- The paper presents a novel benchmark for evaluating action recognition in realistic, untrimmed videos.
- It details the use of multi-label classification and advanced feature pooling techniques, combining iDT and CNN-based features.
- The findings highlight both improvements in performance and ongoing challenges in addressing background clutter and visually similar actions.
The THUMOS Challenge on Action Recognition for Videos "in the Wild"
The THUMOS Challenge aimed to advance the evaluation and exploration of video action recognition methods using large-scale datasets gathered from diverse, uncontrolled environments. Through the curation of temporally untrimmed videos from the THUMOS dataset, this benchmark established two primary tasks: action classification and temporal detection for a wide array of action classes. This essay provides a comprehensive summary of the dataset's structure, annotation processes, challenge tasks, and findings, alongside comparisons with existing datasets.
Introduction
Action recognition in video has gained considerable attention, bolstered by datasets such as UCF101 and HMDB. Traditional action recognition research focused on trimmed videos, providing clearly marked action boundaries, which simplifies the task of temporal detection. However, such scenarios are idealized and rarely encountered in real-world applications where actions are embedded in complex and noisy backgrounds.
THUMOS began as a challenge in 2013, initially focusing on action recognition in trimmed videos using the UCF101 dataset. It has since evolved to address realistic challenges by incorporating untrimmed videos into its datasets, thus providing a true representation of "in the wild" action recognition settings—comprising both action instances and background clutter.
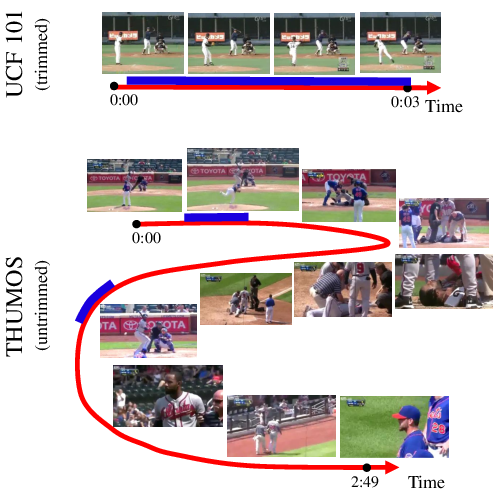
Figure 1: Illustration contrasting a (trimmed) video clip for the `BaseballPitch' action from the UCF101 dataset and an untrimmed video from the THUMOS'15 validation set.
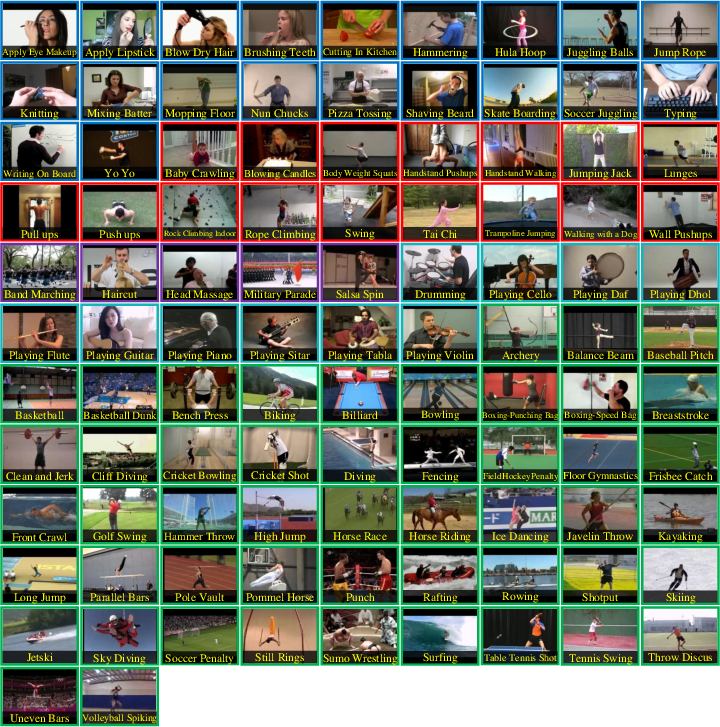
Figure 2: The figure shows the sample frames of the actions from UCF101 dataset~\cite{Soomro12}.
