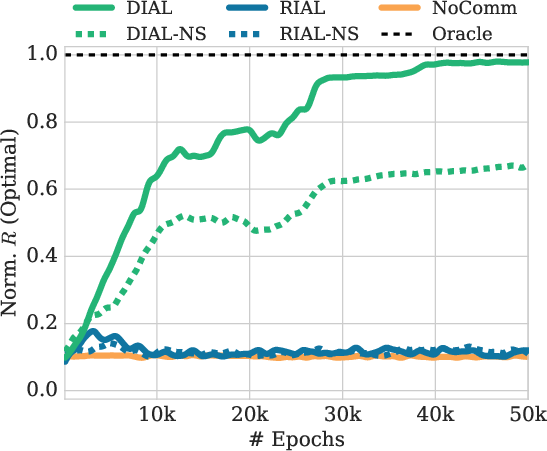
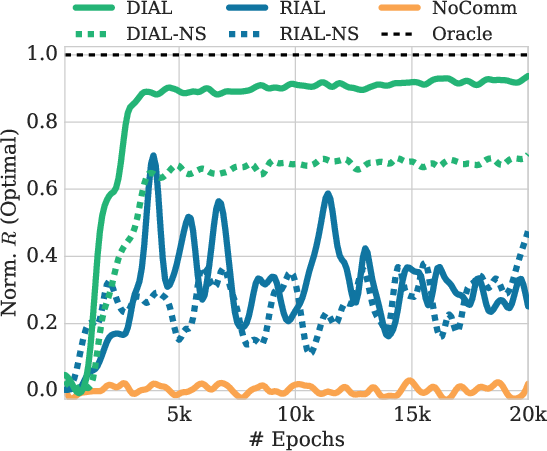
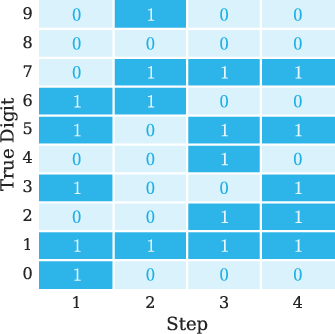
Figure 3: Evaluation of Multi-Step
Effect of Noise
The analysis reflects on how language evolved into discrete forms, supported by observations that noise in DIAL's communication channels necessitates message discretization during learning phases. This concept provides intriguing insights into language evolution within human and artificial contexts.
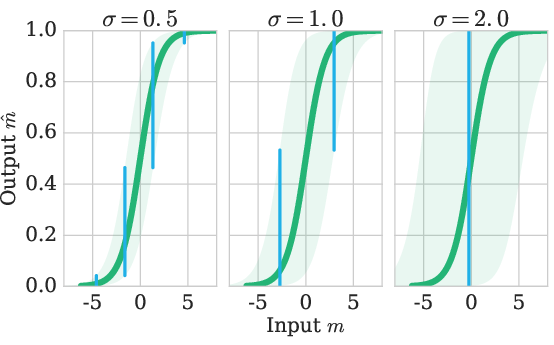
Figure 4: Distribution of regularised messages, P(m^∣m) for different noise levels. Shading indicates P(m^∣m)>0.1. Blue bars show a division of the x-range into intervals s.t.\ the resulting y-values have a small probability of overlap, leading to decodable values.
Conclusion
The paper contributes novel environments and methodologies for learning communication protocols, advancing differentiated communication channels under deep MARL paradigms. It emphasizes key factors impacting the learning process, including architecture design, parameter sharing, and gradient propagation across agents.
The study represents a promising step towards unraveling communication and language learning within AI systems, establishing ground for addressing broader communication and compositionality challenges in AI agent coordination.
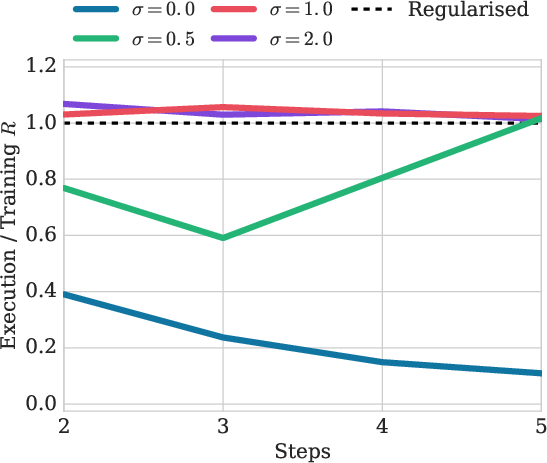
Figure 5: Final evaluation performance on multi-step MNIST of DIAL normalised by training performance after 50K epochs, under different noise regularisation levels σ∈{0,0.5,1,1.5,2}