For THUMOS'15, the classification objective was extended to involve multi-label binary tasks, distinguishing videos with action, multiple actions, or no action. This adjusts the focus from multi-class trimmed clips to a more complex environment seen in real-world settings, amplified by features like background videos and untrimmed formats (Figure 1). The broader spectrum of tasks has been significant in advancing action recognition technology.
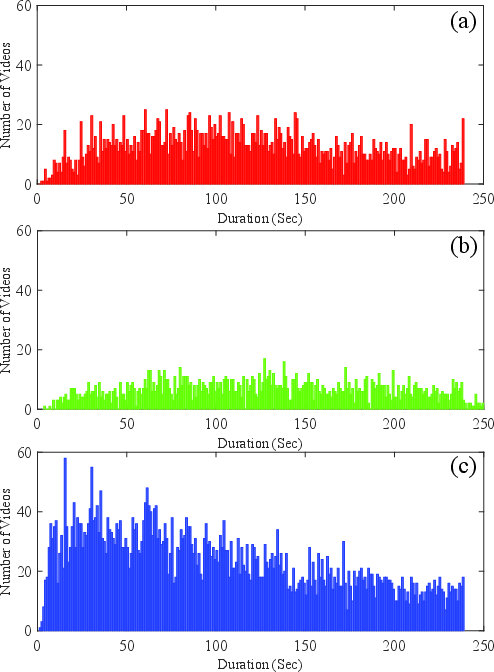
Figure 3: Histogram of video lengths in THUMOS'15: (a) Background, (b) Validation, and (c) Test set respectively with exclusion of videos exceeding 250 seconds.
\section{Methodological Approaches and Performance Metrics}
In the classification task, most teams pursued a combination of iDT features and CNN-derived features, using state-of-the-art models like VGGNet and GoogleNet (Table 1). Both mean and max pooling strategies were used to transform frame-level features into video-level representations, with results showing minor performance differences between the two.
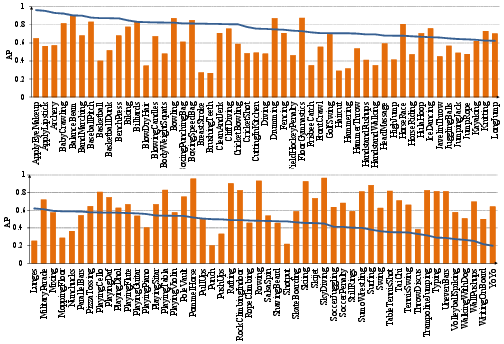
Figure 4: Per-action results, measured by AP: The bars depict the AP for each action.
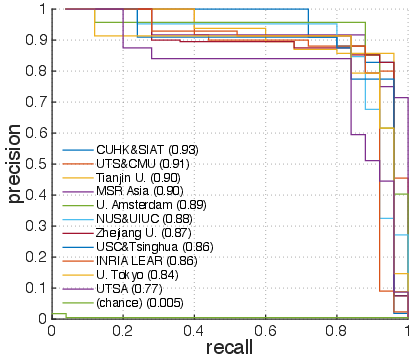
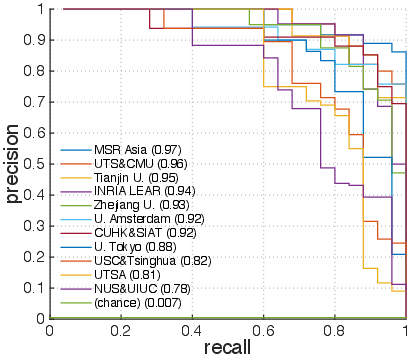
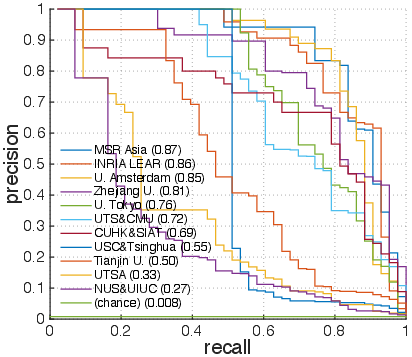
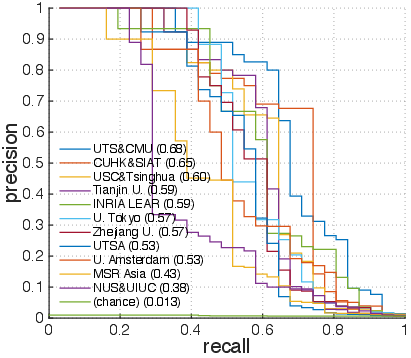
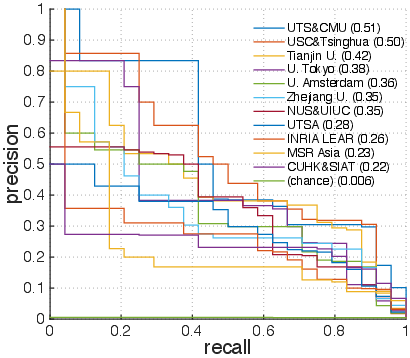
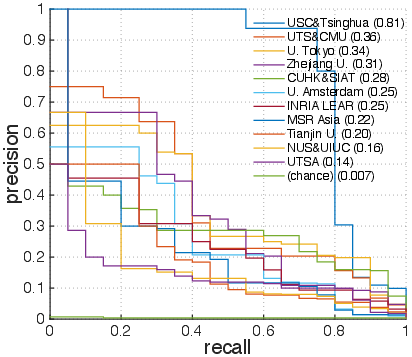
Figure 5: Precision-recall curves for classes Bowling',Surfing', CricketBowling',PlayingGuitar', BlowDryHair', andHaircut'.
Examining per-action results (Figure 4) shows that action classes like Bowling' andSurfing' achieve fairly high precision and recall, while classes such as BlowDryHair' andHaircut' remain challenging due to visual similarity. The introduction of background videos also provided insights into their impact, as depicted in the differences between blue and red histograms (Figure 6). Challenges with distinguishing certain actions in the presence of visually similar background contexts hint at future directions for more robust feature extraction and fusion approaches.
Figure 2: Precision-recall curves of classes with varying AP values, including Bowling',Surfing', CricketBowling',PlayingGuitar', BlowDryHair', andHaircut'.
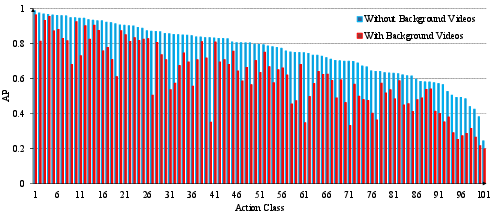
Figure 6: Effect of background videos: Blue histogram represents results without the background videos, and red histogram plots results including the background videos. Results are sorted based on the former.
\section{Future Directions and Improvements}
The THUMOS challenge has significantly contributed to the standardization of datasets and evaluation protocols in the video action recognition domain. Future improvements could focus on expanding the dataset to include more refined annotations, such as spatial and temporal annotations, action attributes, and richer context features. With the increasing role of deep learning techniques in video analysis, future work may involve exploring more sophisticated deep learning methodologies, advanced feature pooling methods, and techniques for dealing with occlusion and temporal clutter. There is also a growing interest in leveraging implicit context features from untrimmed videos to improve the performance of action recognition further.
\section{Conclusion}
The THUMOS Challenge has played an essential role in advancing the research of action recognition in videos from uncontrolled environments. By providing large-scale and publicly available datasets of untrimmed internet videos, it serves as a valuable resource for benchmarking and promoting state-of-the-art approaches in realistic scenarios. The challenge has already demonstrated its effectiveness in driving improvements in action recognition and situated the problem of recognizing actions in complex videos at the forefront of research. Despite achieving significant gains in recognition performance, the challenge remains open in coming up with novel and computationally efficient techniques that can tackle temporal detection effectively. Future iterations aim to tackle even more complex scenarios such as weakly supervised temporal action detection and video understanding in unconstrained environments, thus continuing to guide the extensive research in the field of video action recognition.

